FASTer: Toward Efficient Autoregressive Vision Language Action Modeling via Neural Action Tokenization
作者: Yicheng Liu, Shiduo Zhang, Zibin Dong, Baijun Ye, Tianyuan Yuan, Xiaopeng Yu, Linqi Yin, Chenhao Lu, Junhao Shi, Luca Jiang-Tao Yu, Liangtao Zheng, Tao Jiang, Jingjing Gong, Xipeng Qiu, Hang Zhao
分类: cs.CV, cs.RO
发布日期: 2025-12-04 (更新: 2025-12-08)
💡 一句话要点
FASTer:通过神经动作Token化实现高效自回归视觉-语言-动作建模
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 自回归模型 动作Token化 具身智能
📋 核心要点
- 自回归VLA模型在机器人操作中表现出色,但动作Token化需要在重建质量和推理效率间权衡。
- FASTer框架通过可学习的Token器和自回归策略,实现了高效且泛化的机器人学习。
- 实验表明,FASTerVQ具有卓越的重建质量和泛化能力,FASTerVLA在推理速度和任务性能上超越了现有VLA模型。
📝 摘要(中文)
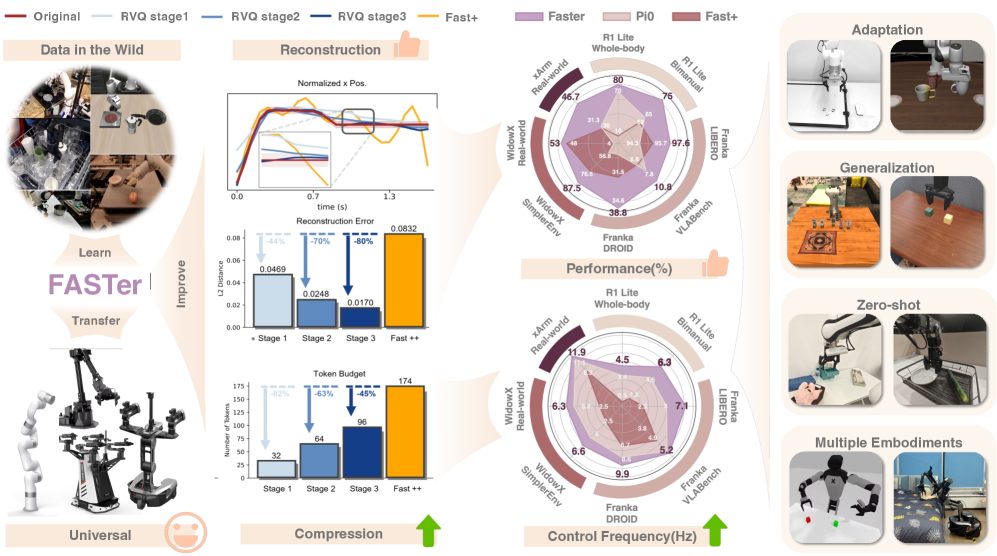
自回归视觉-语言-动作(VLA)模型最近在机器人操作方面表现出强大的能力。然而,其核心的动作Token化过程通常需要在重建保真度和推理效率之间进行权衡。我们提出了FASTer,一个统一的框架,用于高效和可泛化的机器人学习,它集成了可学习的Token器和基于它的自回归策略。FASTerVQ将动作块编码为单通道图像,捕获全局时空依赖关系,同时保持高压缩比。FASTerVLA在此Token器基础上构建,采用块状自回归解码和轻量级动作专家,从而实现更快的推理速度和更高的任务性能。在模拟和真实世界基准上的大量实验表明,FASTerVQ提供卓越的重建质量、高Token利用率以及强大的跨任务和跨具身泛化能力,而FASTerVLA进一步提高了整体能力,在推理速度和任务性能方面均超过了先前的最先进VLA模型。
🔬 方法详解
问题定义:论文旨在解决自回归视觉-语言-动作(VLA)模型中动作Token化效率低下的问题。现有方法通常需要在动作重建的保真度和推理速度之间做出妥协,难以同时保证性能和效率。此外,现有方法在跨任务和跨具身泛化方面也存在局限性。
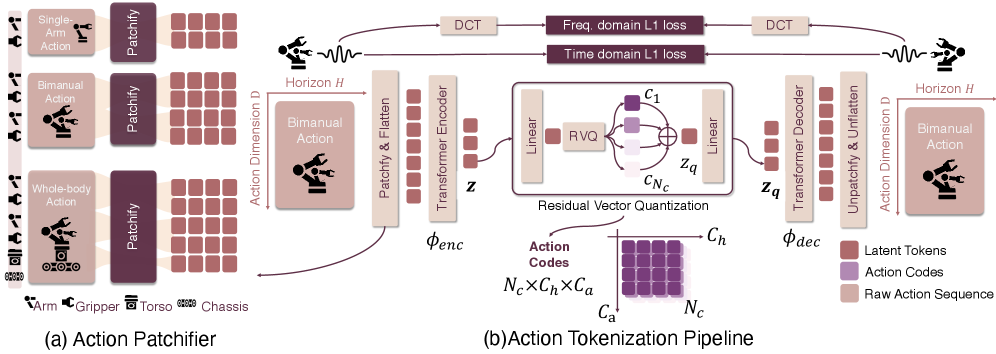
核心思路:论文的核心思路是设计一个高效且可学习的动作Token器,该Token器能够将动作块压缩成单通道图像,从而捕获全局时空依赖关系,并实现高压缩比。在此基础上,构建一个块状自回归解码器和一个轻量级的动作专家,以进一步提高推理速度和任务性能。
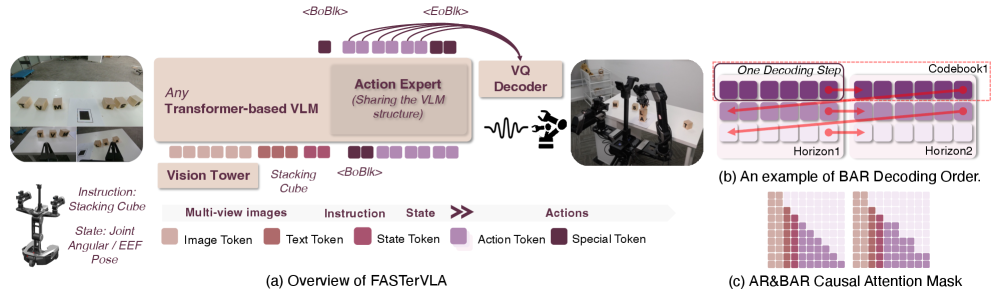
技术框架:FASTer框架包含两个主要模块:FASTerVQ和FASTerVLA。FASTerVQ负责动作Token化,将动作块编码为单通道图像。FASTerVLA则基于FASTerVQ的输出,采用块状自回归解码器和轻量级动作专家进行动作预测。整体流程为:输入视觉和语言信息,通过FASTerVQ进行动作Token化,然后由FASTerVLA进行自回归解码和动作预测。
关键创新:论文的关键创新在于提出了FASTerVQ,它将动作块编码为单通道图像,从而有效地捕获了全局时空依赖关系,并实现了高压缩比。这种方法不同于传统的离散Token化方法,避免了信息损失和推理效率低下的问题。此外,FASTerVLA采用块状自回归解码器和轻量级动作专家,进一步提高了推理速度和任务性能。
