COOPER: A Unified Model for Cooperative Perception and Reasoning in Spatial Intelligence
作者: Zefeng Zhang, Xiangzhao Hao, Hengzhu Tang, Zhenyu Zhang, Jiawei Sheng, Xiaodong Li, Zhenyang Li, Li Gao, Daiting Shi, Dawei Yin, Tingwen Liu
分类: cs.CV
发布日期: 2025-12-04 (更新: 2025-12-05)
💡 一句话要点
COOPER:用于空间智能中协同感知与推理的统一模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 空间推理 协同感知 深度估计 语义分割
📋 核心要点
- 现有MLLM在3D空间推理方面存在不足,通常孤立地增强感知或推理能力。
- COOPER提出一个统一的MLLM,通过辅助模态生成和自适应交错推理来增强空间智能。
- 实验表明,COOPER在空间推理方面取得了显著提升,即使仅训练辅助模态生成也能提高距离和大小估计的准确性。
📝 摘要(中文)
视觉空间推理对于使多模态大型语言模型(MLLM)理解物体属性和空间关系至关重要,但当前的模型在3D感知推理方面仍然存在困难。现有方法通常孤立地增强感知(通过用深度和分割等辅助模态增强RGB输入)或推理(通过在空间VQA数据集上训练和应用强化学习)。本文研究了一个统一的MLLM是否能够发展出增强空间感知的内在能力,并通过自适应交错推理来实现更强的空间智能。我们提出了COOPER,一个利用深度和分割作为辅助模态的统一MLLM,并通过两个阶段的训练来获得辅助模态生成和自适应交错推理能力。COOPER在空间推理方面平均提高了6.91%,同时保持了一般的性能。此外,即使仅针对辅助模态生成进行训练的变体在距离和大小估计方面也获得了7.92%的提升,这表明学习生成辅助模态有助于内化空间知识并加强空间理解。
🔬 方法详解
问题定义:当前的多模态大型语言模型(MLLM)在理解3D空间关系和进行精确的空间推理方面存在困难。现有的方法通常将感知和推理两个方面割裂开来,要么侧重于通过引入深度信息或分割信息等辅助模态来增强感知能力,要么侧重于通过在特定的空间视觉问答(VQA)数据集上进行训练或使用强化学习等方法来提升推理能力。这些方法未能充分利用感知和推理之间的协同作用,导致模型在复杂空间场景下的表现受限。
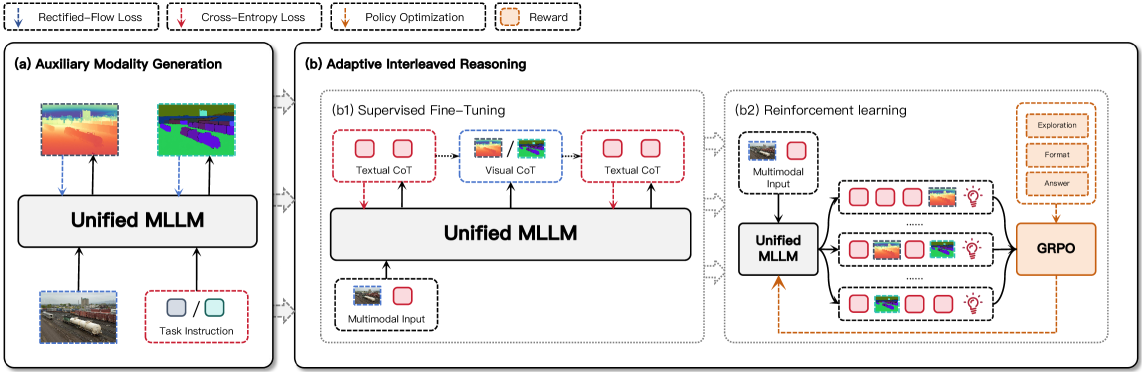
核心思路:COOPER的核心思路是构建一个统一的MLLM,使其能够同时学习增强空间感知和进行自适应交错推理。通过将深度和分割等辅助模态融入到模型中,COOPER能够更全面地理解场景的几何信息和物体之间的关系。此外,COOPER采用了一种自适应交错推理机制,允许模型在感知和推理之间动态切换,从而更好地利用感知信息来指导推理过程,并根据推理结果反过来调整感知策略。
技术框架:COOPER的整体框架包含两个主要的训练阶段。第一阶段是辅助模态生成阶段,该阶段的目标是让模型学习根据RGB图像生成对应的深度图和分割图。这可以通过使用生成对抗网络(GAN)或变分自编码器(VAE)等技术来实现。第二阶段是自适应交错推理阶段,该阶段的目标是让模型学习如何利用生成的辅助模态信息来进行空间推理。这可以通过在空间VQA数据集上进行训练来实现,同时引入一种自适应机制来控制感知和推理之间的切换。
关键创新:COOPER最重要的技术创新点在于其统一的架构和自适应交错推理机制。与以往将感知和推理分开处理的方法不同,COOPER将两者整合到一个统一的模型中,从而能够更好地利用感知和推理之间的协同作用。此外,COOPER的自适应交错推理机制允许模型根据当前的任务和场景动态调整感知和推理的权重,从而提高了模型的灵活性和适应性。
