Towards Cross-View Point Correspondence in Vision-Language Models
作者: Yipu Wang, Yuheng Ji, Yuyang Liu, Enshen Zhou, Ziqiang Yang, Yuxuan Tian, Ziheng Qin, Yue Liu, Huajie Tan, Cheng Chi, Zhiyuan Ma, Daniel Dajun Zeng, Xiaolong Zheng
分类: cs.CV
发布日期: 2025-12-04 (更新: 2025-12-07)
🔗 代码/项目: GITHUB
💡 一句话要点
提出CrossPoint-Bench和CroPond模型,解决视觉语言模型中跨视角点对应难题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨视角对应 视觉语言模型 点云处理 具身智能 基准测试 数据集构建 坐标预测
📋 核心要点
- 现有视觉语言模型在跨视角点对应方面存在不足,尤其难以实现精确的点级对应,限制了其在具身智能中的应用。
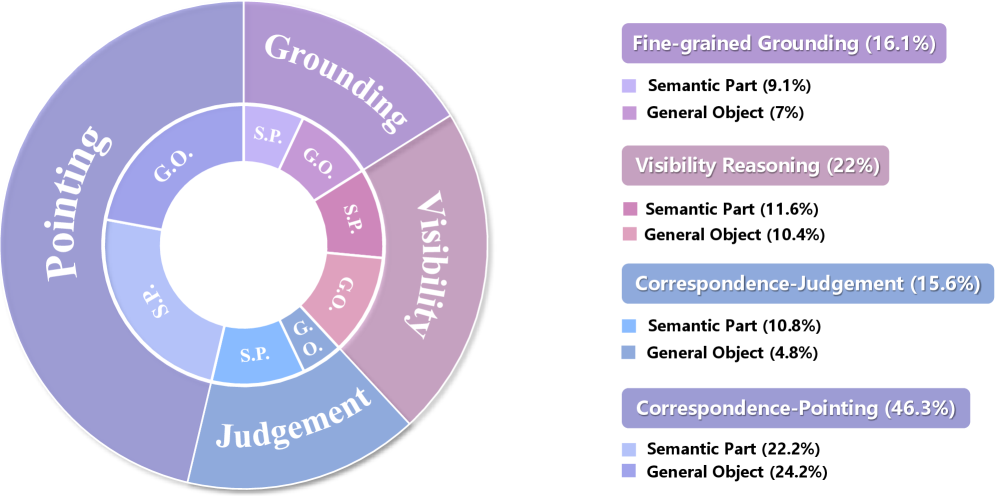
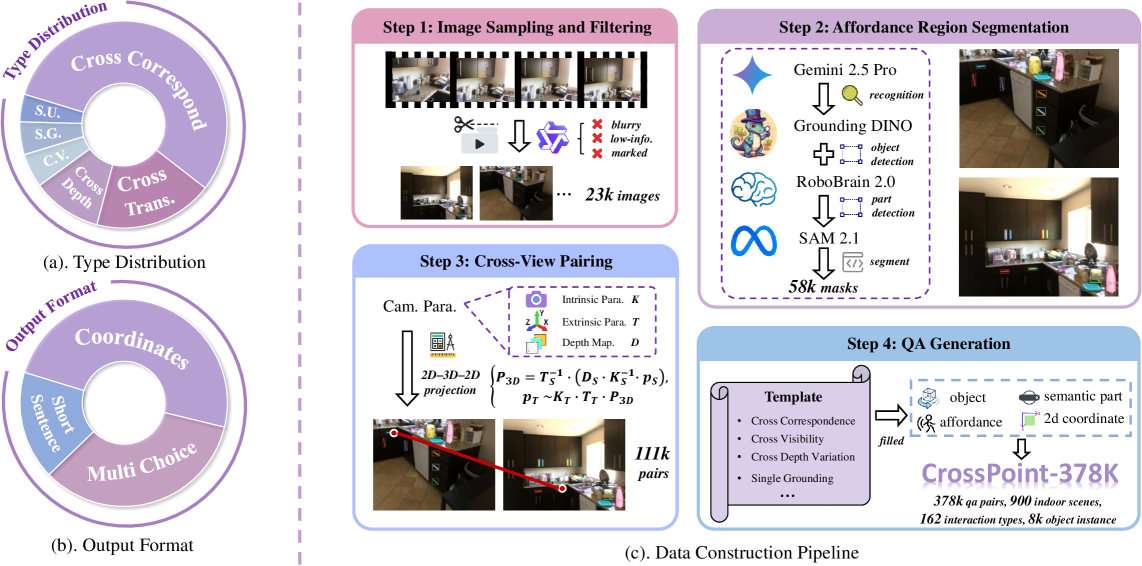
- 论文提出CrossPoint-Bench基准测试和CrossPoint-378K数据集,并设计CroPond模型,专注于可操作区域的细粒度坐标预测。
- 实验结果表明,CroPond模型在CrossPoint-Bench上显著优于现有模型,例如Gemini-2.5-Pro,准确率提升了39.7%。
📝 摘要(中文)
跨视角对应是空间理解和具身智能的一项基本能力。然而,视觉语言模型(VLMs)在这方面仍有不足,尤其是在实现精确的点级对应方面,这对于精确的交互至关重要。因此,我们提出了跨视角点对应(CVPC)任务和CrossPoint-Bench,这是一个综合性的基准,其分层设计灵感来源于人类“感知”、“推理”和“对应”的认知过程。我们的评估表明,最先进的模型(例如,Gemini-2.5-Pro)仍然远远落后于人类,总体准确率差距超过54.65%,这暴露了从粗粒度判断到细粒度坐标预测的挑战。为了解决这个问题,我们构建了CrossPoint-378K数据集,其中包含900个场景的378K个问答对,重点关注可操作的活动区域,以更好地反映现实世界的操作和交互场景。此外,我们提出了在CrossPoint-378K数据集上训练的CroPond。我们的CroPond在CrossPoint-Bench上实现了最先进的性能,准确率超过Gemini-2.5-Pro 39.7%,这为推进未来跨视角对应研究奠定了基础。该基准、数据集和模型已在https://github.com/WangYipu2002/CrossPoint公开发布。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLMs)在跨视角点对应任务中的不足,特别是精确的点级对应问题。现有方法难以从粗粒度判断过渡到细粒度坐标预测,导致在需要精确交互的具身智能任务中表现不佳。
核心思路:论文的核心思路是通过构建大规模数据集CrossPoint-378K,并在此基础上训练CroPond模型,从而提升VLM在跨视角场景下的点对应能力。数据集专注于可操作的活动区域,模型设计侧重于细粒度坐标预测。
技术框架:整体框架包含三个主要部分:1) CrossPoint-Bench基准测试,用于评估模型性能;2) CrossPoint-378K数据集,包含大量跨视角问答对,用于模型训练;3) CroPond模型,基于VLM架构,针对跨视角点对应任务进行优化。
关键创新:论文的关键创新在于构建了CrossPoint-378K数据集,该数据集专注于可操作区域,更贴近现实世界的交互场景。此外,CroPond模型的设计也针对性地解决了从粗粒度判断到细粒度坐标预测的难题。
