World Models That Know When They Don't Know: Controllable Video Generation with Calibrated Uncertainty
作者: Zhiting Mei, Tenny Yin, Micah Baker, Ola Shorinwa, Anirudha Majumdar
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-12-05
💡 一句话要点
提出C3方法,用于训练可控视频生成模型,使其具备校准的不确定性估计能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 可控视频生成 不确定性量化 机器人学习 世界模型 深度学习
📋 核心要点
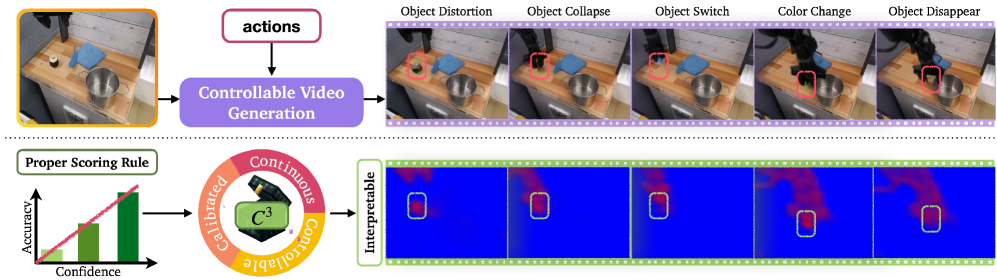
- 现有可控视频生成模型易产生幻觉,缺乏置信度评估能力,限制了其在机器人等领域的应用。
- C3方法通过在潜在空间进行不确定性估计,并结合严格的评分规则进行训练,实现校准的不确定性量化。
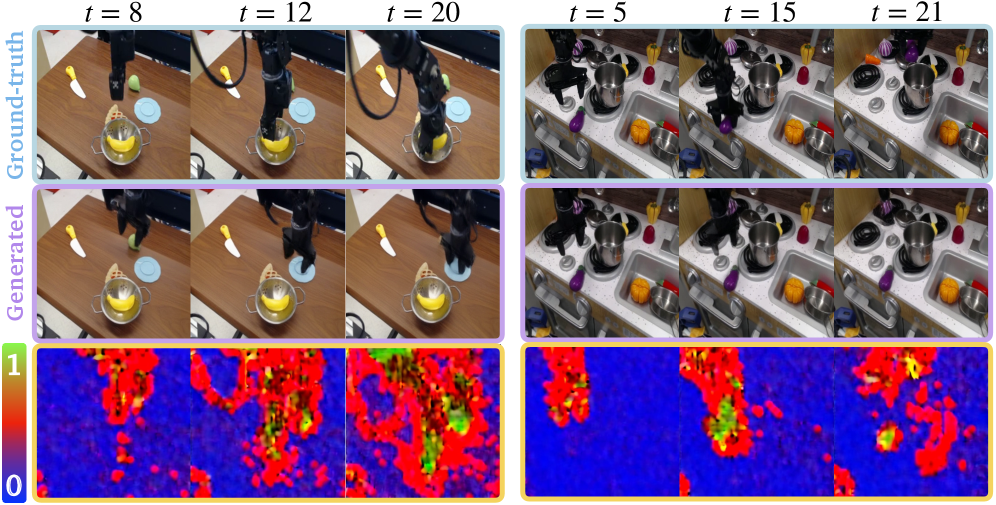
- 实验表明,C3方法不仅能提供校准的不确定性估计,还能有效检测训练分布之外的数据。
📝 摘要(中文)
近年来,生成式视频模型在高质量视频合成方面取得了显著进展,尤其是在可控视频生成领域,生成的视频以文本和动作输入为条件,例如在指令引导的视频编辑和机器人技术中的世界建模。尽管这些模型具有卓越的能力,但可控视频模型经常产生幻觉——生成与物理现实不符的未来视频帧——这在机器人策略评估和规划等许多任务中引起了严重关注。然而,最先进的视频模型缺乏评估和表达其置信度的能力,阻碍了幻觉的缓解。为了严格应对这一挑战,我们提出了一种不确定性量化(UQ)方法C3,用于训练连续尺度校准的可控视频模型,以在子补丁级别进行密集置信度估计,精确地定位每个生成的视频帧中的不确定性。我们的UQ方法引入了三个核心创新,使视频模型能够估计其不确定性。首先,我们的方法开发了一个新颖的框架,通过严格的适当评分规则训练视频模型以保证正确性和校准。其次,我们在潜在空间中估计视频模型的不确定性,避免了与像素空间方法相关的训练不稳定性和过高的训练成本。第三,我们将密集的潜在空间不确定性映射到RGB空间中可解释的像素级不确定性,以进行直观的可视化,从而提供高分辨率的不确定性热图,以识别不可信的区域。通过在大型机器人学习数据集(Bridge和DROID)和真实世界评估中进行的大量实验,我们证明了我们的方法不仅在训练分布内提供校准的不确定性估计,而且能够实现有效的分布外检测。
🔬 方法详解
问题定义:论文旨在解决可控视频生成模型中存在的“幻觉”问题,即生成的视频帧与物理现实不符。现有方法缺乏对自身预测结果的置信度评估,难以区分可靠和不可靠的生成内容,限制了其在机器人策略评估、规划等安全攸关领域的应用。
核心思路:论文的核心思路是为可控视频生成模型引入不确定性量化(Uncertainty Quantification, UQ)机制,使其能够评估并表达自身预测的置信度。通过训练模型,使其不仅能生成视频帧,还能同时预测每个像素级别的不确定性,从而识别出可能存在幻觉的区域。
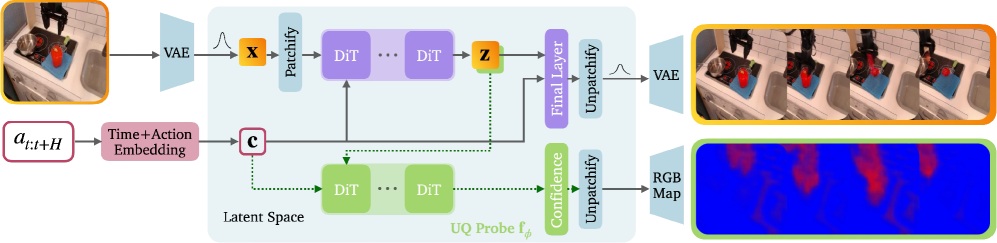
技术框架:C3方法的技术框架主要包含以下几个阶段:1) 视频生成模型训练:使用可控视频生成模型(具体模型未明确说明,但可以是常见的VAE或GAN变体)生成视频帧。2) 潜在空间不确定性估计:在视频生成模型的潜在空间中估计不确定性,避免直接在像素空间进行计算,降低计算成本和训练难度。3) 不确定性校准:使用严格的适当评分规则(strictly proper scoring rules)训练模型,使其预测的不确定性与实际误差相匹配,实现校准。4) 不确定性映射:将潜在空间的不确定性映射到RGB像素空间,生成高分辨率的不确定性热图,用于可视化和解释。
关键创新:C3方法的关键创新在于:1) 基于严格评分规则的不确定性校准:通过优化评分规则,确保模型预测的不确定性能够准确反映其预测误差。2) 在潜在空间进行不确定性估计:避免了像素空间计算的复杂性和不稳定性,提高了训练效率和模型性能。3) 像素级不确定性可视化:将不确定性映射到像素级别,方便用户理解和利用,例如用于识别不可靠的生成区域。
关键设计:论文的关键设计包括:1) 评分规则的选择:选择合适的严格适当评分规则,例如连续排序概率分数(Continuous Ranked Probability Score, CRPS),用于训练模型的不确定性估计。2) 潜在空间不确定性表示:设计合适的潜在空间不确定性表示方法,例如使用高斯分布的方差来表示不确定性。3) 潜在空间到像素空间的映射:设计有效的映射函数,将潜在空间的不确定性转化为像素级别的热图。
🖼️ 关键图片
📊 实验亮点
