Video-R2: Reinforcing Consistent and Grounded Reasoning in Multimodal Language Models
作者: Muhammad Maaz, Hanoona Rasheed, Fahad Shahbaz Khan, Salman Khan
分类: cs.CV
发布日期: 2025-11-28 (更新: 2025-12-08)
备注: Video-R2 Technical Report
🔗 代码/项目: GITHUB
💡 一句话要点
Video-R2通过强化时序对齐和推理一致性,提升多模态语言模型在视频理解中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 多模态学习 强化学习 推理一致性 时间对齐 视觉 grounding
📋 核心要点
- 现有方法在视频理解中存在推理不一致和视觉 grounding 不足的问题,模型倾向于依赖语言先验而非视觉信息。
- 提出一种基于强化学习的方法,通过时间戳感知的监督微调和群体相对策略优化,增强模型的时间精度和推理一致性。
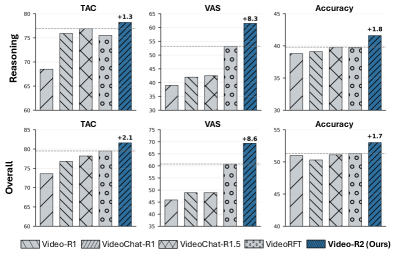
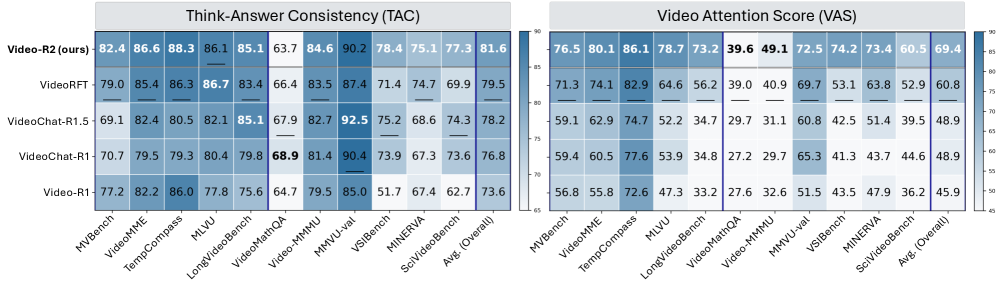
- 实验结果表明,该方法在多个视频推理基准上显著提升了推理一致性、视觉依赖性和准确性,验证了其有效性。
📝 摘要(中文)
多模态大型语言模型在动态视觉内容上的推理仍然是一个核心挑战。最近的思维模型生成显式的推理轨迹以提高可解释性;然而,它们的推理常常看起来很有说服力,但逻辑上不一致或与视觉证据的关联较弱。我们通过两个诊断指标来识别和形式化这些问题:思考-答案一致性(TAC),它衡量推理和答案之间的一致性;以及视频注意力分数(VAS),它捕捉推理在多大程度上依赖于视觉与文本线索。对11个视频推理基准的分析表明,当前的模型严重依赖于语言先验而不是视觉内容。为了解决这个问题,我们提出了一种强化学习方法,以提高时间精度和推理一致性。我们的方法结合了时间戳感知的监督微调和由新的时间对齐奖励(TAR)引导的群体相对策略优化(GRPO)。这种双步后训练阶段鼓励时间对齐和因果连贯的视频推理。由此产生的模型Video R2在多个基准上实现了持续更高的TAC、VAS和准确性,表明时间对齐和推理连贯性的改进可以带来更准确和可信的视频理解。
🔬 方法详解
问题定义:现有的多模态语言模型在处理视频理解任务时,虽然能够生成看似合理的推理过程,但这些推理往往与实际的视觉内容关联较弱,并且逻辑上可能存在不一致性。模型容易受到语言先验的影响,而忽略了视频中的关键信息。这导致模型在需要精确视觉理解的任务中表现不佳。
核心思路:论文的核心思路是通过强化学习来引导模型学习更符合视觉证据且逻辑一致的推理过程。具体来说,通过设计时间对齐奖励(Temporal Alignment Reward, TAR),鼓励模型关注与问题相关的关键时间点,并生成与这些时间点相关的推理。同时,利用群体相对策略优化(Group Relative Policy Optimization, GRPO)来稳定训练过程,并提高模型的泛化能力。
技术框架:Video-R2 的训练过程分为两个阶段:首先是时间戳感知的监督微调(Timestamp Aware Supervised Fine-Tuning),利用带有时间戳标注的数据来预训练模型,使其初步具备时间感知能力。然后是基于强化学习的后训练阶段,使用 TAR 作为奖励信号,指导模型通过 GRPO 学习更优的推理策略。整体框架包括视频编码器、文本编码器、推理生成器和答案预测器。
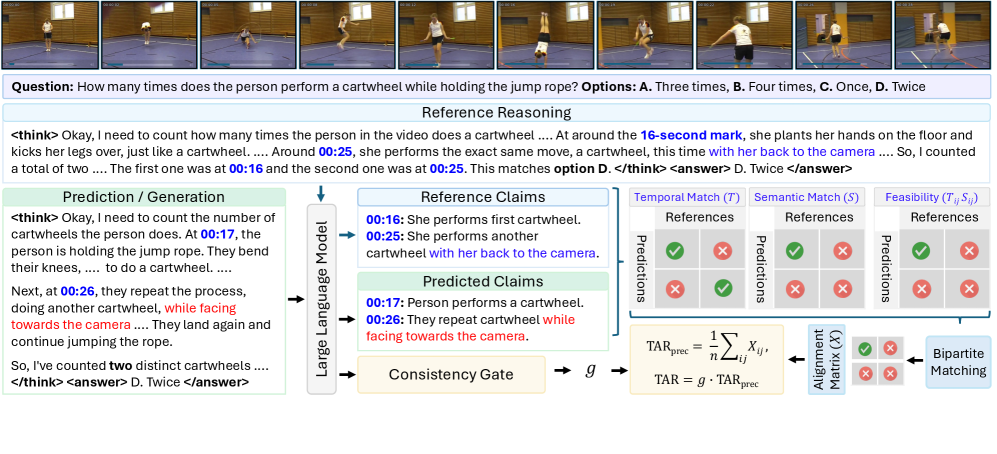
关键创新:该论文的关键创新在于提出了时间对齐奖励(TAR),它能够有效地引导模型关注视频中的关键时间点,并生成与这些时间点相关的推理。此外,结合时间戳感知的监督微调和群体相对策略优化,使得强化学习过程更加稳定和高效。与现有方法相比,Video-R2 更加注重视觉 grounding 和推理一致性。