关键设计:CrossPoint-378K数据集包含900个场景的378K个问答对,涵盖多种操作和交互类型。CroPond模型的具体网络结构和训练细节(如损失函数、优化器等)在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
CroPond模型在CrossPoint-Bench基准测试中取得了显著的性能提升,超越了当前最先进的模型Gemini-2.5-Pro 39.7%的准确率。这一结果表明,通过构建针对性的数据集和优化模型结构,可以有效提升VLM在跨视角点对应任务中的表现。
🎯 应用场景
该研究成果可应用于机器人导航、物体操作、增强现实等领域。通过提升视觉语言模型在跨视角场景下的空间理解能力,可以使机器人更准确地理解人类指令,并执行复杂的交互任务。未来,该技术有望推动具身智能的发展,实现更智能、更自然的机器人助手。
📄 摘要(原文)
Cross-view correspondence is a fundamental capability for spatial understanding and embodied AI. However, it is still far from being realized in Vision-Language Models (VLMs), especially in achieving precise point-level correspondence, which is crucial for precise affordance interaction. So we propose the Cross-View Point Correspondence (CVPC) task and CrossPoint-Bench, a comprehensive benchmark with hierarchical design, inspired by the human cognitive process of "perceive", "reason", and "correspond". Our evaluation shows the state-of-the-art models (e.g., Gemini-2.5-Pro) still fall far behind humans, with a gap of over 54.65% in overall accuracy, exposing a challenge in transitioning from coarse-grained judgement to fine-grained coordinate prediction. To address this problem, we construct CrossPoint-378K, a dataset with 378K question-answering pairs across 900 scenes, focused on actionable affordance regions that better reflect real-world manipulation and interaction scenarios. Furthermore, we propose CroPond that trained on the CrossPoint-378K dataset. Our CroPond achieves state-of-the-art performance on CrossPoint-Bench, surpassing Gemini-2.5-Pro by 39.7% accuracy, which offers a foundation for advancing future work on cross-view correspondence. The benchmark, dataset, and model are publicly available at https://github.com/WangYipu2002/CrossPoint.