Reward Forcing: Efficient Streaming Video Generation with Rewarded Distribution Matching Distillation
作者: Yunhong Lu, Yanhong Zeng, Haobo Li, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Jiapeng Zhu, Hengyuan Cao, Zhipeng Zhang, Xing Zhu, Yujun Shen, Min Zhang
分类: cs.CV
发布日期: 2025-12-04 (更新: 2025-12-28)
💡 一句话要点
提出Reward Forcing框架,高效生成高质量流式视频,解决初始帧复制和动态不足问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 流式视频生成 视频扩散模型 蒸馏训练 滑动窗口注意力 长时一致性 运动动态 奖励机制 EMA-Sink
📋 核心要点
- 现有流式视频生成方法依赖初始帧作为静态tokens,导致后续帧复制初始帧,运动动态不足。
- 提出Reward Forcing框架,包含EMA-Sink和Re-DMD,分别解决长时一致性和运动动态不足的问题。
- 实验表明,Reward Forcing在标准基准测试中达到SOTA性能,并在单个H100 GPU上实现23.1 FPS。
📝 摘要(中文)
本文提出Reward Forcing框架,旨在高效生成流式视频。现有方法使用滑动窗口注意力机制蒸馏少步视频扩散模型,并采用初始帧作为sink tokens以维持注意力和减少误差累积,但导致视频帧过度依赖静态tokens,出现初始帧复制和运动动态减弱的问题。Reward Forcing包含两个关键设计:EMA-Sink,通过指数移动平均融合移出滑动窗口的tokens,持续更新固定大小的tokens,捕捉长期上下文和近期动态,避免初始帧复制并保持长时一致性;Rewarded Distribution Matching Distillation (Re-DMD),通过视觉-语言模型评估动态程度,偏置模型输出分布到高奖励区域,优先处理动态内容,显著提升运动质量并保持数据保真度。实验结果表明,Reward Forcing在标准基准测试中达到SOTA性能,并在单个H100 GPU上实现23.1 FPS的高质量流式视频生成。
🔬 方法详解
问题定义:现有流式视频生成方法,特别是基于滑动窗口注意力机制的蒸馏方法,为了保持长时一致性和减少误差累积,通常会将初始帧作为sink tokens。然而,这种做法导致后续生成的视频帧过度依赖这些静态的初始帧tokens,从而出现初始帧复制的现象,并且削弱了视频的运动动态,使得生成的视频缺乏真实感和多样性。
核心思路:Reward Forcing的核心思路是通过两个关键组件来解决上述问题:一是EMA-Sink,它动态地更新sink tokens,使其能够捕捉到长时上下文和近期的运动信息,从而避免过度依赖初始帧;二是Rewarded Distribution Matching Distillation (Re-DMD),它通过奖励机制来引导模型更加关注和学习视频中的动态部分,从而提升运动质量。
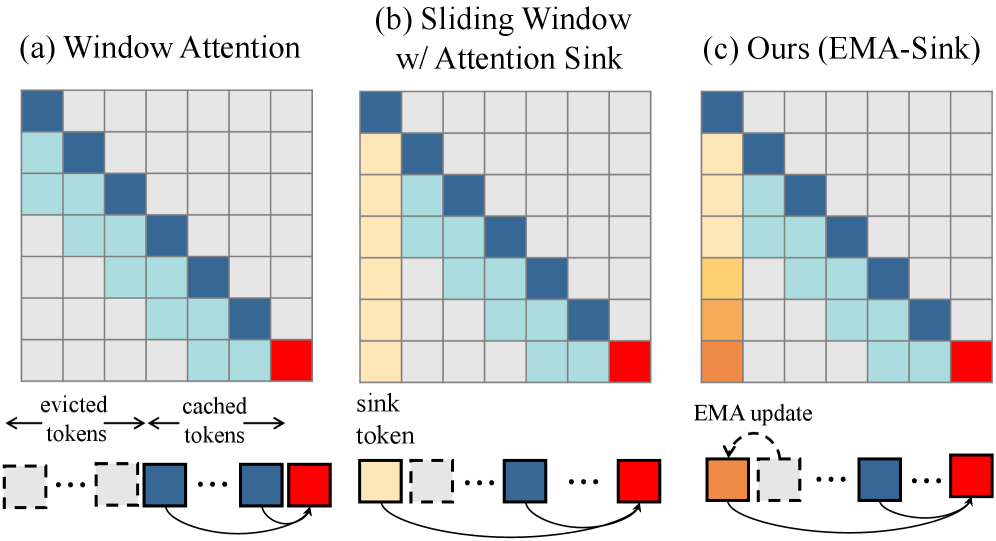
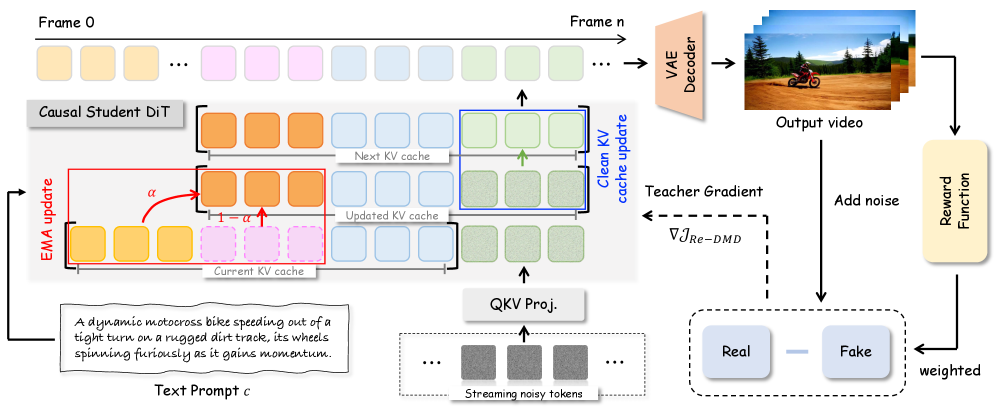
技术框架:Reward Forcing框架主要包含两个模块:EMA-Sink和Re-DMD。EMA-Sink负责维护一组固定大小的tokens,这些tokens从初始帧初始化,并随着滑动窗口的移动,不断地通过指数移动平均(EMA)融合移出窗口的tokens进行更新。Re-DMD则是在蒸馏训练过程中,利用视觉-语言模型评估视频帧的动态程度,并根据动态程度赋予不同的奖励,从而引导学生模型学习教师模型在动态区域的分布。整体流程是先使用EMA-Sink生成视频帧,然后使用Re-DMD进行蒸馏训练,提升运动质量。
关键创新:Reward Forcing的关键创新在于EMA-Sink和Re-DMD的结合。EMA-Sink通过动态更新sink tokens,避免了初始帧复制的问题,而Re-DMD则通过奖励机制,使得模型能够更加关注和学习视频中的动态部分。与现有方法相比,Reward Forcing能够更好地平衡长时一致性和运动动态,从而生成更高质量的流式视频。
关键设计:EMA-Sink的关键设计在于指数移动平均的融合方式,它能够平滑地将移出窗口的tokens的信息融入到现有的tokens中,从而保持tokens的连续性和一致性。Re-DMD的关键设计在于奖励函数的选择,论文使用视觉-语言模型来评估视频帧的动态程度,并根据动态程度赋予不同的奖励。具体的损失函数设计未知,但可以推测是加权KL散度或类似形式,动态程度高的样本权重更高。
