Malicious Image Analysis via Vision-Language Segmentation Fusion: Detection, Element, and Location in One-shot
作者: Sheng Hang, Chaoxiang He, Hongsheng Hu, Hanqing Hu, Bin Benjamin Zhu, Shi-Feng Sun, Dawu Gu, Shuo Wang
分类: cs.CV
发布日期: 2025-12-04
💡 一句话要点
提出基于视觉-语言分割融合的恶意图像分析方法,实现一步到位的内容检测、元素识别和定位。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 恶意图像分析 视觉-语言模型 图像分割 零样本学习 内容审核
📋 核心要点
- 现有恶意图像检测方法通常仅提供图像级别的NSFW标志,缺乏对有害元素及其位置的精细化分析。
- 该论文提出一种零样本流程,通过视觉-语言分割融合,一步到位地检测恶意内容、识别关键元素并精确定位。
- 实验表明,该方法在恶意内容检测的召回率、精确率和分割成功率上均有显著提升,并对对抗攻击具有较强的鲁棒性。
📝 摘要(中文)
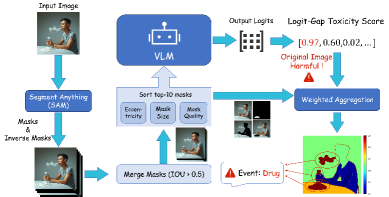
本文提出了一种零样本恶意图像分析流程,能够同时完成三个任务:(i) 检测图像是否包含有害内容,(ii) 识别图像中涉及的关键元素,以及 (iii) 以像素级精度定位这些元素。该系统首先应用基础分割模型(SAM)生成候选对象掩码,并将其细化为更大的独立区域。然后,使用视觉-语言模型和开放词汇提示对每个区域进行恶意相关性评分;这些分数用于加权融合步骤,生成统一的恶意对象图。通过集成多个分割器,增强了流程对针对单一分割方法的自适应攻击的抵抗能力。在包含毒品、性、暴力和极端主义内容的790张图像的新注释数据集上进行评估,该方法达到了85.8%的元素级召回率、78.1%的精确率和92.1%的分割成功率,在可比的精确率下,超过了直接零样本VLM定位27.4%的召回率。针对旨在破坏SAM和VLM的PGD对抗扰动,该方法的精确率和召回率下降不超过10%,表现出很高的鲁棒性。完整的流程在几秒钟内处理一张图像,无缝地插入到现有的VLM工作流程中,并构成了第一个用于细粒度、可解释的恶意图像审核的实用工具。
🔬 方法详解
问题定义:现有恶意图像检测方法主要集中在图像级别的分类,无法提供图像中哪些元素导致恶意以及这些元素在图像中的具体位置。这使得人工审核员难以理解和验证检测结果,也限制了模型的解释性和可信度。此外,现有方法容易受到对抗攻击的影响,鲁棒性较差。
核心思路:该论文的核心思路是利用视觉-语言模型的开放词汇能力和分割模型的像素级定位能力,通过融合两种模态的信息,实现对恶意图像的细粒度分析。具体来说,首先使用分割模型提取图像中的候选对象,然后使用视觉-语言模型判断这些对象是否与恶意内容相关,最后将分割结果和视觉-语言模型的判断结果融合,生成恶意对象图。
技术框架:该方法包含以下几个主要模块:1) 候选对象分割:使用SAM等分割模型生成候选对象掩码,并进行后处理以获得独立的区域。2) 恶意相关性评分:使用视觉-语言模型(如CLIP)对每个区域进行评分,判断其与恶意内容的相关性。评分过程使用开放词汇提示,例如“包含毒品的图像”、“包含性内容的图像”等。3) 融合:将分割结果和视觉-语言模型的评分结果进行融合,生成恶意对象图。融合过程使用加权平均等方法,根据视觉-语言模型的评分调整分割结果的权重。4) 集成:为了提高鲁棒性,使用多个不同的分割模型,并将它们的分割结果进行集成。
关键创新:该方法最重要的技术创新点在于将视觉-语言模型和分割模型进行融合,从而实现了对恶意图像的细粒度分析。与现有方法相比,该方法不仅可以检测图像是否包含恶意内容,还可以识别图像中涉及的关键元素,并精确定位这些元素。此外,该方法还通过集成多个分割模型,提高了对对抗攻击的鲁棒性。
关键设计:在候选对象分割阶段,使用了SAM模型,并对分割结果进行了后处理,以获得更大的独立区域。在恶意相关性评分阶段,使用了CLIP模型,并使用了开放词汇提示。在融合阶段,使用了加权平均的方法,根据CLIP模型的评分调整分割结果的权重。在集成阶段,使用了多个不同的分割模型,并将它们的分割结果进行平均。
🖼️ 关键图片


📊 实验亮点
该方法在包含毒品、性、暴力和极端主义内容的790张图像数据集上进行了评估,达到了85.8%的元素级召回率、78.1%的精确率和92.1%的分割成功率。与直接使用零样本VLM定位相比,该方法在可比的精确率下,召回率提高了27.4%。针对PGD对抗扰动,该方法的精确率和召回率下降不超过10%,表现出很高的鲁棒性。
🎯 应用场景
该研究成果可应用于各种在线平台的内容审核,例如社交媒体、电商平台和搜索引擎。它可以帮助审核员快速识别和处理包含恶意内容的图像,提高审核效率和准确性。此外,该方法还可以用于训练更鲁棒的恶意图像检测模型,并为用户提供更安全、更健康的网络环境。
📄 摘要(原文)
Detecting illicit visual content demands more than image-level NSFW flags; moderators must also know what objects make an image illegal and where those objects occur. We introduce a zero-shot pipeline that simultaneously (i) detects if an image contains harmful content, (ii) identifies each critical element involved, and (iii) localizes those elements with pixel-accurate masks - all in one pass. The system first applies foundation segmentation model (SAM) to generate candidate object masks and refines them into larger independent regions. Each region is scored for malicious relevance by a vision-language model using open-vocabulary prompts; these scores weight a fusion step that produces a consolidated malicious object map. An ensemble across multiple segmenters hardens the pipeline against adaptive attacks that target any single segmentation method. Evaluated on a newly-annotated 790-image dataset spanning drug, sexual, violent and extremist content, our method attains 85.8% element-level recall, 78.1% precision and a 92.1% segment-success rate - exceeding direct zero-shot VLM localization by 27.4% recall at comparable precision. Against PGD adversarial perturbations crafted to break SAM and VLM, our method's precision and recall decreased by no more than 10%, demonstrating high robustness against attacks. The full pipeline processes an image in seconds, plugs seamlessly into existing VLM workflows, and constitutes the first practical tool for fine-grained, explainable malicious-image moderation.