NAS-LoRA: Empowering Parameter-Efficient Fine-Tuning for Visual Foundation Models with Searchable Adaptation
作者: Renqi Chen, Haoyang Su, Shixiang Tang
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-12-03
💡 一句话要点
NAS-LoRA:通过可搜索的适配增强视觉基础模型的参数高效微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 神经架构搜索 视觉基础模型 低秩适配 归纳偏置 图像分割 领域自适应
📋 核心要点
- 现有参数高效微调方法在视觉基础模型上缺乏有效的归纳偏置,限制了模型在特定领域的性能。
- NAS-LoRA 通过在 LoRA 结构中引入神经架构搜索块,动态优化先验知识的集成,弥合语义差距。
- 实验表明,NAS-LoRA 提升了现有 PEFT 方法的性能,并降低了训练成本,同时保持了推理效率。
📝 摘要(中文)
Segment Anything Model (SAM) 已经成为图像分割领域强大的视觉基础模型。然而,将 SAM 应用于特定的下游任务,例如医学和农业图像,仍然是一个巨大的挑战。为了解决这个问题,低秩适配 (LoRA) 及其变体已被广泛用于提高 SAM 在不同领域的适应性能。尽管取得了进展,但一个关键问题出现了:我们能否将归纳偏置整合到模型中?这一点尤其重要,因为 SAM 中的 Transformer 编码器本质上缺乏图像块内的空间先验,这可能会阻碍高级语义信息的获取。在本文中,我们提出了一种新的参数高效微调 (PEFT) 方法 NAS-LoRA,旨在弥合预训练 SAM 和专门领域之间的语义差距。具体来说,NAS-LoRA 在 LoRA 的编码器和解码器组件之间加入了一个轻量级的神经架构搜索 (NAS) 块,以动态优化集成到权重更新中的先验知识。此外,我们提出了一种阶段式优化策略,以帮助 ViT 编码器平衡权重更新和架构调整,从而促进高级语义信息的逐步学习。各种实验表明,我们的 NAS-LoRA 改进了现有的 PEFT 方法,同时在不增加推理成本的情况下降低了 24.14% 的训练成本,突出了 NAS 在增强视觉基础模型的 PEFT 方面的潜力。
🔬 方法详解
问题定义:论文旨在解决视觉基础模型(如 SAM)在特定下游任务中,由于缺乏针对性归纳偏置而导致的性能瓶颈问题。现有参数高效微调方法(如 LoRA)虽然降低了微调成本,但忽略了模型结构本身对学习特定领域知识的影响,导致模型无法充分利用数据中的空间信息和语义信息。
核心思路:论文的核心思路是通过神经架构搜索(NAS)自动寻找最佳的归纳偏置结构,并将其集成到 LoRA 框架中。通过动态调整模型结构,使模型能够更好地适应特定任务的数据分布,从而提高微调效率和性能。这种方法旨在弥合预训练模型和特定领域之间的语义鸿沟。
技术框架:NAS-LoRA 的整体框架是在 LoRA 的编码器和解码器之间插入一个轻量级的 NAS 块。该 NAS 块负责搜索最佳的归纳偏置结构,并将其集成到权重更新中。此外,论文还提出了一种阶段式优化策略,用于平衡 ViT 编码器的权重更新和架构调整,从而实现高级语义信息的逐步学习。整个流程包括:1) 初始化 LoRA 和 NAS 块;2) 使用 NAS 搜索最佳架构;3) 使用阶段式优化策略微调模型。
关键创新:NAS-LoRA 的最重要创新点在于将神经架构搜索与参数高效微调相结合,实现了归纳偏置的自动优化。与传统的 PEFT 方法相比,NAS-LoRA 能够根据特定任务的数据特点,动态调整模型结构,从而更好地适应任务需求。这种方法避免了手动设计归纳偏置结构的繁琐过程,并能够找到更优的结构。
关键设计:NAS-LoRA 的关键设计包括:1) 轻量级 NAS 块的设计,该模块需要足够灵活以搜索不同的架构,同时保持计算效率;2) 阶段式优化策略,该策略需要平衡权重更新和架构调整,避免模型过早陷入局部最优;3) 搜索空间的定义,该空间需要包含各种可能的归纳偏置结构,例如卷积、注意力等。
🖼️ 关键图片

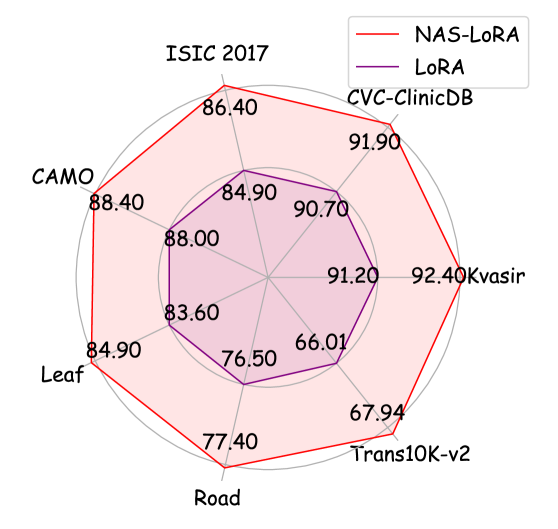

📊 实验亮点
实验结果表明,NAS-LoRA 在多个数据集上优于现有的 PEFT 方法。例如,在特定任务上,NAS-LoRA 能够在不增加推理成本的情况下,将训练成本降低 24.14%。这些结果表明,NAS-LoRA 能够有效地提高视觉基础模型的微调效率和性能,并具有很强的实际应用价值。
🎯 应用场景
NAS-LoRA 具有广泛的应用前景,尤其是在需要将视觉基础模型快速适应到特定领域的场景中。例如,在医学图像分析中,可以将 NAS-LoRA 应用于疾病诊断和病灶分割;在农业图像分析中,可以用于作物生长监测和病虫害识别。此外,该方法还可以应用于遥感图像分析、自动驾驶等领域,提高模型在各种实际应用中的性能和效率。
📄 摘要(原文)
The Segment Anything Model (SAM) has emerged as a powerful visual foundation model for image segmentation. However, adapting SAM to specific downstream tasks, such as medical and agricultural imaging, remains a significant challenge. To address this, Low-Rank Adaptation (LoRA) and its variants have been widely employed to enhancing SAM's adaptation performance on diverse domains. Despite advancements, a critical question arises: can we integrate inductive bias into the model? This is particularly relevant since the Transformer encoder in SAM inherently lacks spatial priors within image patches, potentially hindering the acquisition of high-level semantic information. In this paper, we propose NAS-LoRA, a new Parameter-Efficient Fine-Tuning (PEFT) method designed to bridge the semantic gap between pre-trained SAM and specialized domains. Specifically, NAS-LoRA incorporates a lightweight Neural Architecture Search (NAS) block between the encoder and decoder components of LoRA to dynamically optimize the prior knowledge integrated into weight updates. Furthermore, we propose a stage-wise optimization strategy to help the ViT encoder balance weight updates and architectural adjustments, facilitating the gradual learning of high-level semantic information. Various Experiments demonstrate our NAS-LoRA improves existing PEFT methods, while reducing training cost by 24.14% without increasing inference cost, highlighting the potential of NAS in enhancing PEFT for visual foundation models.