DEAL-300K: Diffusion-based Editing Area Localization with a 300K-Scale Dataset and Frequency-Prompted Baseline
作者: Rui Zhang, Hongxia Wang, Hangqing Liu, Yang Zhou, Qiang Zeng
分类: cs.CV
发布日期: 2025-11-28
备注: 13pages,12 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出DEAL-300K数据集与频率提示基线,用于扩散模型图像编辑区域定位
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 图像编辑 区域定位 视觉基础模型 频率提示调整 数据集 主动学习
📋 核心要点
- 现有图像编辑定位方法难以有效检测扩散模型生成的平滑融合编辑区域,缺乏针对性数据集。
- 提出DEAL-300K数据集,并设计多频提示调整(MFPT)框架,利用视觉基础模型提取语义和频率信息。
- 实验表明,该方法在DEAL-300K测试集和CoCoGlide基准上均取得了优异的像素级F1分数,验证了有效性。
📝 摘要(中文)
扩散模型图像编辑使得普通用户可以轻松进行语义级别的图像操作,但也导致了难以定位的逼真局部伪造。现有的基准测试主要关注生成图像的二元检测或手动编辑区域的定位,未能反映扩散模型编辑的特性,即编辑区域通常与原始内容平滑融合。我们提出了扩散模型图像编辑区域定位数据集(DEAL-300K),这是一个大规模数据集,包含超过30万张带标注的图像,用于扩散模型图像操作定位(DIML)。我们使用多模态大型语言模型生成编辑指令,使用无掩码扩散编辑器生成操作图像,并使用主动学习变化检测流程获取像素级标注来构建DEAL-300K。在此数据集的基础上,我们提出了一种定位框架,该框架使用冻结的视觉基础模型(VFM)以及多频提示调整(MFPT)来捕获编辑区域的语义和频域线索。在DEAL-300K上训练后,我们的方法在测试集上达到了82.56%的像素级F1分数,在外部CoCoGlide基准测试上达到了80.97%,为未来的DIML研究提供了强大的基线和实践基础。数据集可通过https://github.com/ymhzyj/DEAL-300K访问。
🔬 方法详解
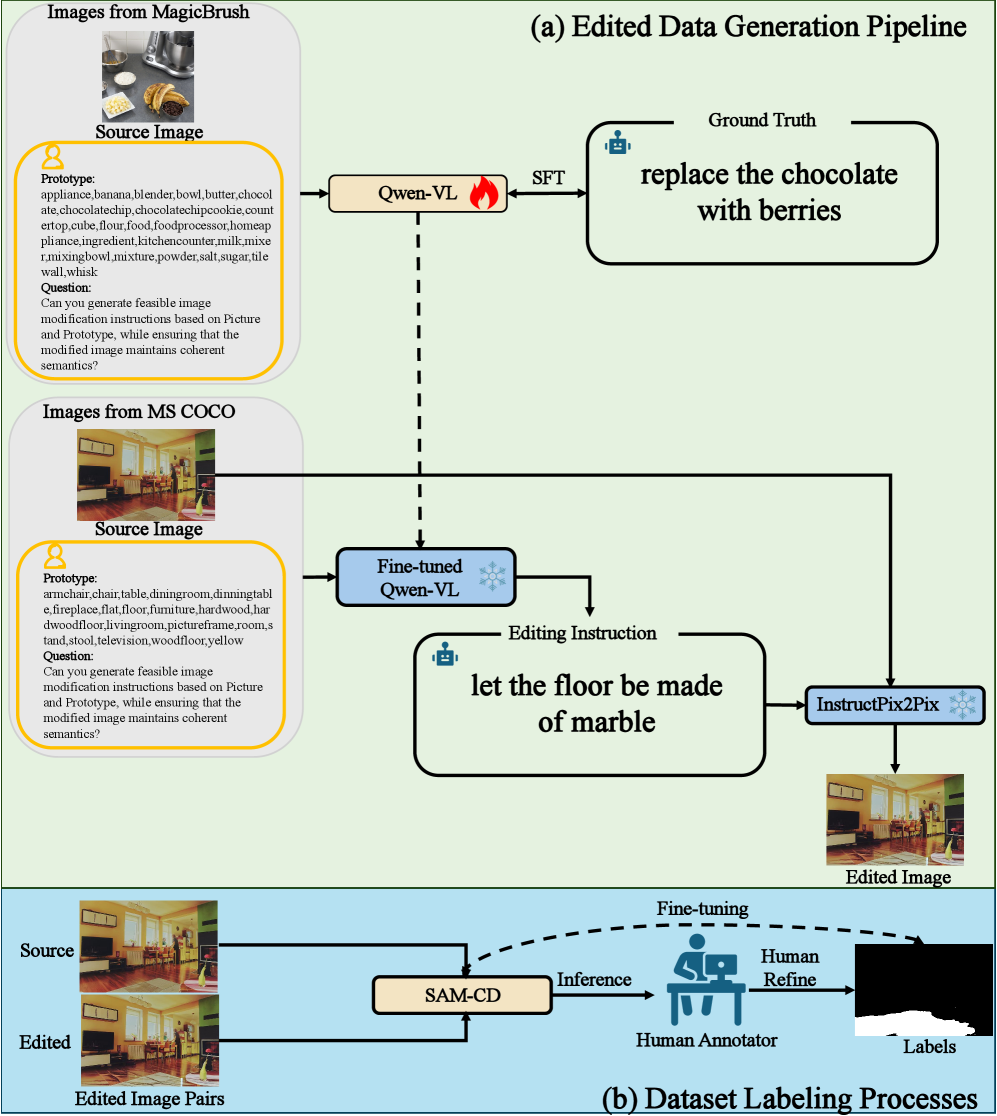
问题定义:论文旨在解决扩散模型图像编辑区域的精确定位问题。现有方法主要针对二元检测或手动编辑,无法有效定位扩散模型生成的平滑融合的编辑区域。缺乏大规模、高质量的针对性数据集也是一个挑战。
核心思路:论文的核心思路是利用视觉基础模型(VFM)提取图像的语义信息,并结合多频提示调整(MFPT)来捕获编辑区域的频率域特征。通过同时关注语义和频率信息,可以更准确地定位扩散模型编辑的区域。
技术框架:整体框架包含两个主要部分:数据集构建和定位模型。数据集构建流程包括:1) 使用多模态大型语言模型生成编辑指令;2) 使用无掩码扩散编辑器生成编辑后的图像;3) 使用主动学习变化检测流程获取像素级标注。定位模型使用冻结的视觉基础模型(VFM)作为主干网络,并引入多频提示调整(MFPT)模块。
关键创新:关键创新在于提出了多频提示调整(MFPT)模块,该模块能够有效地提取编辑区域的频率域特征,并将其与视觉基础模型提取的语义信息相结合。这种结合使得模型能够更准确地定位扩散模型编辑的区域。
关键设计:MFPT模块的具体设计未知,但其核心思想是利用不同频率的提示信息来引导模型关注编辑区域的频率特征。数据集DEAL-300K的构建使用了主动学习策略,以提高标注效率和质量。损失函数未知。