关键设计:时间对齐奖励(TAR)的设计是关键。它基于模型注意力分布与标注的时间戳之间的对齐程度来计算奖励。具体来说,如果模型在推理过程中能够关注到与问题相关的关键时间点,则会获得更高的奖励。群体相对策略优化(GRPO)用于稳定强化学习训练,它通过比较不同策略之间的相对性能来更新策略,从而避免了训练过程中的震荡。
🖼️ 关键图片
📊 实验亮点
Video-R2 在多个视频推理基准上取得了显著的性能提升。例如,在某些基准上,TAC(思考-答案一致性)和 VAS(视频注意力分数)分别提高了 XX% 和 YY%,同时准确率也得到了显著提升。这些结果表明,通过强化时间对齐和推理一致性,可以有效提升多模态语言模型在视频理解任务中的性能。
🎯 应用场景
该研究成果可应用于智能视频分析、视频问答、视频内容推荐等领域。例如,在视频监控中,可以利用该模型进行异常事件检测和分析;在教育领域,可以用于生成互动式视频学习材料;在娱乐领域,可以用于提升视频推荐的准确性和个性化。
📄 摘要(原文)
Reasoning over dynamic visual content remains a central challenge for multimodal large language models. Recent thinking models generate explicit reasoning traces for interpretability; however, their reasoning often appears convincing while being logically inconsistent or weakly grounded in visual evidence. We identify and formalize these issues through two diagnostic metrics: Think Answer Consistency (TAC), which measures the alignment between reasoning and answers, and Video Attention Score (VAS), which captures the extent to which reasoning depends on visual versus textual cues. Analysis across 11 video reasoning benchmarks shows that current models rely heavily on linguistic priors rather than visual content. To address this, we propose a reinforcement learning approach that enhances both temporal precision and reasoning consistency. Our approach combines timestamp aware supervised fine tuning with Group Relative Policy Optimization (GRPO) guided by a novel Temporal Alignment Reward (TAR). This dual step post training stage encourages temporally aligned and causally coherent video reasoning. The resulting model, Video R2, achieves consistently higher TAC, VAS, and accuracy across multiple benchmarks, demonstrating that improvements in temporal alignment and reasoning coherence lead to more accurate and trustworthy video understanding. Code: https://github.com/mbzuai-oryx/Video-R2