Fast SceneScript: Accurate and Efficient Structured Language Model via Multi-Token Prediction
作者: Ruihong Yin, Xuepeng Shi, Oleksandr Bailo, Marco Manfredi, Theo Gevers
分类: cs.CV
发布日期: 2025-12-05
备注: 10 pages, 8 figures
💡 一句话要点
Fast SceneScript:通过多Token预测实现精确高效的结构化语言模型,用于3D场景布局估计。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 3D场景布局估计 结构化语言模型 多Token预测 自推测解码 置信度引导解码 参数高效 推理加速
📋 核心要点
- 现有的基于语言模型的感知通用方法依赖于自回归的下一个Token预测,速度较慢,限制了其在3D场景布局估计等任务中的应用。
- Fast SceneScript通过多Token预测(MTP)减少自回归迭代次数,并结合自推测解码(SSD)和置信度引导解码(CGD)来保证预测的准确性。
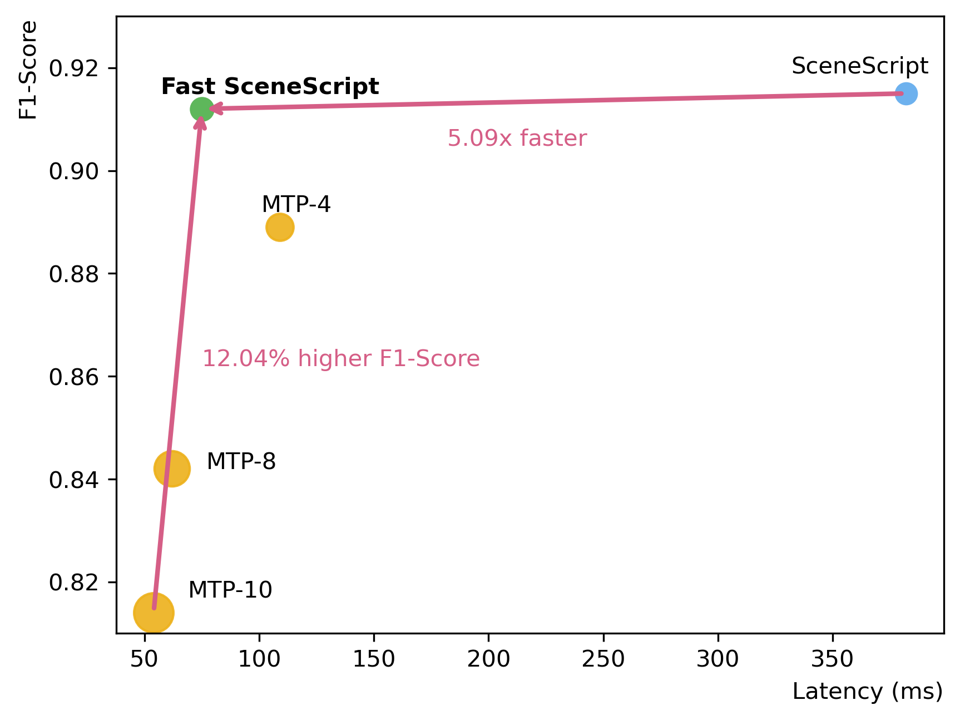
- 实验结果表明,Fast SceneScript在保证精度的前提下,显著提升了推理速度,并且参数开销很小,在ASE和Structured3D数据集上表现出色。
📝 摘要(中文)
本文提出了一种名为Fast SceneScript的新型结构化语言模型,用于精确高效的3D场景布局估计。该方法采用多Token预测(MTP)来减少自回归迭代次数,从而显著加速推理。为了解决MTP带来的Token预测可靠性问题,本文将自推测解码(SSD)适配于结构化语言模型,并引入了置信度引导解码(CGD),使用改进的评分机制来评估Token的可靠性。此外,还设计了一种参数高效的机制,以减少MTP的参数开销。在ASE和Structured3D基准测试上的大量实验表明,Fast SceneScript能够在不牺牲准确性的前提下,在每个解码器推理步骤中生成多达9个Token,同时仅增加约7.5%的额外参数。
🔬 方法详解
问题定义:现有基于语言模型的3D场景布局估计方法依赖于自回归的Token预测,速度慢,效率低。每次只能预测一个Token,需要多次迭代才能完成整个场景的描述,计算成本高昂。因此,如何加速3D场景布局估计过程,提高推理效率是一个关键问题。
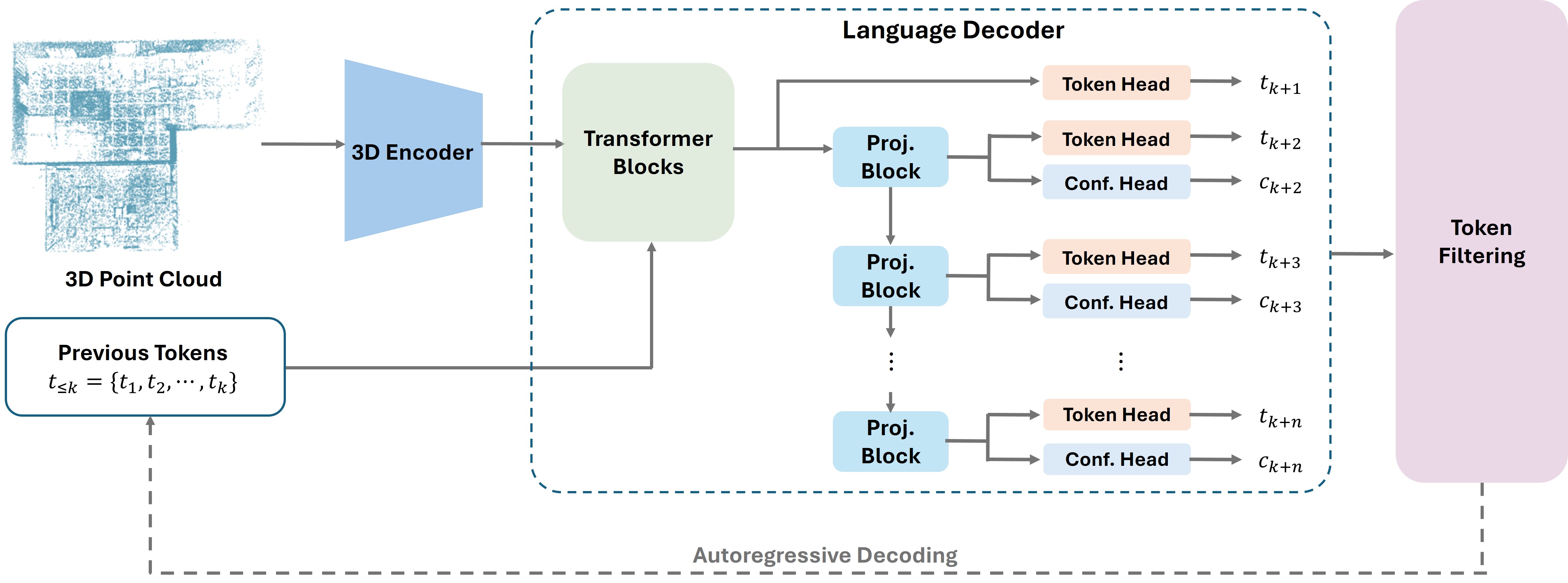
核心思路:本文的核心思路是通过多Token预测(MTP)来减少自回归迭代的次数,从而加速推理过程。MTP允许模型一次性预测多个Token,显著降低了推理所需的步骤。为了解决MTP可能带来的预测不准确问题,引入了置信度机制来过滤不可靠的Token。
技术框架:Fast SceneScript的整体框架基于结构化语言模型,主要包含以下几个模块:1) 多Token预测模块:负责一次性预测多个Token;2) 自推测解码(SSD)模块:用于初步筛选可靠的Token;3) 置信度引导解码(CGD)模块:通过改进的评分机制进一步评估Token的可靠性,并选择置信度高的Token;4) 参数高效机制:减少MTP引入的额外参数开销。整个流程是,首先使用MTP预测多个Token,然后通过SSD和CGD进行筛选,最终得到准确的场景描述。
关键创新:本文的关键创新在于将多Token预测(MTP)与自推测解码(SSD)和置信度引导解码(CGD)相结合,应用于结构化语言模型,从而在保证精度的前提下显著提升了推理速度。此外,参数高效机制的设计也降低了MTP的参数开销。与传统的自回归方法相比,Fast SceneScript能够一次性预测多个Token,大大减少了迭代次数。
