LoC-Path: Learning to Compress for Pathology Multimodal Large Language Models
作者: Qingqiao Hu, Weimin Lyu, Meilong Xu, Kehan Qi, Xiaoling Hu, Saumya Gupta, Jiawei Zhou, Chao Chen
分类: cs.CV
发布日期: 2025-12-05 (更新: 2025-12-11)
备注: 20 pages
💡 一句话要点
提出LoC-Path,通过压缩冗余信息提升病理多模态大语言模型的效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 病理图像分析 多模态大语言模型 全切片图像 冗余压缩 计算效率
📋 核心要点
- 现有病理多模态大语言模型处理全切片图像时,计算成本高昂,因为它们依赖于处理大量冗余patch特征的切片级编码器。
- LoC-Path通过引入稀疏Token合并器和MAE预训练的重采样器来压缩tile特征,从而减少局部和全局冗余,降低计算复杂度。
- 实验结果表明,LoC-Path在保持与现有方法相当的性能水平下,显著降低了计算和内存需求,提升了效率。
📝 摘要(中文)
由于千兆像素的尺度和诊断相关区域的极端稀疏性,全切片图像(WSI)理解极具挑战性。与主要依赖关键区域进行诊断的专家不同,现有的病理切片级多模态大语言模型(MLLM)依赖于繁重的切片级编码器,以蛮力方式处理数千个patch特征,导致过高的计算成本。本文重新审视了WSI-语言建模范式,并表明tile级别的特征表现出很强的全局和局部冗余,而只有一小部分tile与任务真正相关。基于此,我们提出了一个高效的MLLM框架LoC-Path,用冗余减少模块替换了昂贵的切片级编码器。我们首先设计了一个稀疏Token合并器(STM)和一个MAE预训练的重采样器,以消除局部冗余并将全局冗余的tile token压缩成紧凑的切片级表示集。然后,我们提出了一个交叉注意力路由适配器(CARA)和一个Token重要性评分器(TIS),以计算高效的方式将压缩的视觉表示与语言模型集成。大量实验表明,我们的方法在实现与现有最先进的whole-slide MLLM相当的性能的同时,显著降低了计算和内存需求。
🔬 方法详解
问题定义:现有病理多模态大语言模型在处理全切片图像(WSI)时,需要处理大量的图像patch,计算复杂度高,效率低下。这是因为WSI中存在大量的冗余信息,而现有方法没有有效地去除这些冗余。因此,如何降低计算成本,提高处理效率,是本文要解决的核心问题。
核心思路:本文的核心思路是通过压缩WSI中的冗余信息,减少需要处理的token数量,从而降低计算复杂度。作者观察到tile级别的特征存在很强的全局和局部冗余,因此设计了相应的模块来去除这些冗余。通过压缩后的精简表示,可以显著减少后续处理的计算量,提高效率。
技术框架:LoC-Path框架主要包含以下几个模块:1) 稀疏Token合并器(STM):用于消除局部冗余;2) MAE预训练的重采样器:用于压缩全局冗余的tile token;3) 交叉注意力路由适配器(CARA):用于将压缩的视觉表示与语言模型集成;4) Token重要性评分器(TIS):用于进一步提升计算效率。整体流程是先通过STM和重采样器进行视觉特征压缩,然后通过CARA和TIS将压缩后的视觉特征与语言模型进行融合。
关键创新:LoC-Path的关键创新在于其冗余减少模块的设计,包括STM和MAE预训练的重采样器。这些模块能够有效地去除WSI中的局部和全局冗余,从而显著降低计算复杂度。与现有方法相比,LoC-Path不再依赖于处理大量的冗余patch特征,而是专注于处理更具代表性的压缩特征。
关键设计:STM的具体实现细节未知,但其目标是合并局部相似的token。MAE预训练的重采样器利用了MAE的预训练权重,可能通过自编码器的结构来学习更有效的特征表示。CARA和TIS的具体结构和参数设置未知,但它们的设计目标是高效地将压缩后的视觉特征与语言模型进行融合,并根据token的重要性进行加权。
🖼️ 关键图片
