SCAIL: Towards Studio-Grade Character Animation via In-Context Learning of 3D-Consistent Pose Representations
作者: Wenhao Yan, Sheng Ye, Zhuoyi Yang, Jiayan Teng, ZhenHui Dong, Kairui Wen, Xiaotao Gu, Yong-Jin Liu, Jie Tang
分类: cs.CV
发布日期: 2025-12-05 (更新: 2026-02-02)
💡 一句话要点
SCAIL:通过3D一致姿态表示的上下文学习实现工作室级角色动画
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 角色动画 3D姿态表示 上下文学习 扩散模型 Transformer 时空推理 运动迁移
📋 核心要点
- 现有方法在复杂场景下进行角色动画时,难以保持结构保真度和时间一致性,限制了其应用。
- SCAIL通过新颖的3D姿态表示和全上下文姿态注入机制,增强了时空推理能力,提升动画质量。
- 实验结果表明,SCAIL在角色动画方面取得了最先进的性能,更接近工作室级的制作标准。
📝 摘要(中文)
本文提出SCAIL(通过上下文学习实现工作室级角色动画的框架),旨在解决现有方法在复杂运动和跨身份动画场景中,难以保持结构保真度和时间一致性的问题。SCAIL框架包含两项关键创新:一是提出了一种新颖的3D姿态表示,提供更鲁棒和灵活的运动信号;二是在扩散-Transformer架构中引入了全上下文姿态注入机制,从而能够对完整运动序列进行有效的时空推理。为了满足工作室级别的要求,我们开发了一个精心策划的数据管道,确保多样性和质量,并建立了一个全面的基准用于系统评估。实验表明,SCAIL实现了最先进的性能,并推动角色动画朝着工作室级的可靠性和真实感发展。
🔬 方法详解
问题定义:现有角色动画方法在处理复杂运动和跨身份动画时,难以保证生成动画的结构保真度和时间一致性。尤其是在“wild scenarios”下,动画效果与工作室级的制作标准存在差距。现有方法的痛点在于对运动信号的表示不够鲁棒和灵活,以及缺乏有效的时空推理机制。
核心思路:SCAIL的核心思路是利用一种新的3D姿态表示方法,更准确地捕捉和传递运动信息,并结合全上下文姿态注入机制,增强模型对整个运动序列的时空理解能力。通过这种方式,模型能够更好地理解和生成符合物理规律和时间连贯性的角色动画。
技术框架:SCAIL框架基于扩散-Transformer架构。首先,使用提出的3D姿态表示方法对输入视频进行编码,提取运动信息。然后,通过全上下文姿态注入机制,将这些运动信息融入到Transformer中,进行时空推理。最后,利用扩散模型生成最终的角色动画。整个框架旨在实现从驱动视频到参考图像的运动迁移,同时保持结构保真度和时间一致性。
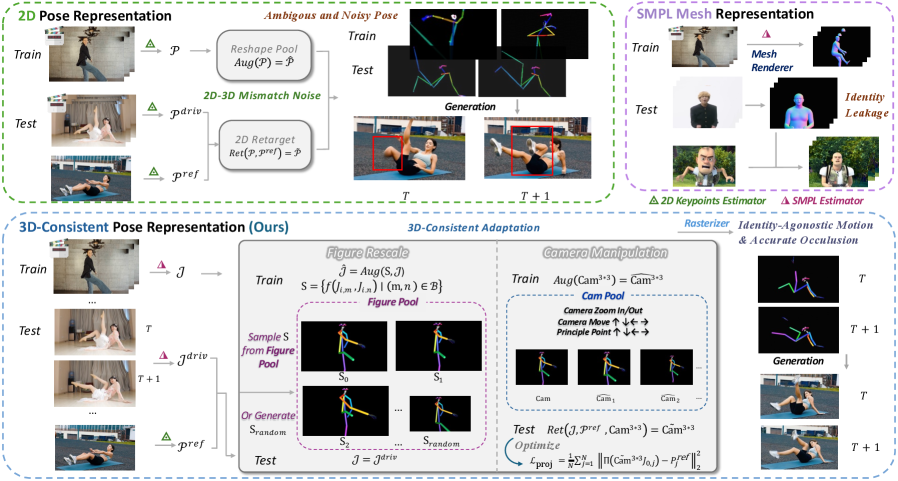
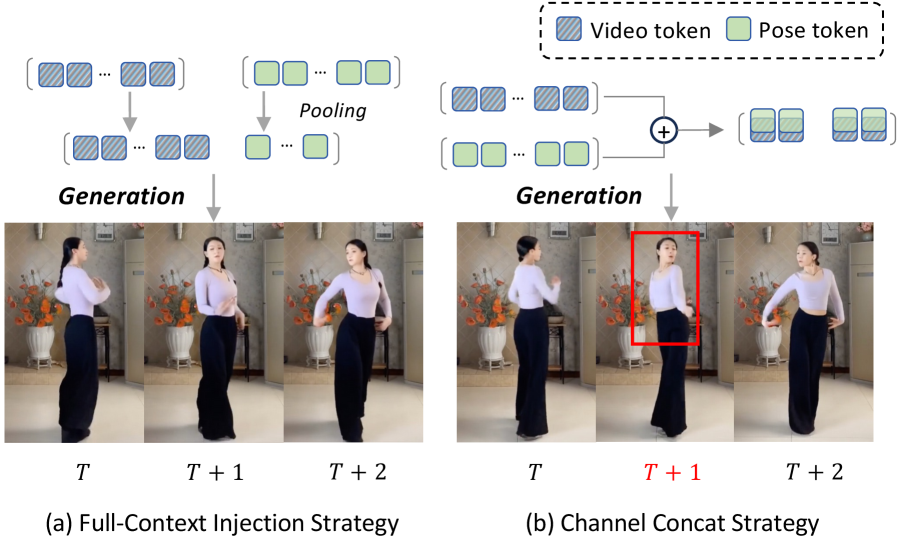
关键创新:SCAIL的关键创新在于两个方面:一是提出了新颖的3D姿态表示方法,这种表示方法更鲁棒、更灵活,能够更好地捕捉和传递运动信息;二是引入了全上下文姿态注入机制,这种机制能够让模型更好地理解整个运动序列的时空关系,从而生成更连贯、更自然的动画。