关键设计:在置信度引导解码(CGD)中,设计了一种改进的评分机制,用于评估Token的可靠性。该评分机制综合考虑了Token的概率、上下文信息等因素,从而更准确地判断Token的质量。此外,为了减少MTP的参数开销,采用了一种参数共享的策略,使得多个Token预测头共享一部分参数,从而降低了模型的复杂度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Fast SceneScript能够在不牺牲准确性的前提下,显著提升推理速度。在ASE和Structured3D基准测试中,Fast SceneScript能够生成多达9个Token/decoder step,同时仅增加约7.5%的额外参数。与传统的自回归方法相比,Fast SceneScript在速度上有了显著的提升,并且在精度上保持了竞争力。
🎯 应用场景
Fast SceneScript在3D场景理解、机器人导航、虚拟现实和增强现实等领域具有广泛的应用前景。它可以用于快速生成逼真的3D场景布局,提高机器人对环境的感知能力,并为用户提供更沉浸式的虚拟现实体验。该研究的成果有助于推动相关领域的发展,并为未来的研究提供新的思路。
📄 摘要(原文)
Recent perception-generalist approaches based on language models have achieved state-of-the-art results across diverse tasks, including 3D scene layout estimation, via unified architecture and interface. However, these approaches rely on autoregressive next-token prediction, which is inherently slow. In this work, we introduce Fast SceneScript, a novel structured language model for accurate and efficient 3D scene layout estimation. Our method employs multi-token prediction (MTP) to reduce the number of autoregressive iterations and significantly accelerate inference. While MTP improves speed, unreliable token predictions can significantly reduce accuracy. To filter out unreliable tokens, we adapt self-speculative decoding (SSD) for structured language models and introduce confidence-guided decoding (CGD) with an improved scoring mechanism for token reliability. Furthermore, we design a parameter-efficient mechanism that reduces the parameter overhead of MTP. Extensive experiments on the ASE and Structured3D benchmarks demonstrate that Fast SceneScript can generate up to 9 tokens per decoder inference step without compromising accuracy, while adding only $\sim7.5\%$ additional parameters.