Detection of Intoxicated Individuals from Facial Video Sequences via a Recurrent Fusion Model
作者: Bita Baroutian, Atefe Aghaei, Mohsen Ebrahimi Moghaddam
分类: cs.CV, cs.AI
发布日期: 2025-12-04
💡 一句话要点
提出一种基于循环融合模型的面部视频酒精中毒检测方法
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 酒精中毒检测 面部视频分析 图注意力网络 3D ResNet 时空特征融合
📋 核心要点
- 现有酒精中毒检测方法存在非侵入性不足或准确率较低的挑战,限制了其在公共安全领域的应用。
- 该论文提出一种基于面部视频序列分析的酒精中毒检测方法,融合了GAT和3D ResNet提取的特征,并进行动态融合。
- 实验结果表明,该方法在准确率、精确率和召回率方面均优于现有方法,具有实际部署潜力。
📝 摘要(中文)
本研究提出了一种新颖的基于视频的面部序列分析方法,用于检测酒精中毒。该方法集成了通过图注意力网络(GAT)进行的面部landmark分析,以及使用3D ResNet提取的时空视觉特征。这些特征通过自适应优先级进行动态融合,以提高分类性能。此外,我们还引入了一个包含来自202个人的3542个视频片段的数据集,以支持训练和评估。我们的模型与两个基线进行了比较:一个定制的3D-CNN和一个VGGFace+LSTM架构。实验结果表明,我们的方法实现了95.82%的准确率,0.977的精确率和0.97的召回率,优于现有方法。研究结果表明,该模型具有在公共安全系统中实际部署的潜力,可用于非侵入式、可靠的酒精中毒检测。
🔬 方法详解
问题定义:论文旨在解决通过面部视频序列自动检测酒精中毒的问题。现有方法可能依赖于侵入式检测手段(如血液酒精含量测试),或者基于图像的算法精度不足,难以满足公共安全场景的需求。因此,需要一种非侵入式、高精度的视频分析方法来判断个体是否处于酒精中毒状态。
核心思路:论文的核心思路是结合面部landmark信息和时空视觉特征,利用图注意力网络(GAT)提取面部关键点的关系,并使用3D ResNet捕捉视频中的时空动态信息。通过动态融合这两种特征,模型能够更全面地理解面部行为与酒精中毒之间的关联。
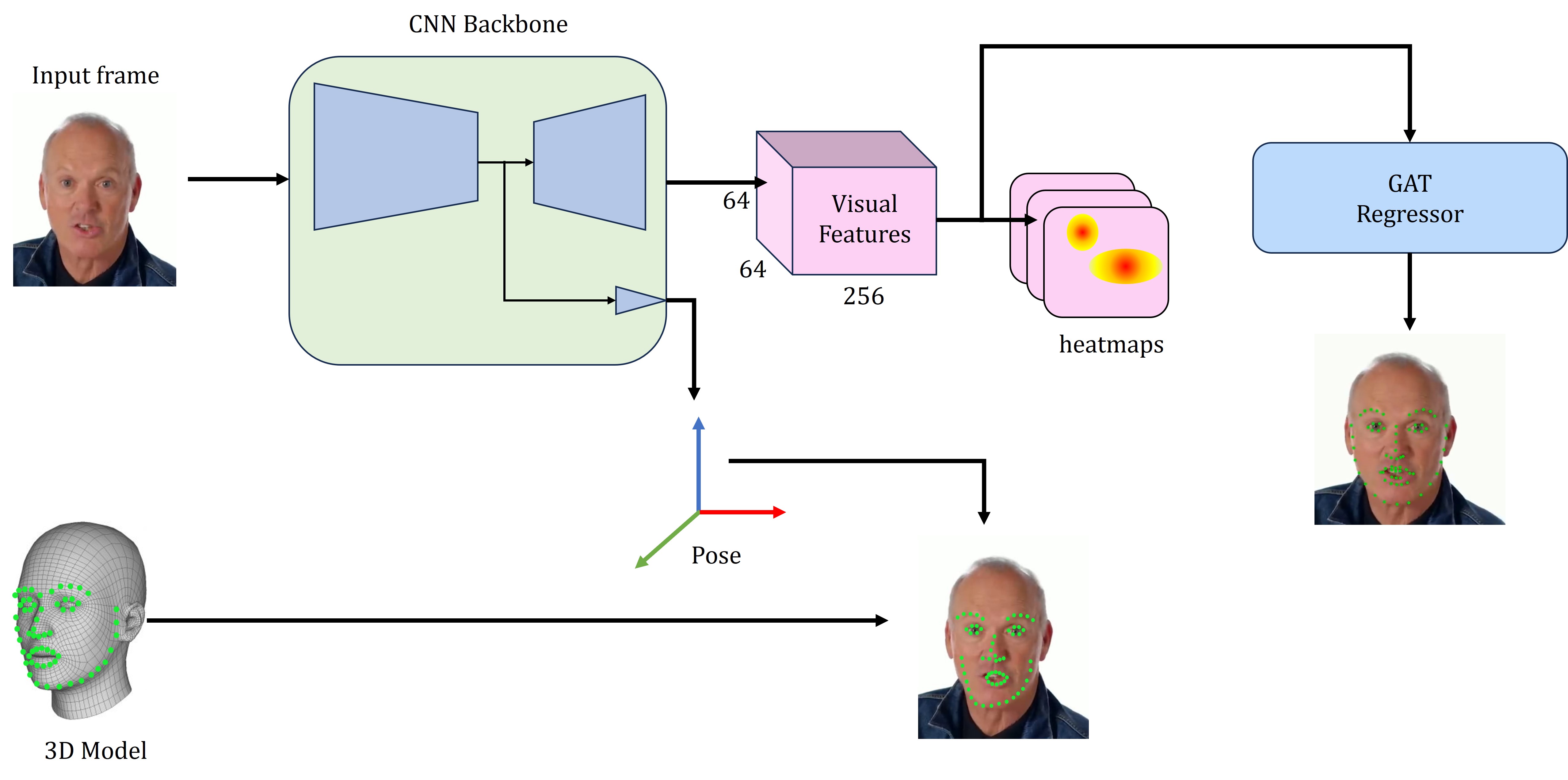
技术框架:该方法主要包含以下几个模块:1) 面部landmark检测:使用算法检测面部关键点的位置。2) 图注意力网络(GAT):利用GAT分析面部landmark之间的关系,提取面部结构特征。3) 3D ResNet:使用3D ResNet提取视频序列的时空视觉特征。4) 特征融合:将GAT提取的特征和3D ResNet提取的特征进行动态融合,赋予不同特征不同的权重。5) 分类器:使用分类器(例如,全连接层或支持向量机)判断个体是否处于酒精中毒状态。
关键创新:该方法的关键创新在于动态融合面部landmark特征和时空视觉特征。通过自适应地调整不同特征的权重,模型能够更好地关注与酒精中毒相关的面部行为。此外,使用GAT提取面部landmark关系也是一个创新点,能够捕捉面部结构的细微变化。
