Object Reconstruction under Occlusion with Generative Priors and Contact-induced Constraints
作者: Minghan Zhu, Zhiyi Wang, Qihang Sun, Maani Ghaffari, Michael Posa
分类: cs.CV, cs.RO
发布日期: 2025-12-04
备注: Project page: https://contactgen3d.github.io/
💡 一句话要点
提出基于生成先验和接触约束的物体遮挡重建方法,提升机器人操作性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 三维重建 物体遮挡 生成模型 接触约束 机器人操作
📋 核心要点
- 相机只能捕捉到物体的部分观测,尤其是在发生遮挡时,这使得物体三维重建成为一项具有挑战性的任务。
- 利用生成模型学习物体形状的先验知识,并结合从视频或物理交互中获得的接触信息,对物体的三维几何形状进行约束。
- 在合成和真实数据上的实验结果表明,该方法相较于单独使用三维生成或基于接触的优化方法,能够显著提升重建效果。
📝 摘要(中文)
本文研究了物体遮挡下的三维重建问题,该问题对机器人操作至关重要。为了减少视觉信号的歧义性,本文利用了两种额外的信息来源。首先,生成模型学习常见物体的形状先验,从而对未见部分进行合理的猜测。其次,接触信息(可从视频和物理交互中获得)提供了物体几何边界的稀疏约束。我们将这两种信息通过接触引导的三维生成相结合。引导公式的灵感来自生成模型中的基于拖动的编辑。在合成和真实数据上的实验表明,与纯三维生成和基于接触的优化相比,我们的方法提高了重建效果。
🔬 方法详解
问题定义:论文旨在解决物体在部分遮挡情况下,如何准确进行三维重建的问题。现有方法在遮挡严重时,仅依赖视觉信息难以获得可靠的重建结果,导致机器人操作性能下降。
核心思路:论文的核心思路是结合生成模型的形状先验知识和接触信息提供的几何约束,共同指导三维重建过程。生成模型弥补视觉信息的缺失,接触信息则校正生成模型的偏差,二者互补,提升重建精度。
技术框架:该方法的核心是接触引导的三维生成框架。首先,利用生成模型生成物体的初始三维形状。然后,根据接触信息,通过类似于拖动编辑的方式,对生成的三维形状进行调整,使其满足接触约束。整个流程可以看作是利用接触信息对生成模型的输出进行精细化调整的过程。
关键创新:该方法最重要的创新在于将生成模型的先验知识与接触信息提供的约束相结合,提出了一种接触引导的三维生成方法。这种结合方式有效地利用了两种互补的信息来源,克服了单独使用视觉信息或生成模型进行重建的局限性。
关键设计:接触引导的实现方式借鉴了生成模型中的拖动编辑技术。具体而言,通过定义一个损失函数,鼓励生成的三维形状在接触点附近与接触信息保持一致。损失函数的设计需要考虑接触点的稀疏性和噪声,以保证重建的鲁棒性。此外,生成模型的选择也会影响重建效果,需要选择能够生成高质量、多样性三维形状的模型。
🖼️ 关键图片

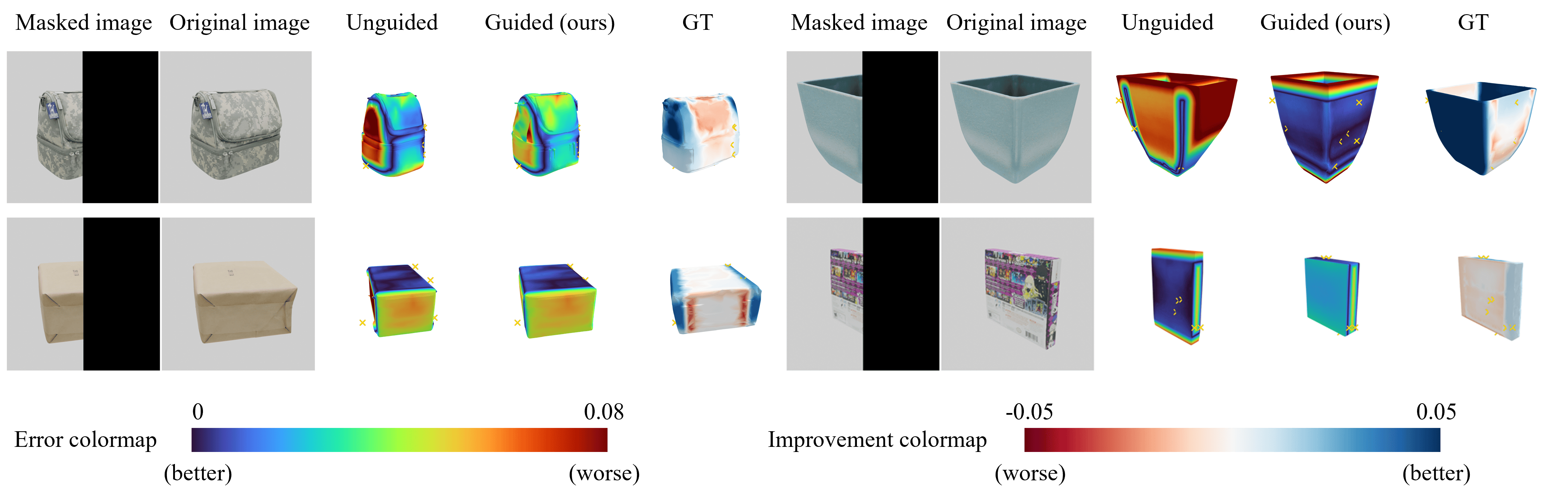

📊 实验亮点
实验结果表明,该方法在合成和真实数据集上均优于纯三维生成和基于接触的优化方法。具体而言,在遮挡情况下,该方法能够更准确地重建物体的三维形状,尤其是在接触点附近。定量指标显示,该方法在重建精度方面有显著提升。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、增强现实等领域。例如,在机器人操作中,即使物体被部分遮挡,机器人也能通过重建物体的完整三维模型,从而实现更精确的抓取、放置等操作。在自动驾驶中,可以帮助车辆更好地理解周围环境,提高行驶安全性。
📄 摘要(原文)
Object geometry is key information for robot manipulation. Yet, object reconstruction is a challenging task because cameras only capture partial observations of objects, especially when occlusion occurs. In this paper, we leverage two extra sources of information to reduce the ambiguity of vision signals. First, generative models learn priors of the shapes of commonly seen objects, allowing us to make reasonable guesses of the unseen part of geometry. Second, contact information, which can be obtained from videos and physical interactions, provides sparse constraints on the boundary of the geometry. We combine the two sources of information through contact-guided 3D generation. The guidance formulation is inspired by drag-based editing in generative models. Experiments on synthetic and real-world data show that our approach improves the reconstruction compared to pure 3D generation and contact-based optimization.