Generative Neural Video Compression via Video Diffusion Prior
作者: Qi Mao, Hao Cheng, Tinghan Yang, Libiao Jin, Siwei Ma
分类: cs.CV
发布日期: 2025-12-04
💡 一句话要点
提出基于视频扩散先验的生成式神经视频压缩框架GNVC-VD,解决感知视频压缩中的时域闪烁问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频压缩 神经视频编解码 生成模型 扩散模型 视频扩散Transformer 感知质量 时域一致性
📋 核心要点
- 现有感知视频压缩依赖图像生成先验,缺乏时域建模,导致感知闪烁。
- GNVC-VD利用视频扩散Transformer进行序列级去噪,联合增强帧内和帧间潜在特征。
- 实验表明,GNVC-VD在感知质量上超越传统和学习型编解码器,显著减少闪烁伪影。
📝 摘要(中文)
本文提出了一种基于DiT的生成式神经视频压缩框架GNVC-VD,该框架建立在先进的视频生成基础模型之上,将时空潜在压缩和序列级生成细化统一在一个编解码器中。现有的感知编解码器主要依赖于预训练的图像生成先验来恢复高频细节,但其逐帧特性缺乏时间建模,不可避免地导致感知闪烁。为了解决这个问题,GNVC-VD引入了一个统一的流匹配潜在细化模块,该模块利用视频扩散Transformer通过序列级去噪来联合增强帧内和帧间潜在特征,从而确保一致的时空细节。与视频生成中从纯高斯噪声中去噪不同,GNVC-VD从解码的时空潜在特征初始化细化,并学习一个校正项,使扩散先验适应压缩引起的退化。一个条件适配器进一步将压缩感知线索注入到中间DiT层中,从而在极端的比特率约束下实现有效的伪影去除,同时保持时间一致性。大量实验表明,GNVC-VD在感知质量上优于传统和学习型编解码器,并显著减少了先前生成方法中持续存在的闪烁伪影,即使在低于0.01 bpp的情况下也是如此,突出了将视频原生生成先验集成到神经编解码器中以实现下一代感知视频压缩的希望。
🔬 方法详解
问题定义:现有的感知视频压缩方法,尤其是基于图像生成先验的方法,在恢复高频细节时表现良好,但由于缺乏对视频时域信息的建模,导致压缩后的视频出现明显的时域闪烁伪影,影响用户体验。这些方法通常是逐帧处理,忽略了视频帧之间的时间相关性。
核心思路:GNVC-VD的核心思路是利用视频扩散模型作为先验知识,通过序列级的去噪过程,同时优化帧内和帧间的潜在表示,从而保证压缩视频在时间上的连贯性。该方法不是直接从噪声生成视频,而是从压缩后的潜在表示出发,学习一个校正项,将压缩引入的失真去除,并利用扩散模型生成更逼真的细节。
技术框架:GNVC-VD框架包含以下主要模块:1) 编码器:将输入视频压缩为时空潜在表示。2) 解码器:从压缩后的潜在表示重建视频。3) 流匹配潜在细化模块:利用视频扩散Transformer,通过序列级去噪来增强潜在表示,减少压缩伪影。4) 条件适配器:将压缩感知线索注入到扩散Transformer的中间层,以更好地去除伪影并保持时间一致性。整个流程可以看作是先进行传统的压缩和解压缩,然后利用扩散模型进行后处理,提高视频质量。
关键创新:GNVC-VD的关键创新在于将视频扩散模型与神经视频压缩相结合,提出了一种统一的流匹配潜在细化模块。与以往基于图像生成先验的方法不同,GNVC-VD直接利用视频数据训练扩散模型,从而更好地捕捉视频的时域信息。此外,条件适配器的设计使得模型能够根据压缩程度自适应地调整去噪过程,从而在不同的比特率下都能获得良好的性能。
关键设计:GNVC-VD使用DiT(Diffusion Transformer)作为视频扩散模型的基础架构。在训练过程中,模型学习一个校正项,用于将压缩后的潜在表示映射到更接近原始视频的潜在表示。条件适配器通过将压缩相关的元数据(例如量化参数)注入到DiT的中间层,使得模型能够感知压缩失真并进行针对性的修复。损失函数包括重建损失和对抗损失,以保证视频的感知质量。
🖼️ 关键图片


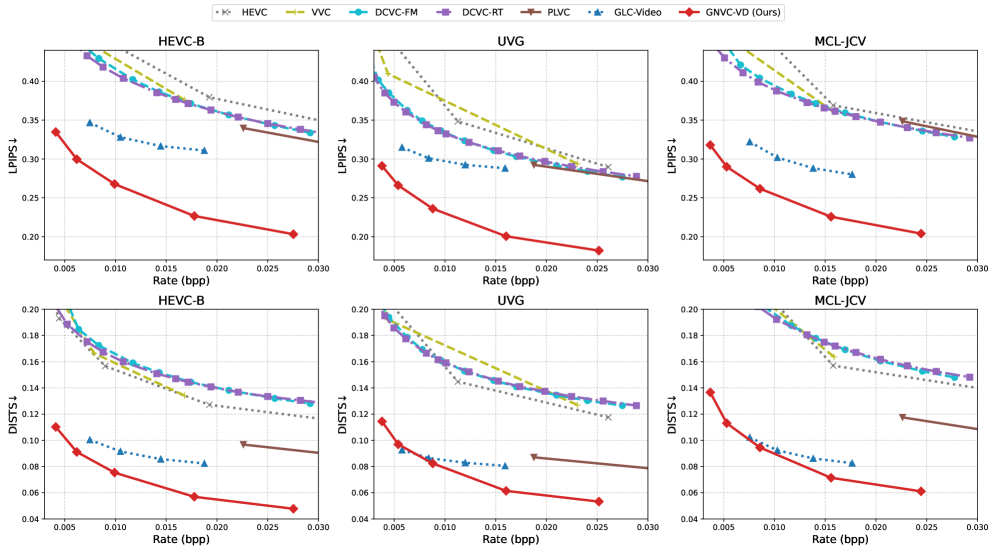
📊 实验亮点
