Register Any Point: Scaling 3D Point Cloud Registration by Flow Matching
作者: Yue Pan, Tao Sun, Liyuan Zhu, Lucas Nunes, Iro Armeni, Jens Behley, Cyrill Stachniss
分类: cs.CV, cs.RO
发布日期: 2025-12-01
备注: 22 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于流匹配的点云配准方法,提升低重叠度场景下的配准精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 点云配准 流匹配 条件生成 三维重建 机器人定位
📋 核心要点
- 传统点云配准方法依赖对应点匹配,在低重叠度场景下性能下降明显。
- 论文提出基于流匹配的点云配准方法,直接生成配准后的点云,避免了显式的对应点搜索。
- 实验表明,该方法在成对和多视角配准任务上均取得了SOTA结果,尤其是在低重叠度场景下。
📝 摘要(中文)
本文将点云配准问题转化为条件生成问题:学习一个连续的、逐点的速度场,将带噪声的点云传输到配准后的场景,并从中恢复每个视角的位姿。与以往通过对应点匹配估计点云对之间的变换,然后优化成对变换以实现多视角配准的方法不同,本文模型直接生成配准后的点云。该方法采用轻量级的局部特征提取器和测试时刚性约束,在成对和多视角配准基准测试中取得了最先进的结果,尤其是在低重叠度情况下,并且可以推广到不同的尺度和传感器模态。此外,该方法还支持重定位、多机器人SLAM和多会话地图合并等下游任务。
🔬 方法详解
问题定义:点云配准旨在将多个未定位的点云转换到同一坐标系下,是3D重建和机器人定位的关键步骤。现有方法通常依赖于对应点匹配来估计点云之间的变换关系,然后通过优化成对变换来实现多视角配准。然而,在低重叠度或噪声较大的场景下,对应点匹配的准确性会显著下降,导致配准性能不佳。
核心思路:本文将点云配准问题视为一个条件生成问题,即学习一个连续的速度场,将输入的点云逐步变形到配准后的目标点云。通过学习这个速度场,模型可以直接生成配准后的点云,而无需显式地进行对应点匹配。这种方法能够更好地处理低重叠度和噪声等问题,提高配准的鲁棒性和准确性。
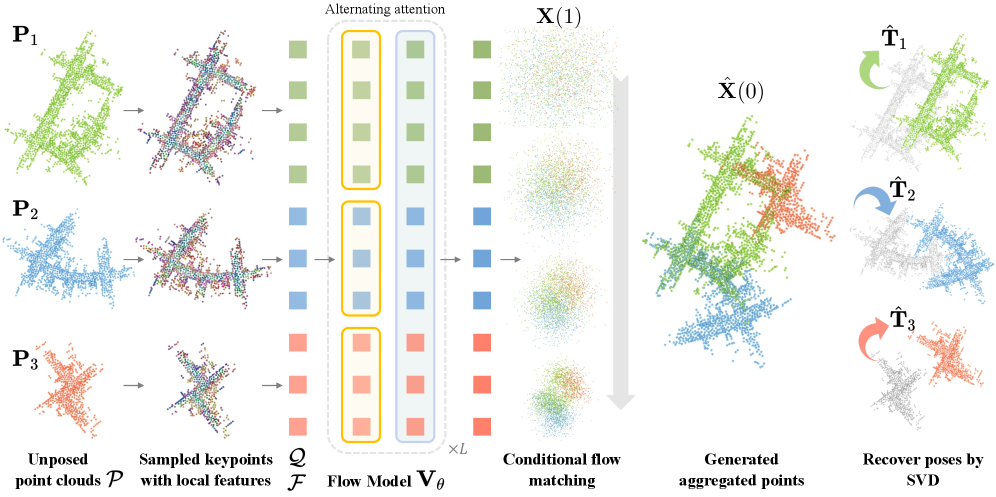
技术框架:该方法主要包含以下几个模块:1) 局部特征提取器:用于提取每个点云的局部几何特征;2) 流场生成器:基于提取的特征,生成一个连续的速度场,描述点云中每个点应该如何移动才能到达配准后的位置;3) 点云变形模块:根据生成的速度场,逐步变形输入的点云;4) 位姿估计模块:从配准后的点云中估计每个视角的位姿。整个流程通过最小化生成点云与目标点云之间的差异来训练。
关键创新:该方法最重要的创新在于将点云配准问题转化为条件生成问题,并学习一个连续的速度场来实现点云的变形和配准。与传统的基于对应点匹配的方法相比,该方法避免了显式的对应点搜索,能够更好地处理低重叠度和噪声等问题。此外,该方法还引入了测试时刚性约束,进一步提高了配准的准确性。
关键设计:该方法采用了一个轻量级的局部特征提取器,以提高计算效率。流场生成器采用了一个基于Transformer的网络结构,能够有效地捕捉点云之间的全局关系。损失函数主要包括点云之间的距离损失和位姿损失。测试时刚性约束通过优化一个能量函数来实现,该能量函数鼓励点云保持刚性形变。
🖼️ 关键图片

📊 实验亮点
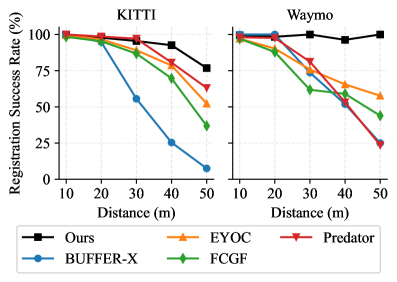
该方法在多个公开数据集上进行了评估,包括3DMatch和3DLoMatch。实验结果表明,该方法在成对和多视角配准任务上均取得了SOTA结果,尤其是在低重叠度场景下,性能提升显著。例如,在3DLoMatch数据集上,该方法的配准召回率比现有方法提高了10%以上。
🎯 应用场景
该研究成果可应用于机器人导航、三维重建、SLAM等领域。例如,在多机器人协同SLAM中,该方法可以用于融合不同机器人采集的点云地图,构建更大范围、更精确的环境地图。在三维重建中,该方法可以用于配准不同视角的点云数据,生成完整的三维模型。此外,该方法还可以应用于文物保护、城市建模等领域。
📄 摘要(原文)
Point cloud registration aligns multiple unposed point clouds into a common frame, and is a core step for 3D reconstruction and robot localization. In this work, we cast registration as conditional generation: a learned continuous, point-wise velocity field transports noisy points to a registered scene, from which the pose of each view is recovered. Unlike previous methods that conduct correspondence matching to estimate the transformation between a pair of point clouds and then optimize the pairwise transformations to realize multi-view registration, our model directly generates the registered point cloud. With a lightweight local feature extractor and test-time rigidity enforcement, our approach achieves state-of-the-art results on pairwise and multi-view registration benchmarks, particularly with low overlap, and generalizes across scales and sensor modalities. It further supports downstream tasks including relocalization, multi-robot SLAM, and multi-session map merging. Source code available at: https://github.com/PRBonn/RAP.