StreamGaze: Gaze-Guided Temporal Reasoning and Proactive Understanding in Streaming Videos
作者: Daeun Lee, Subhojyoti Mukherjee, Branislav Kveton, Ryan A. Rossi, Viet Dac Lai, Seunghyun Yoon, Trung Bui, Franck Dernoncourt, Mohit Bansal
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-12-01
备注: Project page: https://streamgaze.github.io/
💡 一句话要点
StreamGaze:提出基于注视引导的流视频时序推理与主动理解评测基准。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 流视频理解 注视引导 时序推理 主动理解 多模态大语言模型 评测基准 人机交互
📋 核心要点
- 现有流视频理解方法缺乏对人类注视信号的有效利用,无法准确捕捉用户意图。
- StreamGaze通过构建注视引导的问答对,评估模型在流视频中利用注视进行时序推理和主动理解的能力。
- 实验表明,现有MLLM在StreamGaze任务上与人类性能差距显著,表明模型在注视引导推理方面存在局限。
📝 摘要(中文)
流视频理解不仅需要模型处理时序帧,还需要预测用户意图,以应用于AR眼镜等场景。现有流视频基准侧重时序推理,但忽略了多模态大语言模型(MLLM)在流式环境中解释和利用人类注视信号的能力。为此,我们提出了StreamGaze,首个评估MLLM在流视频中利用注视进行时序和主动推理的基准。StreamGaze引入了注视引导的过去、现在和主动任务,全面评估流视频理解。这些任务评估模型是否能利用实时注视跟踪注意力转移,并仅从过去和当前观察到的帧推断用户意图。我们开发了一个注视-视频问答生成流程,通过注视点提取、区域特定视觉提示和扫视路径构建,将第一人称视角视频与原始注视轨迹对齐。该流程生成时空对齐的问答对,紧密反映人类感知动态。实验表明,当前MLLM在所有StreamGaze任务上与人类性能存在显著差距,揭示了基于注视的时序推理、意图建模和主动预测的根本局限性。我们进一步分析了注视提示策略、推理行为和特定任务的失败模式,深入了解了当前MLLM的不足以及未来模型需要发展的能力。所有数据和代码将公开发布,以支持基于注视引导的流视频理解的持续研究。
🔬 方法详解
问题定义:现有流视频理解基准主要关注时序推理,忽略了人类注视信息在理解用户意图中的作用。缺乏一个能够有效评估模型利用注视信号进行时序推理和主动预测的基准。现有方法难以将注视信息与视频内容进行有效对齐,从而无法进行准确的意图推断。
核心思路:StreamGaze的核心思路是构建一个包含注视信息的流视频问答数据集,并设计相应的评测任务,以评估模型利用注视信号进行时序推理和主动理解的能力。通过将注视轨迹与视频内容对齐,模型可以更好地理解用户的关注点,从而更准确地预测用户意图。
技术框架:StreamGaze的整体框架包括以下几个主要模块:1) 注视-视频问答生成流程:该流程负责生成包含注视信息的问答对,包括注视点提取、区域特定视觉提示和扫视路径构建等步骤。2) 评测任务设计:设计了注视引导的过去、现在和主动任务,全面评估流视频理解能力。3) 模型评估:使用现有的MLLM模型在StreamGaze上进行评估,并与人类性能进行对比。
关键创新:StreamGaze的关键创新在于:1) 首次提出了基于注视引导的流视频理解评测基准。2) 开发了一种新的注视-视频问答生成流程,能够有效地将注视轨迹与视频内容对齐。3) 设计了多种评测任务,全面评估模型在流视频中利用注视进行时序推理和主动理解的能力。
关键设计:在注视-视频问答生成流程中,采用了区域特定视觉提示技术,根据注视点的位置,对视频帧的特定区域进行提示,以帮助模型更好地理解用户的关注点。在评测任务设计中,考虑了过去、现在和未来三个时间维度,全面评估模型在不同时间阶段的理解能力。具体参数设置和网络结构的选择取决于所使用的MLLM模型。
🖼️ 关键图片
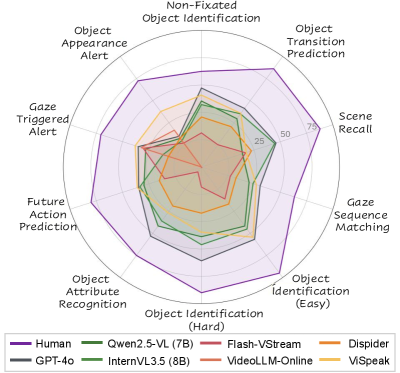
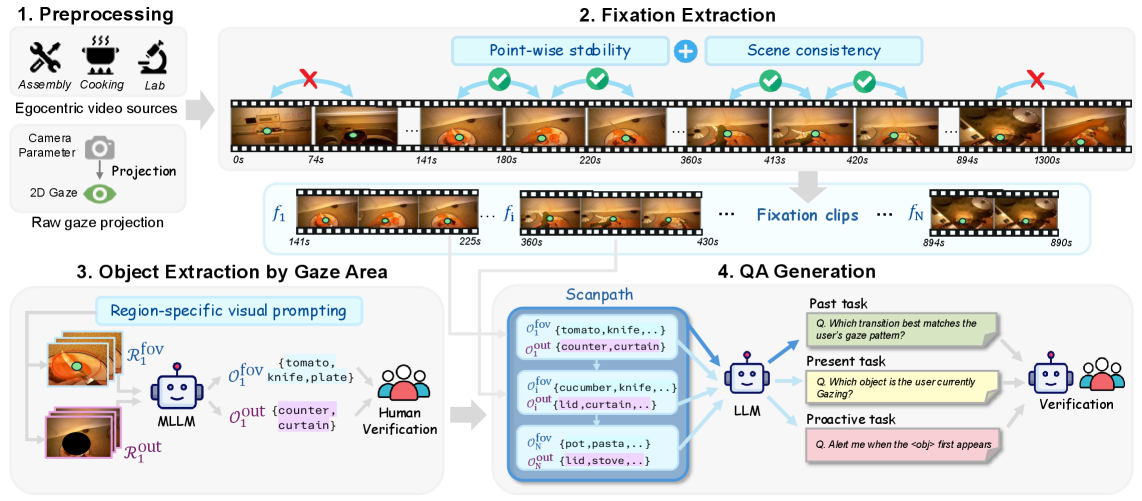
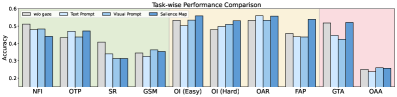
📊 实验亮点
