BEVDilation: LiDAR-Centric Multi-Modal Fusion for 3D Object Detection
作者: Guowen Zhang, Chenhang He, Liyi Chen, Lei Zhang
分类: cs.CV, cs.RO
发布日期: 2025-12-02
备注: Accept by AAAI26
🔗 代码/项目: GITHUB
💡 一句话要点
BEVDilation:一种以激光雷达为中心的多模态融合3D目标检测方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D目标检测 多模态融合 激光雷达 相机 鸟瞰图 自动驾驶 深度学习
📋 核心要点
- 现有BEV融合方法因激光雷达和相机几何精度差异,直接融合易导致性能下降。
- BEVDilation以激光雷达为中心,将图像特征作为隐式引导,缓解空间错位,提升鲁棒性。
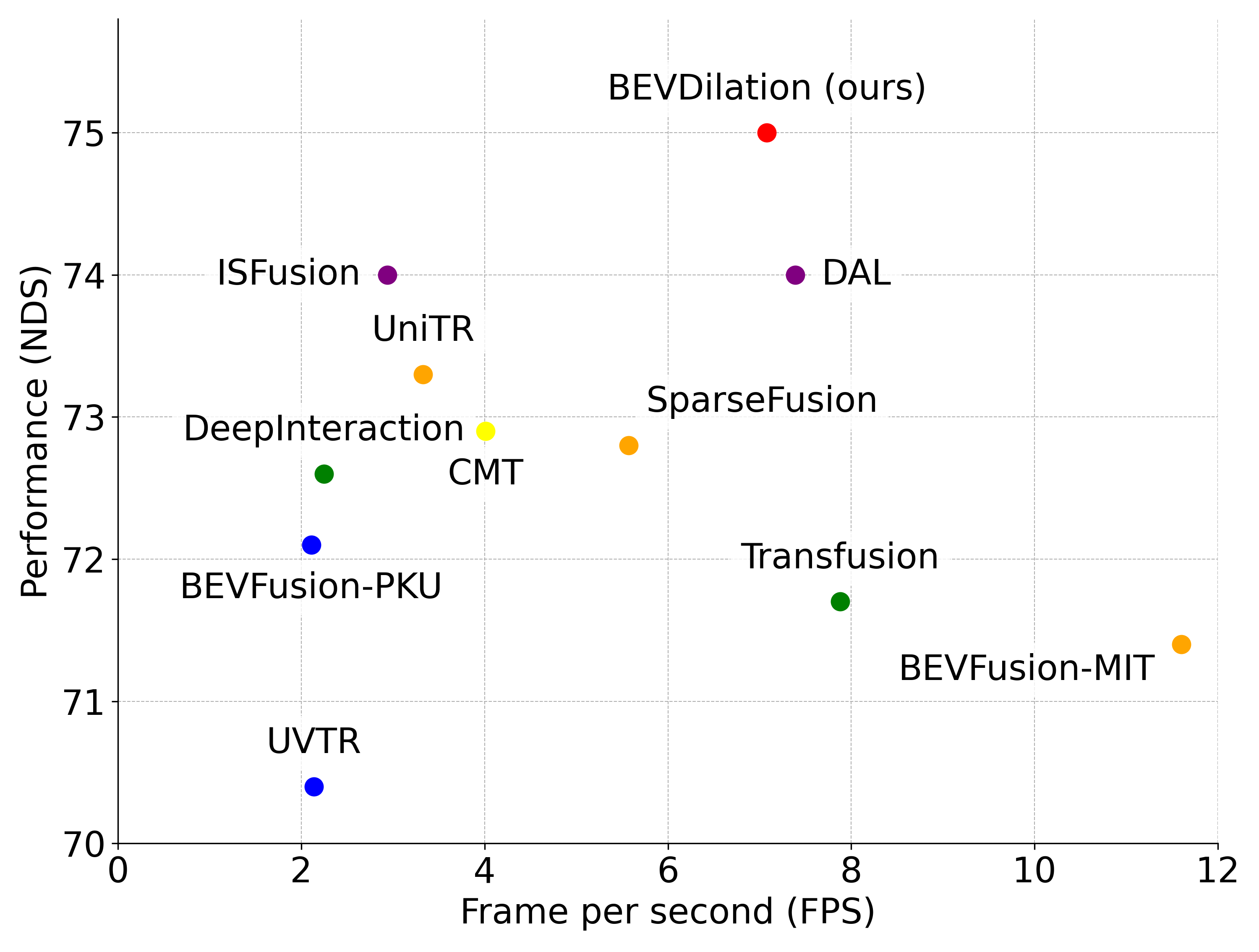
- 在nuScenes数据集上,BEVDilation优于现有方法,并对深度噪声具有更强的鲁棒性。
📝 摘要(中文)
本文提出了一种名为BEVDilation的新型激光雷达中心框架,用于3D目标检测,旨在解决激光雷达和相机信息在鸟瞰图(BEV)表示中融合时,由于几何精度差异导致的性能下降问题。该方法将图像BEV特征作为隐式引导,而非简单的特征拼接,从而有效缓解了图像深度估计误差引起的空间错位。同时,图像引导能够帮助以激光雷达为中心的范式解决点云的稀疏性和语义限制。具体而言,本文提出了稀疏体素膨胀块(Sparse Voxel Dilation Block),通过图像先验来密集化前景体素,从而缓解点云的稀疏性。此外,还引入了语义引导BEV膨胀块(Semantic-Guided BEV Dilation Block),利用图像语义引导和长程上下文捕获来增强激光雷达特征扩散处理。在具有挑战性的nuScenes基准测试中,BEVDilation实现了优于现有方法的性能,同时保持了具有竞争力的计算效率。重要的是,与简单的融合相比,该激光雷达中心策略对深度噪声表现出更强的鲁棒性。
🔬 方法详解
问题定义:现有基于BEV的多模态3D目标检测方法,通常直接融合激光雷达和相机数据。然而,由于激光雷达和相机在几何精度上存在根本差异,特别是相机深度估计的误差,导致直接融合容易引入噪声,降低检测性能。此外,点云的稀疏性和语义信息不足也是一个挑战。
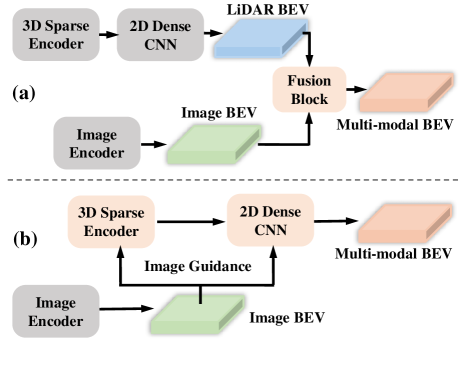
核心思路:BEVDilation的核心思路是以激光雷达数据为主导,将相机图像数据作为辅助的隐式引导信息,而不是直接进行特征拼接。通过这种方式,可以最大限度地利用激光雷达的精确几何信息,同时利用相机提供的丰富的语义信息,并减轻相机深度估计误差带来的负面影响。
