DashFusion: Dual-stream Alignment with Hierarchical Bottleneck Fusion for Multimodal Sentiment Analysis
作者: Yuhua Wen, Qifei Li, Yingying Zhou, Yingming Gao, Zhengqi Wen, Jianhua Tao, Ya Li
分类: cs.CV, cs.LG
发布日期: 2025-12-05
备注: Accepted to IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出DashFusion,通过双流对齐和分层瓶颈融合解决多模态情感分析中的对齐与融合问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 跨模态对齐 特征融合 对比学习 注意力机制
📋 核心要点
- 现有MSA方法在处理多模态数据时,通常孤立地解决对齐或融合问题,导致性能和效率受限。
- DashFusion通过双流对齐模块同步多模态特征,并利用分层瓶颈融合逐步整合信息,实现高效的情感分析。
- 实验结果表明,DashFusion在CMU-MOSI、CMU-MOSEI和CH-SIMS数据集上取得了SOTA性能,验证了方法的有效性。
📝 摘要(中文)
多模态情感分析(MSA)整合文本、图像和音频等多种模态,以提供对情感更全面的理解。然而,有效的MSA面临对齐和融合的挑战。对齐需要在模态之间同步时间和语义信息,而融合涉及将这些对齐的特征整合到统一的表示中。现有方法通常孤立地解决对齐或融合问题,导致性能和效率的限制。为了解决这些问题,我们提出了一种名为双流对齐与分层瓶颈融合(DashFusion)的新框架。首先,双流对齐模块通过时间和语义对齐同步多模态特征。时间对齐采用跨模态注意力来建立多模态序列之间的帧级对应关系。语义对齐通过对比学习确保特征空间的一致性。其次,监督对比学习利用标签信息来细化模态特征。最后,分层瓶颈融合通过压缩的瓶颈token逐步整合多模态信息,从而在性能和计算效率之间取得平衡。我们在三个数据集CMU-MOSI、CMU-MOSEI和CH-SIMS上评估DashFusion。实验结果表明,DashFusion在各种指标上实现了最先进的性能,并且消融研究证实了我们的对齐和融合技术的有效性。
🔬 方法详解
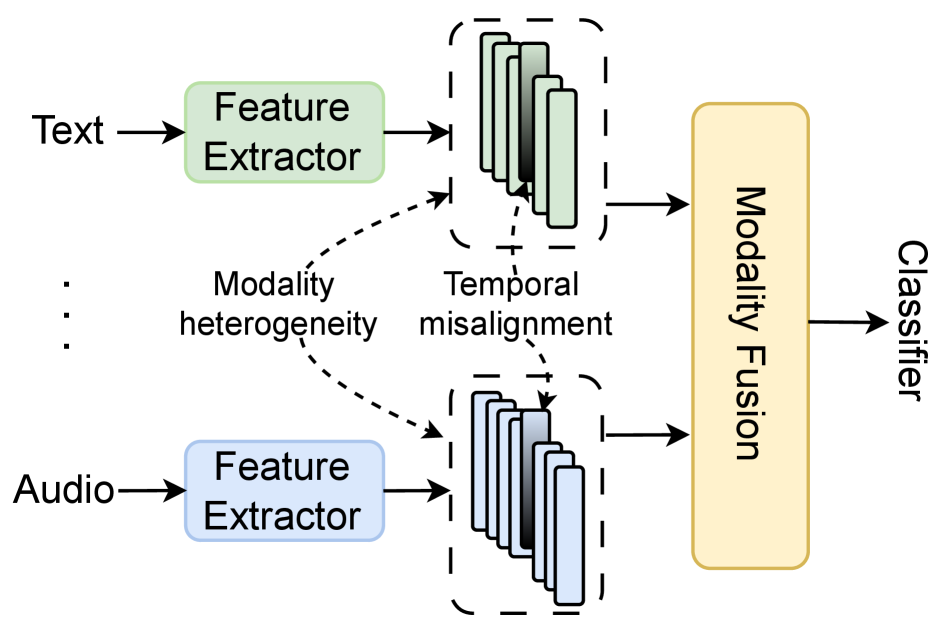
问题定义:多模态情感分析旨在融合来自不同模态(如文本、图像、音频)的信息,以更准确地理解情感。现有方法在对齐不同模态的信息以及有效融合这些信息方面存在挑战。具体来说,时间上的不对齐和语义上的不一致是两个主要的痛点,导致最终情感预测的准确性降低。
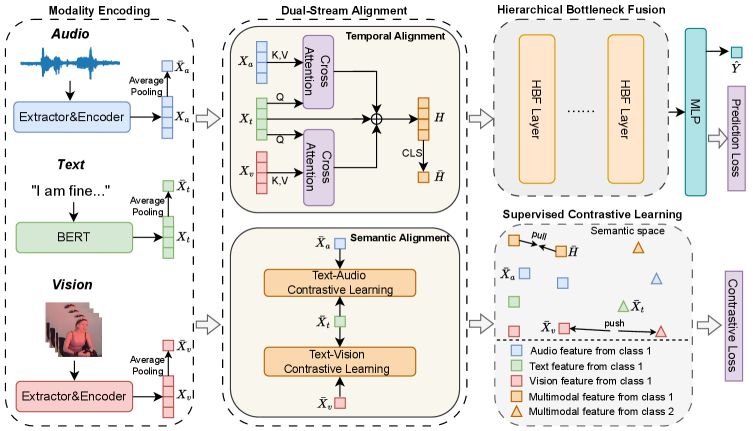
核心思路:DashFusion的核心思路是同时解决多模态情感分析中的对齐和融合问题。它通过双流结构分别进行时间和语义对齐,然后通过分层瓶颈融合模块逐步整合对齐后的特征。这种设计旨在充分利用不同模态的信息,同时减少计算复杂度。
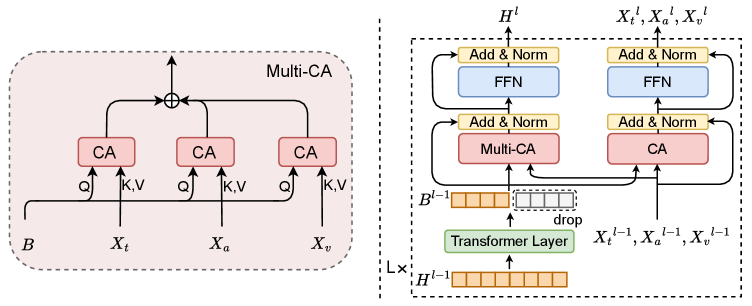
技术框架:DashFusion框架包含以下几个主要模块:1) 双流对齐模块:包括时间对齐和语义对齐两个子模块,分别用于建立跨模态的帧级对应关系和确保特征空间的一致性。2) 监督对比学习模块:利用标签信息来优化模态特征,提高特征的区分性。3) 分层瓶颈融合模块:通过压缩的瓶颈token逐步整合多模态信息,实现性能和效率的平衡。整个流程是先对齐,再融合,最后进行情感预测。
关键创新:DashFusion的关键创新在于其双流对齐和分层瓶颈融合机制。双流对齐同时考虑了时间和语义两个层面的对齐,比单一的对齐方法更全面。分层瓶颈融合通过逐步压缩信息,降低了计算复杂度,同时保留了关键信息。与现有方法相比,DashFusion能够更有效地利用多模态信息,提高情感分析的准确性和效率。
关键设计:在时间对齐中,使用了跨模态注意力机制来建立帧级对应关系。在语义对齐中,使用了对比学习损失函数来确保特征空间的一致性。在分层瓶颈融合中,使用了可学习的瓶颈token来压缩信息。监督对比学习使用了标签信息来指导特征学习。具体的网络结构和参数设置在论文中有详细描述,例如损失函数的权重、注意力机制的类型等。
🖼️ 关键图片
📊 实验亮点