🖼️ 关键图片

📊 实验亮点
Reward Forcing在标准基准测试中取得了SOTA性能,并且在单个H100 GPU上实现了23.1 FPS的高质量流式视频生成。相较于现有方法,Reward Forcing能够显著提升视频的运动质量和长时一致性,有效避免初始帧复制的问题,生成更加真实和自然的视频。
🎯 应用场景
Reward Forcing在交互式动态世界模拟、游戏开发、虚拟现实、视频会议等领域具有广泛的应用前景。该技术能够生成高质量、长时一致且运动自然的流式视频,为用户提供更加沉浸式和真实的体验。此外,该技术还可以应用于数据增强、视频编辑等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Efficient streaming video generation is critical for simulating interactive and dynamic worlds. Existing methods distill few-step video diffusion models with sliding window attention, using initial frames as sink tokens to maintain attention performance and reduce error accumulation. However, video frames become overly dependent on these static tokens, resulting in copied initial frames and diminished motion dynamics. To address this, we introduce Reward Forcing, a novel framework with two key designs. First, we propose EMA-Sink, which maintains fixed-size tokens initialized from initial frames and continuously updated by fusing evicted tokens via exponential moving average as they exit the sliding window. Without additional computation cost, EMA-Sink tokens capture both long-term context and recent dynamics, preventing initial frame copying while maintaining long-horizon consistency. Second, to better distill motion dynamics from teacher models, we propose a novel Rewarded Distribution Matching Distillation (Re-DMD). Vanilla distribution matching treats every training sample equally, limiting the model's ability to prioritize dynamic content. Instead, Re-DMD biases the model's output distribution toward high-reward regions by prioritizing samples with greater dynamics rated by a vision-language model. Re-DMD significantly enhances motion quality while preserving data fidelity. We include both quantitative and qualitative experiments to show that Reward Forcing achieves state-of-the-art performance on standard benchmarks while enabling high-quality streaming video generation at 23.1 FPS on a single H100 GPU.