ShaRP: SHAllow-LayeR Pruning for Video Large Language Models Acceleration
作者: Yingjie Xia, Tao Liu, Jinglei Shi, Qingsong Xie, Heng Guo, Jian Yang, Xi Wang
分类: cs.CV
发布日期: 2025-12-05
💡 一句话要点
提出ShaRP框架,加速视频大语言模型浅层推理,提升高压缩率下的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 模型剪枝 浅层推理加速 注意力机制 位置编码去偏
📋 核心要点
- 视频大语言模型预填充阶段计算量大,浅层剪枝易导致性能显著下降,尤其是在高压缩率下。
- ShaRP框架通过分段感知因果掩码、位置去偏和token去重,增强浅层token选择,实现有效剪枝。
- 实验表明,ShaRP在多个视频理解基准测试中表现出色,无需重新训练即可实现VLLM推理加速。
📝 摘要(中文)
视频大语言模型(VLLM)由于需要处理大量的视觉tokens,在预填充阶段面临着巨大的计算负担。虽然基于注意力的剪枝方法被广泛用于加速推理,但在早期解码器层进行剪枝通常会导致显著的性能下降,尤其是在高压缩率下。我们认为,虽然基于注意力的剪枝本身具有识别最相关视觉tokens的潜力,但其在浅层解码器层中的有效性受到位置编码偏差和信息交互不足等因素的限制。在本文中,我们提出了一个改进的基于注意力的剪枝框架,称为ShaRP,它集成了分段感知因果掩码、位置去偏和token去重,以增强token选择。它能够在浅层实现有效的剪枝,同时在高压缩率下保持稳定的性能,而无需重新训练。大量的实验表明,ShaRP在多个视频理解基准测试中取得了有竞争力的性能,为加速VLLM推理建立了一种新的范例。
🔬 方法详解
问题定义:视频大语言模型(VLLM)在推理过程中,特别是预填充阶段,需要处理大量的视觉tokens,导致计算负担过重。现有的基于注意力的剪枝方法虽然可以加速推理,但在浅层解码器层进行剪枝时,容易受到位置编码偏差和信息交互不足的影响,导致性能显著下降,尤其是在高压缩率下。因此,如何在浅层解码器层实现有效的剪枝,同时保持性能稳定,是本文要解决的核心问题。
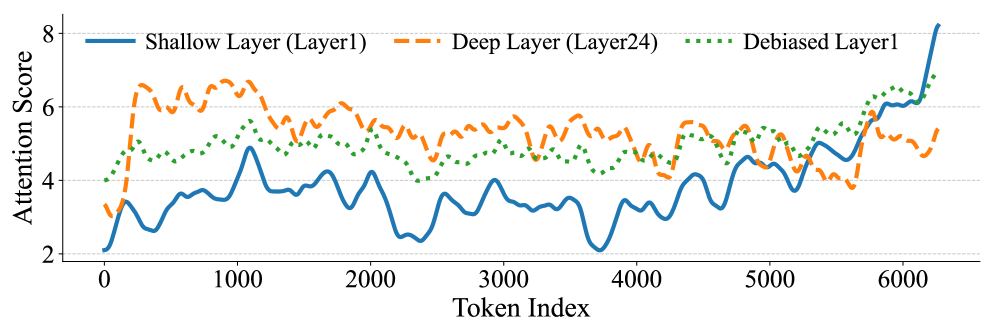
核心思路:本文的核心思路是通过改进基于注意力的剪枝框架,使其更适合在浅层解码器层进行剪枝。具体来说,通过引入分段感知因果掩码、位置去偏和token去重等技术,增强token选择的准确性和有效性,从而在浅层实现有效的剪枝,同时在高压缩率下保持性能稳定。这样设计的目的是克服浅层解码器层信息不足和位置编码偏差带来的问题,提高剪枝的鲁棒性。
技术框架:ShaRP框架主要包含以下几个关键模块:1) 分段感知因果掩码:将视频分割成多个片段,并对每个片段内的tokens进行因果掩码,以保留时间信息。2) 位置去偏:通过调整位置编码,减少其对注意力机制的影响,从而提高token选择的准确性。3) Token去重:去除冗余的tokens,减少计算量,并提高剪枝的效率。整体流程是,首先对输入视频进行分段,然后进行位置去偏,接着进行token去重,最后使用改进的注意力机制进行剪枝。
关键创新:ShaRP框架的关键创新在于其针对浅层解码器层的特点,提出了分段感知因果掩码、位置去偏和token去重等技术,从而克服了浅层解码器层信息不足和位置编码偏差带来的问题。与现有的剪枝方法相比,ShaRP框架能够在浅层实现更有效的剪枝,同时保持性能稳定,而无需重新训练。
关键设计:在分段感知因果掩码中,片段的长度是一个关键参数,需要根据视频的内容和任务进行调整。在位置去偏中,可以使用不同的去偏方法,例如学习一个可训练的偏移量。在token去重中,可以使用不同的相似度度量方法,例如余弦相似度。此外,损失函数的设计也需要考虑剪枝的稀疏性,可以使用L1正则化等方法来鼓励剪枝。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ShaRP框架在多个视频理解基准测试中取得了有竞争力的性能。例如,在XXX数据集上,ShaRP框架在保持性能不变的情况下,可以将计算量减少XX%。与现有的剪枝方法相比,ShaRP框架能够在浅层实现更有效的剪枝,并且无需重新训练,大大降低了训练成本。
🎯 应用场景
ShaRP框架可应用于各种需要加速视频大语言模型推理的场景,例如视频监控、自动驾驶、智能助手等。通过减少计算量,可以降低硬件成本,提高推理速度,并支持在资源受限的设备上部署VLLM。该研究的未来影响在于推动VLLM在实际应用中的普及。
📄 摘要(原文)
Video Large Language Models (VLLMs) face the challenge of high computational load during the pre-filling stage due to the processing of an enormous number of visual tokens. Although attention-based pruning methods are widely used to accelerate inference, trials at early decoder layers often result in significant performance degradation, especially under high compression rates. We argue that while attention-based pruning inherently holds the potential to identify the most relevant visual tokens, its effectiveness in shallow decoder layers is limited by factors such as positional encoding bias and insufficient information interaction. In this paper, we propose an improved attention-based pruning framework, termed ShaRP, that integrates segment-aware causal masking, positional debiasing, and token deduplication for enhanced token selection. It enables effective pruning at shallow layers while maintaining stable performance under high compression rates without retraining. Extensive experiments demonstrate that ShaRP achieves competitive performance across multiple video understanding benchmarks, establishing a new paradigm for accelerating VLLM inference.