SEASON: Mitigating Temporal Hallucination in Video Large Language Models via Self-Diagnostic Contrastive Decoding
作者: Chang-Hsun Wu, Kai-Po Chang, Yu-Yang Sheng, Hung-Kai Chung, Kuei-Chun Wang, Yu-Chiang Frank Wang
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-12-04
💡 一句话要点
提出SEASON,通过自诊断对比解码缓解视频大语言模型中的时间幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 时间幻觉 对比解码 自诊断 视频理解
📋 核心要点
- 现有VideoLLM在时间推理方面存在不足,导致生成内容时序不一致,产生幻觉。
- 提出SEASON方法,通过自诊断每个token的幻觉倾向,并进行对比解码,增强时空保真度。
- 实验表明,SEASON在多个基准测试中优于现有无训练方法,并在通用视频理解任务中有所提升。
📝 摘要(中文)
视频大语言模型(VideoLLMs)在视频理解方面取得了显著进展。然而,在响应用户查询时,这些模型仍然难以有效地感知和利用视频中丰富的时序信息。因此,它们经常生成时间上不一致或因果关系上不合理的事件描述,导致严重的幻觉问题。虽然大多数先前的研究都集中在空间幻觉(例如,对象不匹配)上,但视频理解中的时间推理仍然相对未被探索。为了解决这个问题,我们提出了一种自诊断对比解码(SEASON),这是一种无需训练的方法,可以自适应地增强每个输出token的时间和空间保真度。它通过动态诊断每个token的幻觉倾向,并对其相应的时间和空间负例应用自适应对比解码来实现这一点。大量的实验表明,SEASON在三个幻觉检查基准上优于所有现有的无训练幻觉缓解方法,同时进一步提高了VideoLLM在四个通用视频理解基准上的性能。代码将在接受后发布。
🔬 方法详解
问题定义:VideoLLM在视频理解中面临时间幻觉问题,即生成的描述在时间上不一致或因果关系不合理。现有方法主要关注空间幻觉,忽略了视频中重要的时序信息,导致模型无法有效利用视频中的时间上下文进行推理。
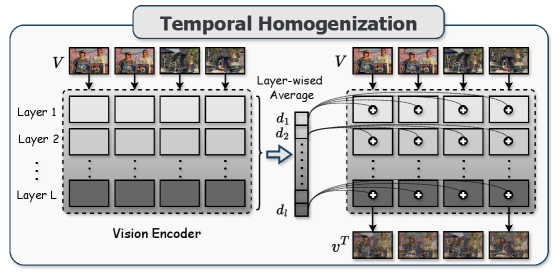
核心思路:SEASON的核心思路是通过自诊断和对比解码来缓解时间幻觉。具体来说,对于生成的每个token,模型会诊断其产生幻觉的倾向,然后利用时间和空间上的负例进行对比解码,从而增强token的时空一致性。这种方法无需额外训练,可以灵活地应用于各种VideoLLM。
技术框架:SEASON主要包含两个阶段:自诊断阶段和对比解码阶段。在自诊断阶段,模型评估当前token产生幻觉的可能性。在对比解码阶段,模型利用自诊断的结果,选择合适的时间和空间负例,并进行对比解码,从而生成更符合时序和空间一致性的token。整个过程是动态的,每个token都会根据其自身的特性进行调整。
关键创新:SEASON的关键创新在于提出了自诊断对比解码的框架,能够动态地评估每个token的幻觉倾向,并自适应地选择合适的负例进行对比解码。与现有方法相比,SEASON更加关注时间推理,并且无需额外的训练,具有更好的灵活性和适用性。
关键设计:SEASON的关键设计包括:1) 自诊断模块,用于评估token的幻觉倾向;2) 时间负例和空间负例的选择策略,用于构建对比解码的负样本;3) 自适应对比解码的权重调整策略,用于平衡不同负例的影响。具体的参数设置和网络结构细节将在论文的后续版本中公布。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SEASON在三个幻觉检查基准上优于所有现有的无训练幻觉缓解方法。同时,SEASON还在四个通用视频理解基准上进一步提高了VideoLLM的性能。这些结果验证了SEASON在缓解时间幻觉和提升视频理解能力方面的有效性。
🎯 应用场景
SEASON方法可广泛应用于各种需要视频理解和生成任务的场景,例如视频摘要、视频问答、视频编辑和智能监控等。通过减少时间幻觉,可以提高生成内容的质量和可靠性,从而提升用户体验和应用价值。未来,该方法有望进一步扩展到其他多模态任务中,例如音视频理解和跨模态生成。
📄 摘要(原文)
Video Large Language Models (VideoLLMs) have shown remarkable progress in video understanding. However, these models still struggle to effectively perceive and exploit rich temporal information in videos when responding to user queries. Therefore, they often generate descriptions of events that are temporal inconsistent or causally implausible, causing severe hallucination issues. While most prior studies have focused on spatial hallucinations (e.g. object mismatches), temporal reasoning in video understanding remains relatively underexplored. To address this issue, we propose Self-Diagnostic Contrastive Decoding (SEASON), a training-free method that adaptively enhances temporal and spatial faithfulness for each output token. It achieves this by dynamically diagnosing each token's hallucination tendency and applying adaptive contrastive decoding against its corresponding temporal and spatial negatives. Extensive experiments demonstrate that SEASON outperforms all existing training-free hallucination mitigation approaches on three hallucination examination benchmarks, while further improves VideoLLMs across four general video understanding benchmarks. The code will be released upon acceptance.