LiteVGGT: Boosting Vanilla VGGT via Geometry-aware Cached Token Merging
作者: Zhijian Shu, Cheng Lin, Tao Xie, Wei Yin, Ben Li, Zhiyuan Pu, Weize Li, Yao Yao, Xun Cao, Xiaoyang Guo, Xiao-Xiao Long
分类: cs.CV
发布日期: 2025-12-04
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
LiteVGGT:通过几何感知缓存Token合并加速VGGT,实现大规模场景高效3D重建。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D重建 视觉几何Transformer Token合并 模型加速 几何感知 缓存机制 大规模场景
📋 核心要点
- 现有VGGT模型在处理大规模3D重建场景时,面临计算量大、内存占用高的挑战,限制了其应用。
- LiteVGGT通过几何感知缓存Token合并,利用局部token几何相关性和层间token相似性,减少计算冗余。
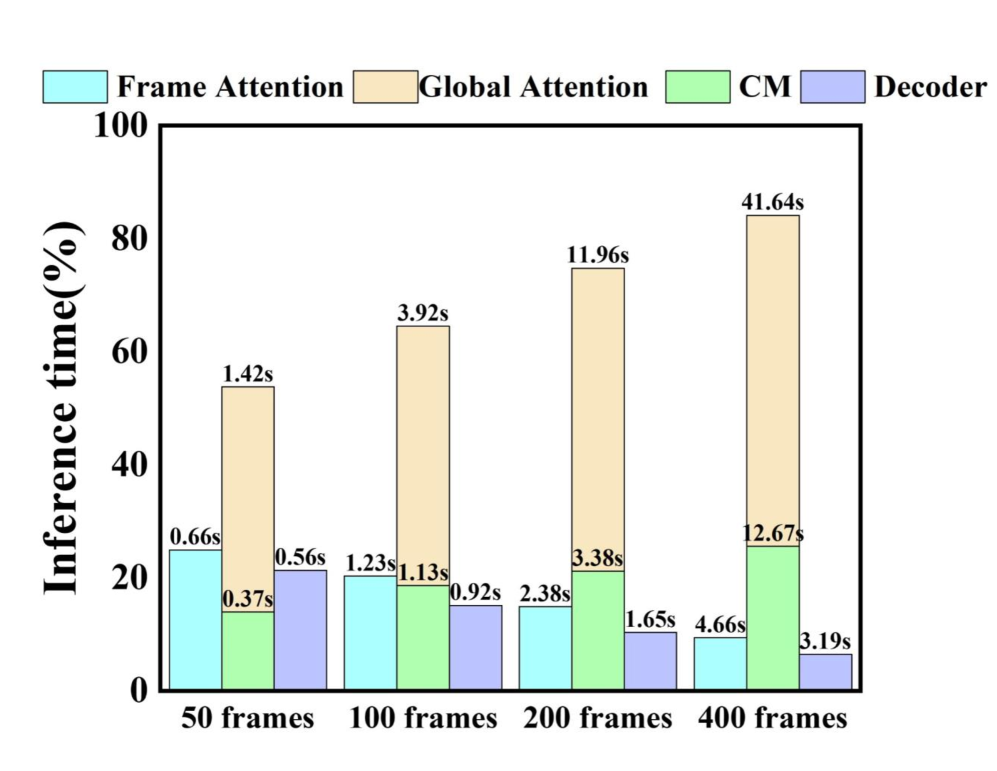
- 实验表明,LiteVGGT实现了高达10倍的加速和显著的内存减少,同时保持了VGGT的核心性能。
📝 摘要(中文)
视觉几何基础Transformer(VGGT)等3D视觉基础模型在几何感知方面取得了显著进展。然而,对于长序列而言,其计算耗时和内存占用较高,限制了其在数百张图像以上的大规模场景中的应用。为了解决这个问题,我们提出了LiteVGGT,实现了高达10倍的加速和显著的内存减少,从而能够高效地处理包含1000张图像的场景。我们为3D重建推导出了两个关键见解:(1)来自局部图像区域的token具有固有的几何相关性,导致高度相似性和计算冗余;(2)相邻网络层之间的token相似性保持稳定,从而允许重复使用合并决策。在这些见解的指导下,我们设计了一种简单而有效的策略,称为几何感知缓存token合并。我们分析每个token的几何重要性,优化anchor token的选择,以更好地保留用于重建的关键信息。我们还在各层之间缓存和重用合并索引,从而在最小化精度影响的同时显著降低延迟。该策略保留了VGGT的核心性能,从而能够进行高效的微调和FP8量化,以获得进一步的收益。大量的实验验证了LiteVGGT的有效性、可扩展性和鲁棒性。
🔬 方法详解
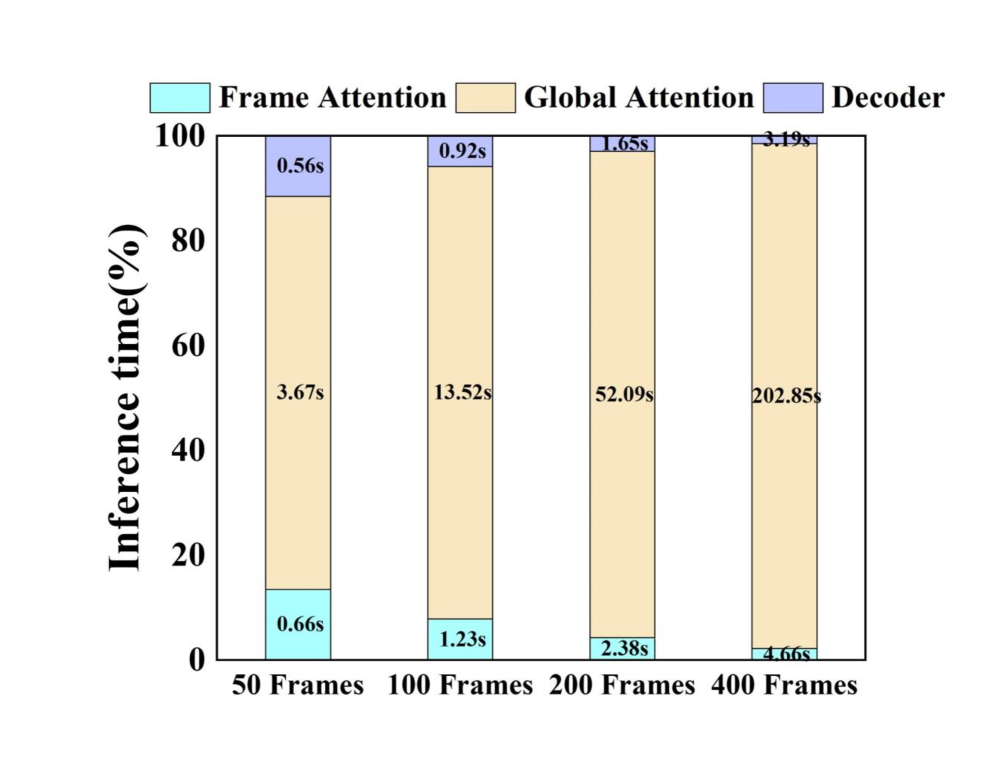