实验结果表明,现有的MLLM模型在StreamGaze任务上的表现与人类水平存在显著差距。例如,在主动预测任务中,MLLM的准确率远低于人类水平,表明模型在利用注视信息进行意图预测方面存在局限性。通过对不同注视提示策略的分析,发现某些提示策略能够显著提高模型的性能,但仍然无法达到人类水平。
🎯 应用场景
StreamGaze的研究成果可应用于AR眼镜、智能辅助驾驶、人机交互等领域。通过理解用户的注视行为,系统可以更准确地预测用户意图,从而提供更智能、更个性化的服务。例如,在AR眼镜中,系统可以根据用户的注视点,自动显示相关信息或提供操作建议。在智能辅助驾驶中,系统可以根据驾驶员的注视方向,判断驾驶员的注意力是否集中,从而提高驾驶安全性。
📄 摘要(原文)
Streaming video understanding requires models not only to process temporally incoming frames, but also to anticipate user intention for realistic applications like AR glasses. While prior streaming benchmarks evaluate temporal reasoning, none measure whether MLLMs can interpret or leverage human gaze signals within a streaming setting. To fill this gap, we introduce StreamGaze, the first benchmark designed to evaluate how effectively MLLMs use gaze for temporal and proactive reasoning in streaming videos. StreamGaze introduces gaze-guided past, present, and proactive tasks that comprehensively evaluate streaming video understanding. These tasks assess whether models can use real-time gaze to follow shifting attention and infer user intentions from only past and currently observed frames. To build StreamGaze, we develop a gaze-video QA generation pipeline that aligns egocentric videos with raw gaze trajectories via fixation extraction, region-specific visual prompting, and scanpath construction. This pipeline produces spatio-temporally grounded QA pairs that closely reflect human perceptual dynamics. Across all StreamGaze tasks, we observe substantial performance gaps between state-of-the-art MLLMs and human performance, revealing fundamental limitations in gaze-based temporal reasoning, intention modeling, and proactive prediction. We further provide detailed analyses of gaze-prompting strategies, reasoning behaviors, and task-specific failure modes, offering deeper insight into why current MLLMs struggle and what capabilities future models must develop. All data and code will be publicly released to support continued research in gaze-guided streaming video understanding.