🖼️ 关键图片


📊 实验亮点
该方法在DEAL-300K测试集上达到了82.56%的像素级F1分数,在外部CoCoGlide基准测试上达到了80.97%。这些结果表明,该方法在扩散模型图像编辑区域定位方面具有显著的优势,并为未来的研究提供了强大的基线。
🎯 应用场景
该研究成果可应用于图像取证、版权保护、恶意内容检测等领域。通过精确定位扩散模型编辑的区域,可以帮助识别和溯源伪造图像,维护网络安全和信息安全。未来,该技术还可用于辅助图像编辑,例如自动识别用户想要编辑的区域。
📄 摘要(原文)
Diffusion-based image editing has made semantic level image manipulation easy for general users, but it also enables realistic local forgeries that are hard to localize. Existing benchmarks mainly focus on the binary detection of generated images or the localization of manually edited regions and do not reflect the properties of diffusion-based edits, which often blend smoothly into the original content. We present Diffusion-Based Image Editing Area Localization Dataset (DEAL-300K), a large scale dataset for diffusion-based image manipulation localization (DIML) with more than 300,000 annotated images. We build DEAL-300K by using a multi-modal large language model to generate editing instructions, a mask-free diffusion editor to produce manipulated images, and an active-learning change detection pipeline to obtain pixel-level annotations. On top of this dataset, we propose a localization framework that uses a frozen Visual Foundation Model (VFM) together with Multi Frequency Prompt Tuning (MFPT) to capture both semantic and frequency-domain cues of edited regions. Trained on DEAL-300K, our method reaches a pixel-level F1 score of 82.56% on our test split and 80.97% on the external CoCoGlide benchmark, providing strong baselines and a practical foundation for future DIML research.The dataset can be accessed via https://github.com/ymhzyj/DEAL-300K.