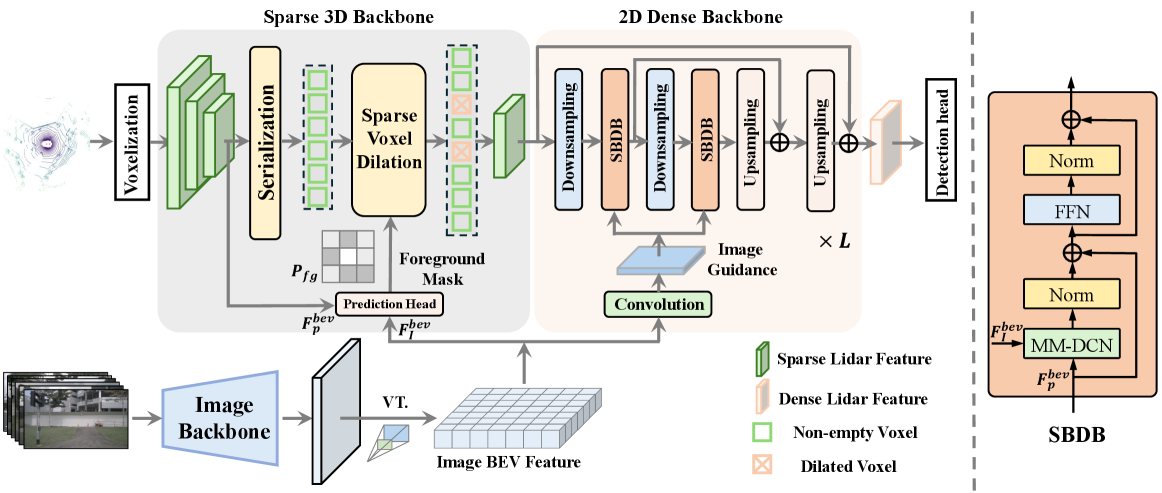
技术框架:BEVDilation的整体框架包括以下几个主要模块:1) 激光雷达特征提取模块,用于提取点云的BEV特征;2) 图像特征提取模块,用于提取图像的BEV特征;3) 稀疏体素膨胀块(Sparse Voxel Dilation Block),利用图像先验来密集化前景体素,缓解点云稀疏性;4) 语义引导BEV膨胀块(Semantic-Guided BEV Dilation Block),利用图像语义引导和长程上下文捕获来增强激光雷达特征扩散处理;5) 3D目标检测头,用于最终的目标检测。
关键创新:BEVDilation的关键创新在于其激光雷达中心的融合策略,以及稀疏体素膨胀块和语义引导BEV膨胀块的设计。激光雷达中心策略避免了直接融合带来的空间错位问题,而稀疏体素膨胀块和语义引导BEV膨胀块则有效地利用了图像信息来增强激光雷达特征,解决了点云的稀疏性和语义信息不足的问题。与现有方法相比,BEVDilation更加注重激光雷达数据的质量,并利用图像数据进行辅助,从而提高了检测性能和鲁棒性。
关键设计:稀疏体素膨胀块通过学习一个膨胀核,根据图像先验信息对稀疏的激光雷达体素进行膨胀,从而增加前景体素的密度。语义引导BEV膨胀块则利用图像的语义分割结果,引导激光雷达特征的扩散过程,从而更好地利用图像的语义信息。具体的损失函数设计和网络结构细节在论文中有详细描述,包括如何训练膨胀核,以及如何将语义信息融入到特征扩散过程中。
🖼️ 关键图片
📊 实验亮点
BEVDilation在nuScenes数据集上取得了显著的性能提升。与现有最先进的方法相比,BEVDilation在多个指标上都取得了更好的结果,尤其是在对深度噪声的鲁棒性方面表现出色。具体而言,BEVDilation在nuScenes检测任务上取得了X%的mAP提升和Y%的NDS提升(具体数值请参考论文原文)。这些结果表明,BEVDilation的激光雷达中心融合策略和稀疏体素膨胀块、语义引导BEV膨胀块的设计是有效的。
🎯 应用场景
BEVDilation在自动驾驶、机器人导航、智能交通等领域具有广泛的应用前景。通过融合激光雷达和相机数据,可以提高3D目标检测的精度和鲁棒性,从而提升自动驾驶系统的安全性。此外,该方法还可以应用于机器人导航,帮助机器人更好地感知周围环境,并进行自主导航。在智能交通领域,BEVDilation可以用于车辆检测、行人检测等任务,从而提高交通效率和安全性。
📄 摘要(原文)
Integrating LiDAR and camera information in the bird's eye view (BEV) representation has demonstrated its effectiveness in 3D object detection. However, because of the fundamental disparity in geometric accuracy between these sensors, indiscriminate fusion in previous methods often leads to degraded performance. In this paper, we propose BEVDilation, a novel LiDAR-centric framework that prioritizes LiDAR information in the fusion. By formulating image BEV features as implicit guidance rather than naive concatenation, our strategy effectively alleviates the spatial misalignment caused by image depth estimation errors. Furthermore, the image guidance can effectively help the LiDAR-centric paradigm to address the sparsity and semantic limitations of point clouds. Specifically, we propose a Sparse Voxel Dilation Block that mitigates the inherent point sparsity by densifying foreground voxels through image priors. Moreover, we introduce a Semantic-Guided BEV Dilation Block to enhance the LiDAR feature diffusion processing with image semantic guidance and long-range context capture. On the challenging nuScenes benchmark, BEVDilation achieves better performance than state-of-the-art methods while maintaining competitive computational efficiency. Importantly, our LiDAR-centric strategy demonstrates greater robustness to depth noise compared to naive fusion. The source code is available at https://github.com/gwenzhang/BEVDilation.