实验结果表明,GNVC-VD在感知质量上显著优于传统的视频编解码器(如H.265)和现有的神经视频编解码器。在低比特率(低于0.01 bpp)下,GNVC-VD仍然能够生成具有良好视觉质量的视频,并显著减少了时域闪烁伪影。主观评价实验也表明,用户更倾向于GNVC-VD生成的视频。
🎯 应用场景
GNVC-VD可应用于各种视频压缩场景,如视频会议、流媒体服务、监控系统等。该技术能够显著提高压缩视频的感知质量,减少带宽需求,并改善用户体验。未来,该研究可以进一步扩展到更高分辨率、更高帧率的视频压缩,以及与其他视频处理任务(如超分辨率、去模糊)相结合。
📄 摘要(原文)
We present GNVC-VD, the first DiT-based generative neural video compression framework built upon an advanced video generation foundation model, where spatio-temporal latent compression and sequence-level generative refinement are unified within a single codec. Existing perceptual codecs primarily rely on pre-trained image generative priors to restore high-frequency details, but their frame-wise nature lacks temporal modeling and inevitably leads to perceptual flickering. To address this, GNVC-VD introduces a unified flow-matching latent refinement module that leverages a video diffusion transformer to jointly enhance intra- and inter-frame latents through sequence-level denoising, ensuring consistent spatio-temporal details. Instead of denoising from pure Gaussian noise as in video generation, GNVC-VD initializes refinement from decoded spatio-temporal latents and learns a correction term that adapts the diffusion prior to compression-induced degradation. A conditioning adaptor further injects compression-aware cues into intermediate DiT layers, enabling effective artifact removal while maintaining temporal coherence under extreme bitrate constraints. Extensive experiments show that GNVC-VD surpasses both traditional and learned codecs in perceptual quality and significantly reduces the flickering artifacts that persist in prior generative approaches, even below 0.01 bpp, highlighting the promise of integrating video-native generative priors into neural codecs for next-generation perceptual video compression.