Back to Basics: Motion Representation Matters for Human Motion Generation Using Diffusion Model
作者: Yuduo Jin, Brandon Haworth
分类: cs.CV, cs.GR
发布日期: 2025-12-04
💡 一句话要点
基于扩散模型的人体运动生成:运动表征对性能影响的深度分析
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体运动生成 扩散模型 运动表征 损失函数 训练配置 动作合成 深度学习
📋 核心要点
- 现有运动生成扩散模型在运动表征和训练配置选择上缺乏系统性研究,影响了模型性能。
- 该论文通过控制变量实验,深入研究了不同运动表征和训练配置对运动生成扩散模型的影响。
- 实验结果表明,不同的运动表征在不同数据集上表现出显著的性能差异,并揭示了训练配置对模型训练速度的影响。
📝 摘要(中文)
扩散模型已成为人体运动合成中广泛使用且成功的方法。面向任务的扩散模型显著推进了动作到运动、文本到运动和音频到运动的应用。本文通过受控研究,调查了运动表征和损失函数中的基本问题,并列举了生成运动扩散模型工作流程中各种决策的影响。为了回答这些问题,我们基于代理运动扩散模型(MDM)进行了实证研究。我们将 v loss 应用于 MDM(vMDM)作为预测目标,其中 v 是运动数据和噪声的加权和。我们的目标是增强对潜在数据分布的理解,并为改进条件运动扩散模型的状态提供基础。首先,我们评估了文献中六种常见的运动表征,并比较了它们在质量和多样性指标方面的性能。其次,我们比较了各种配置下的训练时间,以阐明如何加速运动扩散模型的训练过程。最后,我们还对大型运动数据集进行了评估分析。我们的实验结果表明,不同数据集中的运动表征存在明显的性能差异。我们的结果还证明了不同配置对模型训练的影响,并表明这些决策对运动扩散模型结果的重要性和有效性。
🔬 方法详解
问题定义:现有的人体运动生成扩散模型在选择合适的运动表征和训练配置时缺乏充分的理论指导和实验依据。不同的运动表征方式(例如欧拉角、旋转矩阵、四元数等)以及不同的训练配置(例如损失函数、优化器等)可能会对生成运动的质量、多样性和训练效率产生显著影响。因此,需要系统地研究这些因素对模型性能的影响,从而为设计更有效的运动生成扩散模型提供指导。
核心思路:该论文的核心思路是通过构建一个代理运动扩散模型(MDM),并在此基础上进行大量的控制变量实验,以评估不同运动表征和训练配置对模型性能的影响。通过比较不同设置下的生成运动的质量、多样性和训练时间,从而揭示这些因素之间的关系,并为选择合适的运动表征和训练配置提供依据。
技术框架:该论文的技术框架主要包括以下几个部分:1)构建一个基于扩散模型的代理运动生成模型(MDM);2)选择六种常用的运动表征方式进行评估;3)设计不同的训练配置,例如不同的损失函数和优化器;4)在大型运动数据集上进行实验,并评估不同设置下的生成运动的质量、多样性和训练时间;5)分析实验结果,并总结不同运动表征和训练配置对模型性能的影响。
关键创新:该论文的关键创新在于对运动生成扩散模型中的运动表征和训练配置进行了系统性的研究。以往的研究往往侧重于模型结构的改进,而忽略了运动表征和训练配置对模型性能的影响。该论文通过大量的控制变量实验,揭示了这些因素之间的关系,并为选择合适的运动表征和训练配置提供了依据。
关键设计:该论文的关键设计包括:1)选择 v loss 作为 MDM 的预测目标,其中 v 是运动数据和噪声的加权和;2)评估了六种常用的运动表征方式,包括欧拉角、旋转矩阵、四元数等;3)比较了不同训练配置下的训练时间,例如不同的损失函数和优化器;4)在大型运动数据集上进行了实验,并评估了生成运动的质量、多样性和训练时间。
🖼️ 关键图片

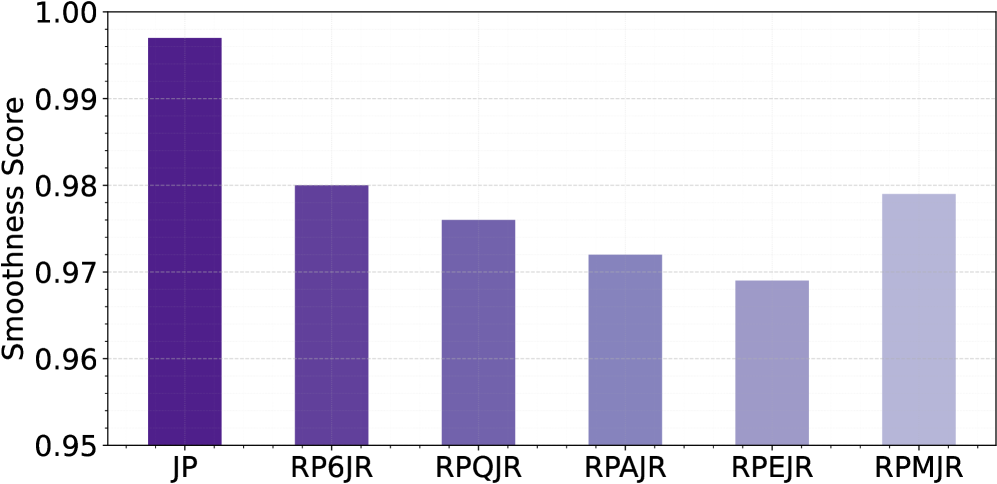
📊 实验亮点
实验结果表明,不同的运动表征在不同的数据集上表现出显著的性能差异。例如,某些运动表征在特定数据集上能够生成更高质量的运动,而另一些运动表征则能够生成更多样化的运动。此外,实验还揭示了不同的训练配置对模型训练速度的影响,为加速运动扩散模型的训练过程提供了指导。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、动画制作等领域,提升虚拟角色的运动真实感和多样性。通过优化运动表征和训练配置,可以降低模型训练成本,加速运动生成过程,从而提高相关应用的用户体验和开发效率。未来的研究可以进一步探索更有效的运动表征方式和训练策略,以实现更高质量、更逼真的人体运动生成。
📄 摘要(原文)
Diffusion models have emerged as a widely utilized and successful methodology in human motion synthesis. Task-oriented diffusion models have significantly advanced action-to-motion, text-to-motion, and audio-to-motion applications. In this paper, we investigate fundamental questions regarding motion representations and loss functions in a controlled study, and we enumerate the impacts of various decisions in the workflow of the generative motion diffusion model. To answer these questions, we conduct empirical studies based on a proxy motion diffusion model (MDM). We apply v loss as the prediction objective on MDM (vMDM), where v is the weighted sum of motion data and noise. We aim to enhance the understanding of latent data distributions and provide a foundation for improving the state of conditional motion diffusion models. First, we evaluate the six common motion representations in the literature and compare their performance in terms of quality and diversity metrics. Second, we compare the training time under various configurations to shed light on how to speed up the training process of motion diffusion models. Finally, we also conduct evaluation analysis on a large motion dataset. The results of our experiments indicate clear performance differences across motion representations in diverse datasets. Our results also demonstrate the impacts of distinct configurations on model training and suggest the importance and effectiveness of these decisions on the outcomes of motion diffusion models.