Conscious Gaze: Adaptive Attention Mechanisms for Hallucination Mitigation in Vision-Language Models
作者: Weijue Bu, Guan Yuan, Guixian Zhang
分类: cs.CV, cs.AI
发布日期: 2025-12-05
备注: 6 pages, 6 figures
💡 一句话要点
提出Conscious Gaze,通过自适应注意力机制缓解视觉-语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 幻觉缓解 注意力机制 博弈论 可解释性
📋 核心要点
- 现有视觉-语言模型易受文本惯性影响,导致幻觉,而现有方法或仅干预输出,或缺乏原则性。
- Conscious Gaze通过认知需求传感器判断视觉基础必要性,并利用聚焦共识诱导模块重定向注意力。
- CG-VLM在多个模型和数据集上取得SOTA结果,证明了其在缓解幻觉方面的有效性和通用性。
📝 摘要(中文)
大型视觉-语言模型(VLMs)常常表现出文本惯性,即注意力从视觉证据漂移到语言先验,导致对象幻觉。现有的解码策略仅在输出logits上进行干预,无法纠正内部推理漂移。而最近基于启发式头部抑制或全局引导向量的内部控制方法缺乏原则性基础。我们提出了Conscious Gaze (CG-VLM),这是一个无需训练的推理时框架,它将博弈论可解释性转化为可操作的解码控制。一个基于Harsanyi交互的认知需求传感器估计瞬时视觉-文本协同作用,并识别视觉基础必要的时刻。基于此信号,一个聚焦共识诱导模块选择性地将中间层注意力重新定向到视觉tokens,以防止其崩溃为文本先验。CG-VLM在InstructBLIP、LLaVA、Qwen-VL和mPLUG上,于POPE和CHAIR数据集取得了最先进的结果,同时保留了一般能力,表明token级别的感知能够实现精确的、上下文感知的干预,而不会损害基础知识。
🔬 方法详解
问题定义:视觉-语言模型(VLMs)在生成文本描述时,容易受到语言先验的影响,产生与图像内容不符的“幻觉”对象。现有方法,如直接修改输出logits,无法纠正模型内部推理过程中的偏差。而基于启发式的方法,如抑制特定注意力头或使用全局引导向量,缺乏理论依据,且可能损害模型的通用能力。
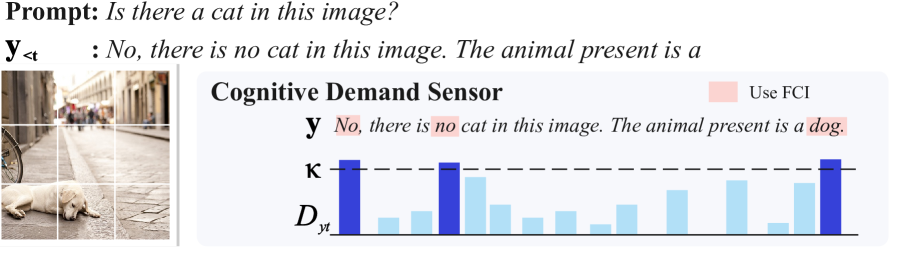
核心思路:Conscious Gaze的核心思想是赋予模型一种“意识”,使其能够感知何时需要更强的视觉 grounding。通过博弈论中的Harsanyi交互来量化视觉和文本之间的协同作用,以此判断模型是否过度依赖语言先验。当检测到视觉 grounding 不足时,选择性地将注意力重新引导到视觉 tokens,从而减少幻觉。
技术框架:CG-VLM主要包含两个模块:认知需求传感器(Cognitive Demand Sensor)和聚焦共识诱导模块(Focused Consensus Induction)。认知需求传感器利用Harsanyi交互计算视觉和文本tokens之间的协同效应,输出一个指示视觉 grounding 需求的信号。聚焦共识诱导模块根据该信号,选择性地调整中间层注意力,将注意力更多地分配给视觉tokens。整个框架在推理时运行,无需额外的训练。
关键创新:CG-VLM的关键创新在于将博弈论的可解释性应用于视觉-语言模型的控制。通过认知需求传感器,模型能够自适应地感知视觉 grounding 的必要性,并根据感知结果进行干预。这种token级别的感知和干预方式,比全局引导向量或注意力头抑制更加精细和有效。
关键设计:认知需求传感器使用Harsanyi交互来量化视觉和文本tokens之间的协同效应。具体而言,它计算每个token对模型输出的边际贡献,并以此衡量其重要性。聚焦共识诱导模块使用一个可学习的权重来控制注意力重定向的强度。该权重由认知需求传感器的输出信号调节,从而实现自适应的注意力调整。
🖼️ 关键图片


📊 实验亮点
CG-VLM在POPE和CHAIR数据集上,针对InstructBLIP、LLaVA、Qwen-VL和mPLUG等多个模型,均取得了SOTA结果。实验表明,CG-VLM能够有效减少视觉-语言模型中的幻觉,同时保持模型的一般能力,验证了其有效性和通用性。
🎯 应用场景
Conscious Gaze可应用于各种需要高可靠性和准确性的视觉-语言任务,例如图像字幕生成、视觉问答、机器人导航和医疗影像诊断。通过减少幻觉,该方法可以提高模型在这些应用中的实用性和可信度,并为未来的视觉-语言模型研究提供新的方向。
📄 摘要(原文)
Large Vision-Language Models (VLMs) often exhibit text inertia, where attention drifts from visual evidence toward linguistic priors, resulting in object hallucinations. Existing decoding strategies intervene only at the output logits and thus cannot correct internal reasoning drift, while recent internal-control methods based on heuristic head suppression or global steering vectors lack principled grounding. We introduce Conscious Gaze (CG-VLM), a training-free, inference-time framework that converts game-theoretic interpretability into actionable decoding control. A Cognitive Demand Sensor built on Harsanyi interactions estimates instantaneous vision-text synergy and identifies moments when visual grounding is necessary. Conditioned on this signal, a Focused Consensus Induction module selectively reorients mid-layer attention toward visual tokens before collapse into text priors. CG-VLM achieves state-of-the-art results on POPE and CHAIR across InstructBLIP, LLaVA, Qwen-VL, and mPLUG, while preserving general capabilities, demonstrating that token-level sensing enables precise, context-aware intervention without compromising foundational knowledge.