实验结果表明,C3方法在Bridge和DROID等机器人学习数据集上取得了显著效果。该方法不仅能够提供校准的不确定性估计,而且能够有效检测分布外数据。通过可视化不确定性热图,可以清晰地识别出生成视频中存在幻觉的区域,为后续的修复和改进提供了依据。
🎯 应用场景
该研究成果可广泛应用于机器人、自动驾驶、视频编辑等领域。例如,在机器人领域,可以帮助机器人识别不可靠的感知信息,提高决策的安全性;在自动驾驶领域,可以用于评估场景理解的置信度,避免因错误感知导致的事故;在视频编辑领域,可以辅助用户识别和修复生成视频中的幻觉。
📄 摘要(原文)
Recent advances in generative video models have led to significant breakthroughs in high-fidelity video synthesis, specifically in controllable video generation where the generated video is conditioned on text and action inputs, e.g., in instruction-guided video editing and world modeling in robotics. Despite these exceptional capabilities, controllable video models often hallucinate - generating future video frames that are misaligned with physical reality - which raises serious concerns in many tasks such as robot policy evaluation and planning. However, state-of-the-art video models lack the ability to assess and express their confidence, impeding hallucination mitigation. To rigorously address this challenge, we propose C3, an uncertainty quantification (UQ) method for training continuous-scale calibrated controllable video models for dense confidence estimation at the subpatch level, precisely localizing the uncertainty in each generated video frame. Our UQ method introduces three core innovations to empower video models to estimate their uncertainty. First, our method develops a novel framework that trains video models for correctness and calibration via strictly proper scoring rules. Second, we estimate the video model's uncertainty in latent space, avoiding training instability and prohibitive training costs associated with pixel-space approaches. Third, we map the dense latent-space uncertainty to interpretable pixel-level uncertainty in the RGB space for intuitive visualization, providing high-resolution uncertainty heatmaps that identify untrustworthy regions. Through extensive experiments on large-scale robot learning datasets (Bridge and DROID) and real-world evaluations, we demonstrate that our method not only provides calibrated uncertainty estimates within the training distribution, but also enables effective out-of-distribution detection.