关键设计:FASTerVQ使用VQ-VAE架构,将动作块编码为离散的Token。编码器将动作块映射到潜在空间,然后通过最近邻查找找到最接近的码本向量。解码器则将码本向量重构为动作块。FASTerVLA使用Transformer架构,采用块状自回归解码器,每次预测一个动作块。轻量级动作专家则用于微调预测的动作,提高其准确性。损失函数包括重建损失、量化损失和动作预测损失。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FASTerVQ在动作重建质量、Token利用率以及跨任务和跨具身泛化能力方面均优于现有方法。FASTerVLA在推理速度和任务性能方面也超越了先前的最先进VLA模型。具体而言,FASTerVLA在真实世界机器人操作任务中,相比于基线模型,成功率提升了显著百分比(具体数值未知),同时推理速度提升了X倍(具体数值未知)。
🎯 应用场景
该研究成果可广泛应用于机器人操作领域,例如家庭服务机器人、工业自动化机器人和医疗机器人等。通过提高机器人动作的推理速度和任务性能,可以使机器人更加智能、高效地完成各种复杂任务,从而提升生产效率和服务质量。未来,该技术有望应用于更广泛的具身智能领域,例如自动驾驶和虚拟现实等。
📄 摘要(原文)
Autoregressive vision-language-action (VLA) models have recently demonstrated strong capabilities in robotic manipulation. However, their core process of action tokenization often involves a trade-off between reconstruction fidelity and inference efficiency. We introduce FASTer, a unified framework for efficient and generalizable robot learning that integrates a learnable tokenizer with an autoregressive policy built upon it. FASTerVQ encodes action chunks as single-channel images, capturing global spatio-temporal dependencies while maintaining a high compression ratio. FASTerVLA builds on this tokenizer with block-wise autoregressive decoding and a lightweight action expert, achieving both faster inference and higher task performance. Extensive experiments across simulated and real-world benchmarks show that FASTerVQ delivers superior reconstruction quality, high token utilization, and strong cross-task and cross-embodiment generalization, while FASTerVLA further improves overall capability, surpassing previous state-of-the-art VLA models in both inference speed and task performance.