E3AD: An Emotion-Aware Vision-Language-Action Model for Human-Centric End-to-End Autonomous Driving
作者: Yihong Tang, Haicheng Liao, Tong Nie, Junlin He, Ao Qu, Kehua Chen, Wei Ma, Zhenning Li, Lijun Sun, Chengzhong Xu
分类: cs.CV, cs.AI
发布日期: 2025-12-04
💡 一句话要点
E3AD:提出情感感知的端到端自动驾驶模型,提升人机交互体验
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端到端自动驾驶 情感感知 视觉语言动作模型 人机交互 空间推理
📋 核心要点
- 现有端到端自动驾驶系统忽略了乘客的情绪状态,导致人机交互体验不佳,影响用户接受度。
- E3AD框架通过引入VAD情绪模型和双路径空间推理模块,使自动驾驶系统能够理解乘客的情感并做出相应反应。
- 实验结果表明,E3AD在视觉定位、路径点规划和情绪估计方面均有提升,实现了更符合人类意图的驾驶行为。
📝 摘要(中文)
端到端自动驾驶(AD)系统越来越多地采用视觉-语言-动作(VLA)模型,但它们通常忽略了乘客的情绪状态,而情绪状态对于舒适性和AD接受度至关重要。本文提出了开放域端到端(OD-E2E)自动驾驶,其中自动驾驶汽车(AV)必须解释自由形式的自然语言命令,推断情绪,并规划物理上可行的轨迹。为此,本文提出了E3AD,一个情感感知的VLA框架,它通过两个认知启发组件来增强语义理解:一个连续的Valence-Arousal-Dominance (VAD)情绪模型,用于捕捉语言中的语气和紧迫性;以及一个双路径空间推理模块,用于融合自我中心和以环境为中心的视图,以实现类似人类的空间认知。一种面向一致性的训练方案,结合了模态预训练和基于偏好的对齐,进一步加强了情感意图和驾驶行为之间的一致性。在真实世界的数据集上,E3AD改进了视觉定位和路径点规划,并实现了情绪估计的最先进(SOTA) VAD相关性。这些结果表明,将情感注入VLA风格的驾驶可以产生更符合人类的定位、规划和以人为本的反馈。
🔬 方法详解
问题定义:现有端到端自动驾驶系统主要关注视觉信息和语言指令,缺乏对乘客情感的理解,导致驾驶行为可能与乘客的期望不符,影响乘坐舒适度和安全性。因此,如何让自动驾驶系统理解乘客的情感,并根据情感调整驾驶策略,是一个亟待解决的问题。
核心思路:E3AD的核心思路是将乘客的情感融入到自动驾驶系统的决策过程中。通过构建情感模型,系统可以从语言指令中提取情感信息,并将其与视觉信息融合,从而更好地理解乘客的意图。同时,采用双路径空间推理模块,模拟人类的空间认知方式,提高路径规划的合理性。
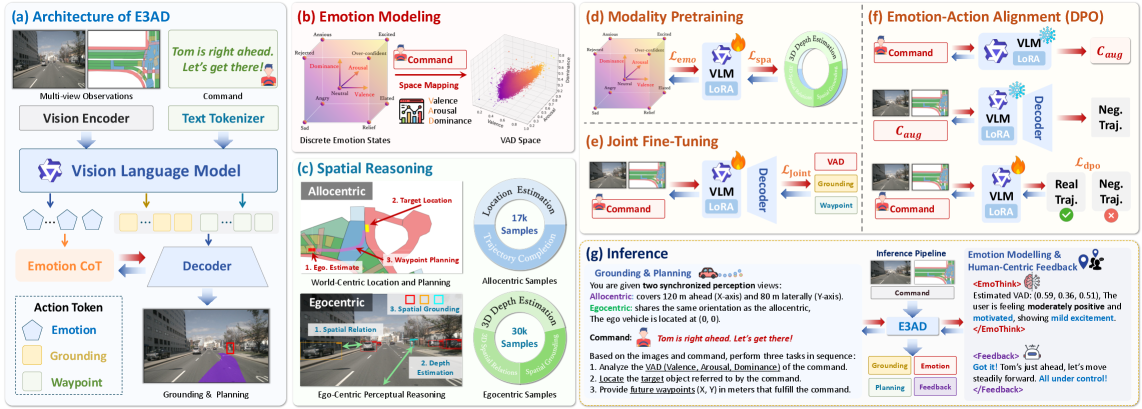
技术框架:E3AD框架主要包含以下几个模块:1) 视觉感知模块:负责从摄像头获取图像信息,并提取场景特征。2) 语言理解模块:负责解析自然语言指令,提取语义信息和情感信息。3) VAD情绪模型:将语言信息映射到连续的Valence-Arousal-Dominance (VAD)情感空间,捕捉语气和紧迫性。4) 双路径空间推理模块:融合自我中心和以环境为中心的视图,进行空间推理和路径规划。5) 动作执行模块:根据路径规划结果,控制车辆的行驶。
关键创新:E3AD的关键创新在于:1) 引入了VAD情绪模型,使系统能够理解乘客的情感。2) 提出了双路径空间推理模块,模拟人类的空间认知方式。3) 设计了一种面向一致性的训练方案,结合模态预训练和基于偏好的对齐,加强了情感意图和驾驶行为之间的一致性。
关键设计:VAD情绪模型使用预训练的语言模型(例如BERT)提取语言特征,然后通过回归模型预测VAD值。双路径空间推理模块包含两个分支:一个分支处理自我中心的视觉信息,另一个分支处理以环境为中心的地图信息。两个分支的输出通过注意力机制进行融合。面向一致性的训练方案使用对比学习损失,鼓励相似的情感意图对应相似的驾驶行为。
🖼️ 关键图片

📊 实验亮点
E3AD在真实世界数据集上进行了评估,结果表明,E3AD在视觉定位和路径点规划方面取得了显著的改进。此外,E3AD在情绪估计方面实现了最先进的(SOTA) VAD相关性,表明其能够准确地理解乘客的情感。实验结果还表明,将情感融入自动驾驶系统可以产生更符合人类意图的驾驶行为。
🎯 应用场景
E3AD技术可应用于各种自动驾驶场景,例如出租车、共享汽车和私人车辆。通过理解乘客的情感,自动驾驶系统可以提供更个性化、更舒适的驾驶体验,提高用户满意度和安全性。该技术还有潜力应用于人机交互的其他领域,例如智能家居和虚拟助手。
📄 摘要(原文)
End-to-end autonomous driving (AD) systems increasingly adopt vision-language-action (VLA) models, yet they typically ignore the passenger's emotional state, which is central to comfort and AD acceptance. We introduce Open-Domain End-to-End (OD-E2E) autonomous driving, where an autonomous vehicle (AV) must interpret free-form natural-language commands, infer the emotion, and plan a physically feasible trajectory. We propose E3AD, an emotion-aware VLA framework that augments semantic understanding with two cognitively inspired components: a continuous Valenc-Arousal-Dominance (VAD) emotion model that captures tone and urgency from language, and a dual-pathway spatial reasoning module that fuses egocentric and allocentric views for human-like spatial cognition. A consistency-oriented training scheme, combining modality pretraining with preference-based alignment, further enforces coherence between emotional intent and driving actions. Across real-world datasets, E3AD improves visual grounding and waypoint planning and achieves state-of-the-art (SOTA) VAD correlation for emotion estimation. These results show that injecting emotion into VLA-style driving yields more human-aligned grounding, planning, and human-centric feedback.