问题定义:VGGT等3D视觉模型在处理大规模场景(例如包含数百甚至上千张图像的场景)时,计算复杂度和内存需求非常高,严重限制了其应用范围。现有方法在处理长序列时效率低下,无法满足实际应用的需求。
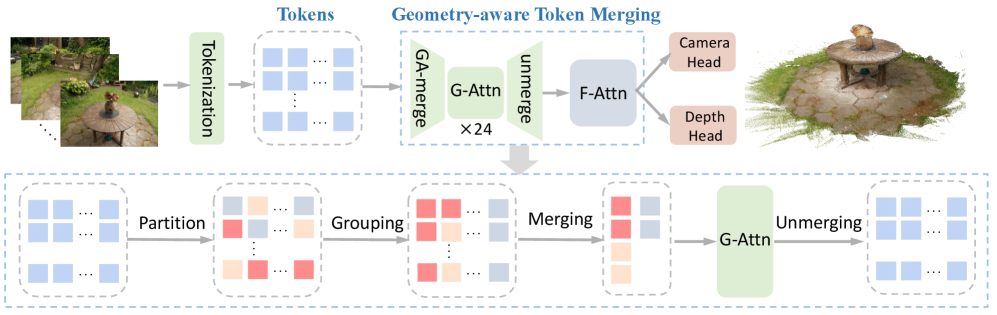
核心思路:LiteVGGT的核心思路是利用图像局部区域token的几何相关性和相邻网络层间token相似性的稳定性,通过几何感知的缓存token合并来减少计算冗余。具体来说,模型会分析每个token的几何重要性,并缓存和重用跨层的合并索引,从而加速计算过程。
技术框架:LiteVGGT的整体框架基于VGGT,并在其基础上引入了几何感知缓存Token合并模块。该模块主要包含两个阶段:1) 几何重要性分析与Anchor Token选择:分析每个token的几何重要性,选择更具代表性的Anchor Token;2) 跨层合并索引缓存与重用:在相邻层之间缓存和重用Token合并索引,避免重复计算。
关键创新:LiteVGGT的关键创新在于提出了几何感知的缓存Token合并策略。与传统的Token合并方法不同,LiteVGGT充分考虑了3D重建任务中token的几何特性,并利用层间token相似性的稳定性,实现了更高效的Token合并。
关键设计:在几何重要性分析方面,论文可能使用了某种几何先验信息(具体方法未知)来评估token的重要性。在Anchor Token选择方面,可能采用了某种采样策略(具体方法未知)来选择最具代表性的token。在跨层合并索引缓存方面,论文可能设置了缓存大小和更新策略(具体细节未知)。此外,论文还提到了可以进行FP8量化,这可能涉及到量化参数的选择和量化训练策略(具体细节未知)。
🖼️ 关键图片
📊 实验亮点
LiteVGGT实现了高达10倍的加速和显著的内存减少,使其能够高效地处理包含1000张图像的场景。该方法在保持VGGT核心性能的同时,还能够进行高效的微调和FP8量化,以获得进一步的收益。实验结果验证了LiteVGGT的有效性、可扩展性和鲁棒性。
🎯 应用场景
LiteVGGT的潜在应用领域包括大规模场景的3D重建、自动驾驶、机器人导航、虚拟现实和增强现实等。通过提高3D视觉模型的效率和可扩展性,LiteVGGT可以促进这些领域的发展,并为用户提供更流畅、更逼真的体验。该研究的实际价值在于降低了3D重建的计算成本和内存需求,使其能够应用于更广泛的场景。
📄 摘要(原文)
3D vision foundation models like Visual Geometry Grounded Transformer (VGGT) have advanced greatly in geometric perception. However, it is time-consuming and memory-intensive for long sequences, limiting application to large-scale scenes beyond hundreds of images. To address this, we propose LiteVGGT, achieving up to 10x speedup and substantial memory reduction, enabling efficient processing of 1000-image scenes. We derive two key insights for 3D reconstruction: (1) tokens from local image regions have inherent geometric correlations, leading to high similarity and computational redundancy; (2) token similarity across adjacent network layers remains stable, allowing for reusable merge decisions. Guided by these, we design a simple yet efficient strategy, dubbed geometry-aware cached token merging. We analyze each token's geometric importance, optimizing anchor token selection to better preserve key information for reconstruction. We also cache and reuse merge indices across layers, substantially reducing latency with minimal accuracy impact. This strategy retains VGGT's core performance, enabling efficient fine-tuning and FP8 quantization for further gains. Extensive experiments validate LiteVGGT's effectiveness, scalability, and robustness. Project page: https://garlicba.github.io/LiteVGGT/