关键设计:在辅助模态生成阶段,COOPER可以使用条件GAN,其中RGB图像作为条件输入,深度图和分割图作为生成目标。损失函数可以包括对抗损失、像素级重建损失和感知损失等。在自适应交错推理阶段,COOPER可以使用Transformer架构,并引入一个门控机制来控制感知和推理之间的切换。门控机制的输入可以是当前的状态和任务描述,输出是一个介于0和1之间的值,表示感知的权重。损失函数可以包括VQA损失和正则化损失,用于鼓励模型学习有效的自适应策略。
🖼️ 关键图片


📊 实验亮点
COOPER在空间推理任务上取得了显著的性能提升,平均提高了6.91%。更令人惊讶的是,即使仅训练辅助模态生成模块,COOPER在距离和大小估计任务上也获得了7.92%的提升。这表明学习生成辅助模态能够有效地内化空间知识,从而增强模型的空间理解能力。这些结果表明COOPER在空间智能方面具有巨大的潜力。
🎯 应用场景
COOPER模型在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。通过增强机器对周围环境的感知和理解能力,COOPER可以帮助机器人更好地完成导航、物体识别、场景理解等任务。在自动驾驶领域,COOPER可以提高车辆对复杂交通场景的感知能力,从而提高驾驶安全性。在增强现实领域,COOPER可以帮助用户更自然地与虚拟环境进行交互。
📄 摘要(原文)
Visual Spatial Reasoning is crucial for enabling Multimodal Large Language Models (MLLMs) to understand object properties and spatial relationships, yet current models still struggle with 3D-aware reasoning. Existing approaches typically enhance either perception, by augmenting RGB inputs with auxiliary modalities such as depth and segmentation, or reasoning, by training on spatial VQA datasets and applying reinforcement learning, and thus treat these two aspects in isolation. In this work, we investigate whether a unified MLLM can develop an intrinsic ability to enhance spatial perception and, through adaptive interleaved reasoning, achieve stronger spatial intelligence. We propose \textbf{COOPER}, a unified MLLM that leverages depth and segmentation as auxiliary modalities and is trained in two stages to acquire auxiliary modality generation and adaptive, interleaved reasoning capabilities. COOPER achieves an average \textbf{6.91\%} improvement in spatial reasoning while maintaining general performance. Moreover, even a variant trained only for auxiliary modality generation attains a \textbf{7.92\%} gain on distance and size estimation, suggesting that learning to generate auxiliary modalities helps internalize spatial knowledge and strengthen spatial understanding.