DashFusion在CMU-MOSI、CMU-MOSEI和CH-SIMS三个数据集上均取得了state-of-the-art的性能。例如,在CMU-MOSI数据集上,相比于之前的最佳模型,DashFusion在某些指标上取得了显著的提升。消融实验也证明了双流对齐和分层瓶颈融合模块的有效性,单独移除任何一个模块都会导致性能下降。
🎯 应用场景
DashFusion可应用于各种多模态情感分析场景,如社交媒体情感监控、客户服务质量评估、人机交互等。通过更准确地理解用户的情感,可以提升用户体验,优化产品设计,并为决策提供更可靠的依据。未来,该技术有望应用于更复杂的场景,如医疗诊断和智能驾驶。
📄 摘要(原文)
Multimodal sentiment analysis (MSA) integrates various modalities, such as text, image, and audio, to provide a more comprehensive understanding of sentiment. However, effective MSA is challenged by alignment and fusion issues. Alignment requires synchronizing both temporal and semantic information across modalities, while fusion involves integrating these aligned features into a unified representation. Existing methods often address alignment or fusion in isolation, leading to limitations in performance and efficiency. To tackle these issues, we propose a novel framework called Dual-stream Alignment with Hierarchical Bottleneck Fusion (DashFusion). Firstly, dual-stream alignment module synchronizes multimodal features through temporal and semantic alignment. Temporal alignment employs cross-modal attention to establish frame-level correspondences among multimodal sequences. Semantic alignment ensures consistency across the feature space through contrastive learning. Secondly, supervised contrastive learning leverages label information to refine the modality features. Finally, hierarchical bottleneck fusion progressively integrates multimodal information through compressed bottleneck tokens, which achieves a balance between performance and computational efficiency. We evaluate DashFusion on three datasets: CMU-MOSI, CMU-MOSEI, and CH-SIMS. Experimental results demonstrate that DashFusion achieves state-of-the-art performance across various metrics, and ablation studies confirm the effectiveness of our alignment and fusion techniques. The codes for our experiments are available at https://github.com/ultramarineX/DashFusion.