Probing the effectiveness of World Models for Spatial Reasoning through Test-time Scaling
作者: Saurav Jha, M. Jehanzeb Mirza, Wei Lin, Shiqi Yang, Sarath Chandar
分类: cs.CV, cs.AI
发布日期: 2025-12-05
备注: Extended abstract at World Modeling Workshop 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出ViSA框架,通过空间断言改进世界模型在空间推理中的测试时缩放效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 空间推理 世界模型 视觉-语言模型 测试时缩放 空间断言 具身智能 多视角理解
📋 核心要点
- 现有的视觉-语言模型在多视角空间推理任务中表现不足,尤其是在具身视角转换方面。
- 论文提出Verification through Spatial Assertions (ViSA)框架,通过可验证的空间断言来提升测试时验证的可靠性。
- ViSA在SAT-Real基准上提升了空间推理性能,并纠正了轨迹选择偏差,但在MMSI-Bench上仍面临挑战。
📝 摘要(中文)
视觉-语言模型(VLMs)在需要多视角理解和具身视角转换的空间推理任务中仍然存在局限性。MindJourney等最新方法试图通过测试时缩放来弥补这一差距,即世界模型想象动作条件轨迹,启发式验证器从这些轨迹中选择有用的视图。本文系统地研究了这种测试时验证器在基准测试中的行为,揭示了它们的潜力和缺陷。基于不确定性的分析表明,MindJourney的验证器提供的校准意义不大,随机评分通常也能同样有效地降低答案熵,从而暴露了系统性的动作偏差和不可靠的奖励信号。为了缓解这些问题,我们引入了一个通过空间断言进行验证(ViSA)的框架,该框架将测试时奖励建立在可验证的、帧锚定的微声明之上。这种基于原则的验证器持续改进了SAT-Real基准上的空间推理,并通过更平衡的探索行为纠正了轨迹选择偏差。然而,在具有挑战性的MMSI-Bench上,包括我们的验证器在内的所有验证器都未能实现一致的缩放,这表明当前的世界模型形成了一个信息瓶颈,想象的视图未能丰富细粒度的推理。总之,这些发现描绘了基于世界模型的推理的测试时验证的好、坏和丑陋的方面。
🔬 方法详解
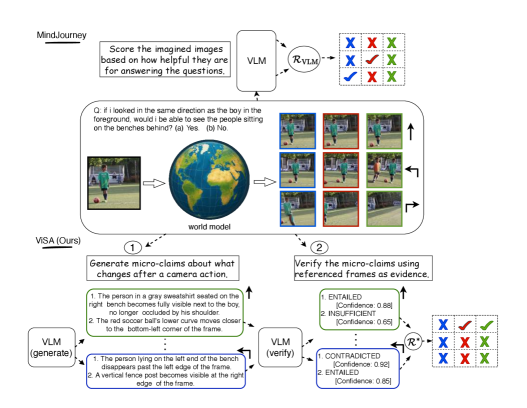
问题定义:论文旨在解决视觉-语言模型在空间推理任务中,由于缺乏多视角理解和视角转换能力而导致的性能瓶颈。现有方法,如MindJourney,虽然尝试通过测试时缩放和启发式验证来解决这个问题,但其验证器存在校准不足、动作偏差和奖励信号不可靠等问题。
核心思路:论文的核心思路是通过引入基于空间断言的验证机制,将测试时的奖励信号与可验证的、帧锚定的微声明联系起来,从而提高验证器的可靠性和准确性。这种方法旨在减少动作偏差,并鼓励更平衡的探索行为。
技术框架:ViSA框架的核心在于使用空间断言来评估世界模型生成的轨迹。该框架包含以下主要模块:1) 世界模型:用于生成动作条件轨迹;2) 空间断言模块:用于生成和验证帧锚定的微声明,这些微声明描述了场景中物体之间的空间关系;3) 奖励函数:基于空间断言的验证结果,为每个轨迹分配奖励;4) 轨迹选择器:根据奖励选择最佳轨迹。
关键创新:ViSA的关键创新在于使用空间断言作为验证的依据。与传统的启发式验证器相比,空间断言提供了更明确、可验证的信号,从而减少了主观性和偏差。此外,ViSA框架通过平衡探索行为,避免了对特定动作的过度依赖。
关键设计:空间断言模块的设计是ViSA框架的关键。该模块需要能够生成描述场景中物体之间空间关系的微声明,并验证这些声明的真伪。具体的实现方式可能包括使用预训练的视觉-语言模型来生成和验证断言,或者使用专门设计的空间关系检测器。奖励函数的设计也至关重要,需要能够准确地反映轨迹的质量,并鼓励探索不同的视角和动作。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ViSA框架在SAT-Real基准上显著提升了空间推理性能,并有效纠正了轨迹选择偏差。与MindJourney相比,ViSA能够生成更平衡的探索行为,并获得更准确的奖励信号。然而,在更具挑战性的MMSI-Bench上,ViSA和其他验证器均未能实现一致的缩放,表明当前世界模型存在信息瓶颈。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域,提升智能体在复杂环境中的空间理解和推理能力。通过更可靠的测试时验证,可以提高智能体在未知环境中的适应性和鲁棒性,使其能够更好地完成各种任务,例如搜索、救援、探索等。
📄 摘要(原文)
Vision-Language Models (VLMs) remain limited in spatial reasoning tasks that require multi-view understanding and embodied perspective shifts. Recent approaches such as MindJourney attempt to mitigate this gap through test-time scaling where a world model imagines action-conditioned trajectories and a heuristic verifier selects helpful views from such trajectories. In this work, we systematically examine how such test-time verifiers behave across benchmarks, uncovering both their promise and their pitfalls. Our uncertainty-based analyses show that MindJourney's verifier provides little meaningful calibration, and that random scoring often reduces answer entropy equally well, thus exposing systematic action biases and unreliable reward signals. To mitigate these, we introduce a Verification through Spatial Assertions (ViSA) framework that grounds the test-time reward in verifiable, frame-anchored micro-claims. This principled verifier consistently improves spatial reasoning on the SAT-Real benchmark and corrects trajectory-selection biases through more balanced exploratory behavior. However, on the challenging MMSI-Bench, none of the verifiers, including ours, achieve consistent scaling, suggesting that the current world models form an information bottleneck where imagined views fail to enrich fine-grained reasoning. Together, these findings chart the bad, good, and ugly aspects of test-time verification for world-model-based reasoning. Our code is available at https://github.com/chandar-lab/visa-for-mindjourney.