关键设计:3D姿态表示的具体形式未知,但强调了其鲁棒性和灵活性。全上下文姿态注入机制的具体实现方式未知,但其目的是增强模型对时空信息的理解。数据管道的设计注重多样性和质量,以满足工作室级别的要求。损失函数和网络结构的具体细节未知,但整体架构是基于扩散-Transformer模型。
🖼️ 关键图片

📊 实验亮点
SCAIL在角色动画任务上取得了state-of-the-art的性能,表明其在结构保真度和时间一致性方面优于现有方法。论文强调了SCAIL能够推动角色动画朝着工作室级的可靠性和真实感发展,但没有提供具体的性能数据或对比基线。
🎯 应用场景
SCAIL技术可广泛应用于电影、游戏、虚拟现实等领域,提升角色动画的制作效率和质量。它能够帮助动画师快速生成高质量的角色动画,降低制作成本,并为用户提供更逼真、更具沉浸感的体验。未来,该技术有望进一步发展,实现更智能、更自动化的角色动画生成。
📄 摘要(原文)
Achieving character animation that meets studio-grade production standards remains challenging despite recent progress. Existing approaches can transfer motion from a driving video to a reference image, but often fail to preserve structural fidelity and temporal consistency in wild scenarios involving complex motion and cross-identity animations. In this work, we present \textbf{SCAIL} (a framework toward \textbf{S}tudio-grade \textbf{C}haracter \textbf{A}nimation via \textbf{I}n-context \textbf{L}earning), a framework designed to address these challenges from two key innovations. First, we propose a novel 3D pose representation, providing a more robust and flexible motion signal. Second, we introduce a full-context pose injection mechanism within a diffusion-transformer architecture, enabling effective spatio-temporal reasoning over full motion sequences. To align with studio-level requirements, we develop a curated data pipeline ensuring both diversity and quality, and establish a comprehensive benchmark for systematic evaluation. Experiments show that \textbf{SCAIL} achieves state-of-the-art performance and advances character animation toward studio-grade reliability and realism.