X-Humanoid: Robotize Human Videos to Generate Humanoid Videos at Scale
作者: Pei Yang, Hai Ci, Yiren Song, Mike Zheng Shou
分类: cs.CV
发布日期: 2025-12-04
💡 一句话要点
X-Humanoid:通过机器人化人类视频大规模生成类人机器人视频
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人化 视频生成 类人机器人 具身智能 数据合成 视频编辑 Wan模型 Unreal Engine
📋 核心要点
- 现有方法主要针对第一人称视角,无法有效处理第三人称视频中复杂的全身运动和遮挡问题,限制了其在机器人领域的应用。
- X-Humanoid通过将强大的Wan 2.2模型改造为视频到视频的结构,并针对人类到类人机器人的转换任务进行微调,实现人类视频的机器人化。
- 通过Unreal Engine生成大规模配对合成数据,并将其应用于Ego-Exo4D视频,生成包含超过360万帧的大规模机器人化类人机器人视频数据集。
📝 摘要(中文)
具身智能的进步释放了智能类人机器人的巨大潜力。然而,视觉-语言-动作(VLA)模型和世界模型的进展受到大规模、多样化训练数据稀缺的严重阻碍。一个有前景的解决方案是“机器人化”网络规模的人类视频,这已被证明对策略训练有效。然而,这些解决方案主要将机器人手臂“覆盖”到以自我为中心的视频上,无法处理第三人称视频中复杂的全身运动和场景遮挡,使其不适合机器人化人类。为了弥合这一差距,我们引入了X-Humanoid,一种生成式视频编辑方法,它将强大的Wan 2.2模型适配到视频到视频的结构中,并对其进行微调以完成人类到类人机器人的转换任务。这种微调需要配对的人类-类人机器人视频,因此我们设计了一个可扩展的数据创建流程,使用Unreal Engine将社区资产转换为超过17小时的配对合成视频。然后,我们将训练好的模型应用于60小时的Ego-Exo4D视频,生成并发布了一个包含超过360万帧“机器人化”类人机器人视频的大规模新数据集。定量分析和用户研究证实了我们的方法优于现有的基线:69%的用户认为它在运动一致性方面表现最佳,62.1%的用户认为它在具身正确性方面表现最佳。
🔬 方法详解
问题定义:论文旨在解决现有方法无法有效将人类视频转换为类人机器人视频的问题,尤其是在处理第三人称视角、复杂全身运动和场景遮挡时。现有方法主要依赖于将机器人手臂叠加到第一人称视角视频上,无法满足更广泛的机器人应用需求。
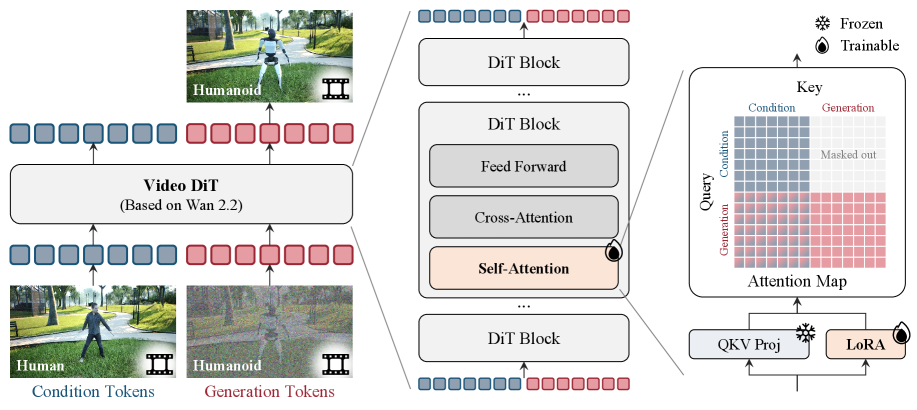
核心思路:论文的核心思路是利用生成式视频编辑技术,将人类视频中的人物转换为类人机器人。通过将预训练的生成模型(Wan 2.2)适配到视频到视频的转换框架中,并使用合成数据进行微调,实现高质量的机器人化效果。
技术框架:X-Humanoid的技术框架主要包含以下几个阶段:1) 数据生成:使用Unreal Engine创建配对的人类-类人机器人视频数据;2) 模型微调:将Wan 2.2模型适配到视频到视频的结构,并使用合成数据进行微调,使其能够将人类视频转换为类人机器人视频;3) 数据生成与应用:将训练好的模型应用于大规模的人类视频数据集(如Ego-Exo4D),生成机器人化后的视频数据。
关键创新:该论文的关键创新在于:1) 提出了一种基于生成式视频编辑的机器人化方法,能够处理复杂的全身运动和场景遮挡;2) 设计了一个可扩展的数据生成流程,能够高效地创建大规模的配对合成数据;3) 构建了一个大规模的机器人化类人机器人视频数据集,为机器人学习和具身智能研究提供了宝贵资源。
关键设计:论文的关键设计包括:1) 使用Wan 2.2作为基础模型,利用其强大的生成能力;2) 设计了合适的损失函数,以保证生成视频的质量和运动一致性;3) 通过微调策略,使模型能够适应人类到类人机器人的转换任务;4) 利用Unreal Engine的强大功能,高效地生成高质量的合成数据。
🖼️ 关键图片


📊 实验亮点
实验结果表明,X-Humanoid在运动一致性和具身正确性方面显著优于现有基线方法。用户研究显示,69%的用户认为X-Humanoid在运动一致性方面表现最佳,62.1%的用户认为其在具身正确性方面表现最佳。该方法成功生成了一个包含超过360万帧的大规模机器人化类人机器人视频数据集。
🎯 应用场景
该研究成果可广泛应用于机器人学习、具身智能、人机交互等领域。通过大规模生成机器人视频数据,可以促进VLA模型和世界模型的训练,提升机器人的感知、决策和控制能力。此外,该技术还可以用于虚拟现实、游戏开发等领域,创造更逼真、更具互动性的虚拟体验。
📄 摘要(原文)
The advancement of embodied AI has unlocked significant potential for intelligent humanoid robots. However, progress in both Vision-Language-Action (VLA) models and world models is severely hampered by the scarcity of large-scale, diverse training data. A promising solution is to "robotize" web-scale human videos, which has been proven effective for policy training. However, these solutions mainly "overlay" robot arms to egocentric videos, which cannot handle complex full-body motions and scene occlusions in third-person videos, making them unsuitable for robotizing humans. To bridge this gap, we introduce X-Humanoid, a generative video editing approach that adapts the powerful Wan 2.2 model into a video-to-video structure and finetunes it for the human-to-humanoid translation task. This finetuning requires paired human-humanoid videos, so we designed a scalable data creation pipeline, turning community assets into 17+ hours of paired synthetic videos using Unreal Engine. We then apply our trained model to 60 hours of the Ego-Exo4D videos, generating and releasing a new large-scale dataset of over 3.6 million "robotized" humanoid video frames. Quantitative analysis and user studies confirm our method's superiority over existing baselines: 69% of users rated it best for motion consistency, and 62.1% for embodiment correctness.