关键设计:在GAT中,注意力机制用于学习不同landmark之间的重要性权重。3D ResNet的网络结构选择需要根据数据集的大小和复杂度进行调整。特征融合模块的设计至关重要,可以使用注意力机制或门控机制来实现动态权重分配。损失函数通常选择交叉熵损失函数,用于训练分类器。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在自建数据集上取得了显著的性能提升。具体而言,该方法实现了95.82%的准确率,0.977的精确率和0.97的召回率,优于定制的3D-CNN和VGGFace+LSTM等基线方法。这些结果表明,该方法能够有效地检测酒精中毒,具有实际应用价值。
🎯 应用场景
该研究成果可应用于公共安全领域,例如在酒吧、夜店等场所部署监控系统,自动检测醉酒人员,预防潜在的事故和暴力事件。此外,还可以应用于交通安全领域,例如在车辆中安装酒精检测系统,防止酒后驾驶。该技术具有非侵入性、实时性等优点,具有广阔的应用前景。
📄 摘要(原文)
Alcohol consumption is a significant public health concern and a major cause of accidents and fatalities worldwide. This study introduces a novel video-based facial sequence analysis approach dedicated to the detection of alcohol intoxication. The method integrates facial landmark analysis via a Graph Attention Network (GAT) with spatiotemporal visual features extracted using a 3D ResNet. These features are dynamically fused with adaptive prioritization to enhance classification performance. Additionally, we introduce a curated dataset comprising 3,542 video segments derived from 202 individuals to support training and evaluation. Our model is compared against two baselines: a custom 3D-CNN and a VGGFace+LSTM architecture. Experimental results show that our approach achieves 95.82% accuracy, 0.977 precision, and 0.97 recall, outperforming prior methods. The findings demonstrate the model's potential for practical deployment in public safety systems for non-invasive, reliable alcohol intoxication detection.