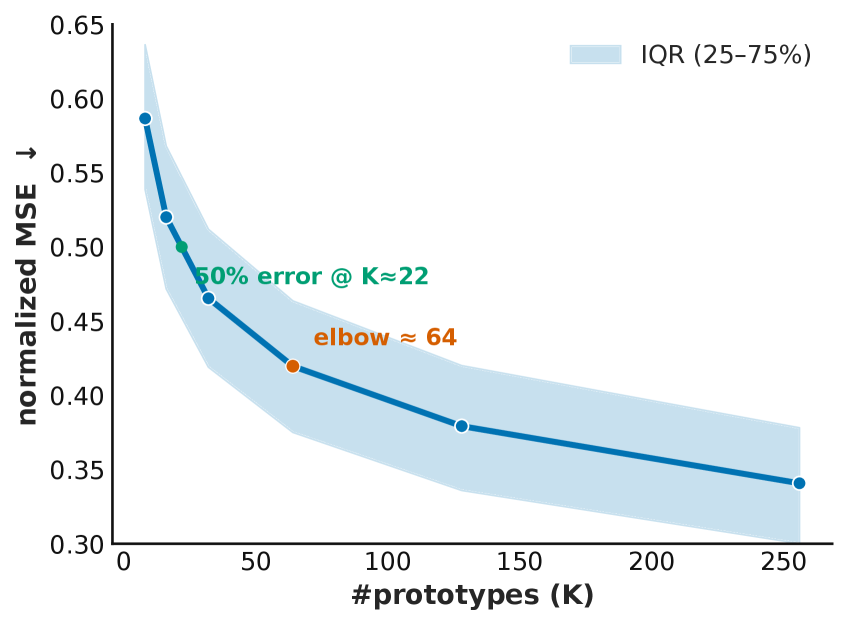
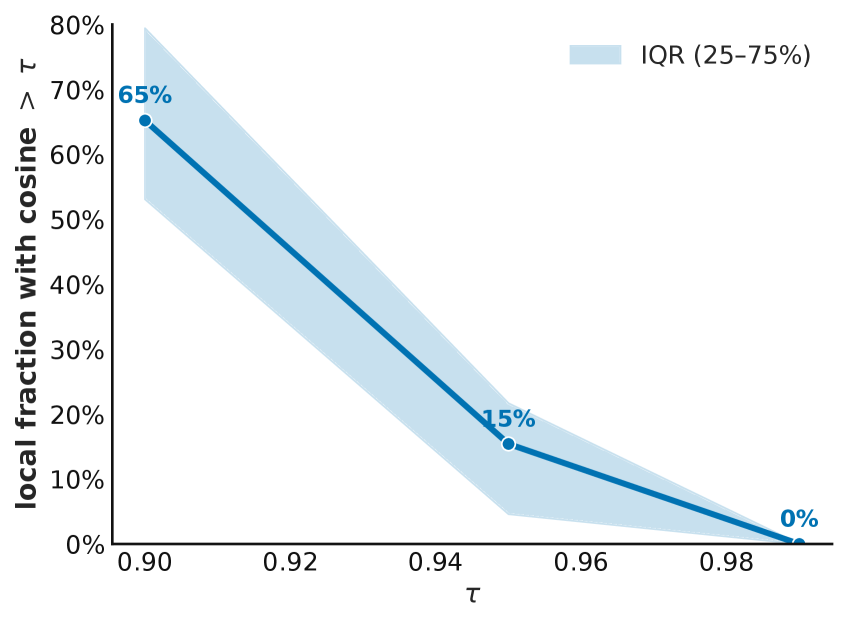

📊 实验亮点
LoC-Path在全切片图像多模态大语言模型任务上取得了与现有最先进方法相当的性能,同时显著降低了计算和内存需求。具体的性能数据和对比基线未知,但摘要强调了其在效率方面的优势。该方法通过压缩冗余信息,实现了在保持性能的同时降低计算成本的目标。
🎯 应用场景
LoC-Path具有广泛的应用前景,可以应用于病理图像分析、辅助诊断、药物研发等领域。通过降低计算成本,该方法可以更容易地部署到资源受限的环境中,例如基层医院或移动医疗设备。此外,该方法还可以扩展到其他需要处理高分辨率图像的多模态任务中,例如遥感图像分析、医学影像诊断等。
📄 摘要(原文)
Whole Slide Image (WSI) understanding is fundamentally challenging due to its gigapixel scale and the extreme sparsity of diagnostically relevant regions. Unlike human experts who primarily rely on key areas to arrive at a diagnosis, existing slide-level multimodal large language models (MLLMs) for pathology rely on heavy slide-level encoders that process thousands of patch features in a brute-force manner, resulting in excessive computational cost. In this work, we revisit the WSI-language modeling paradigm and show that tile-level features exhibit strong global and local redundancy, whereas only a small subset of tiles are truly task-relevant. Motivated by this observation, we introduce an efficient MLLM framework, called LoC-Path, that replaces the expensive slide-level encoder with redundancy-reducing modules. We first design a Sparse Token Merger (STM) and an MAE-pretrained resampler to remove local redundancy and compress globally redundant tile tokens into a compact slide-level representation set. We then propose a Cross-Attention Routing Adapter (CARA) and a Token Importance Scorer (TIS) to integrate the compressed visual representation with the language model in a computation-efficient manner. Extensive experiments demonstrate that our approach achieves performance comparable to existing state-of-the-art whole-slide MLLMs, while requiring significantly lower computation and memory.