DualCamCtrl: Dual-Branch Diffusion Model for Geometry-Aware Camera-Controlled Video Generation
作者: Hongfei Zhang, Kanghao Chen, Zixin Zhang, Harold Haodong Chen, Yuanhuiyi Lyu, Yuqi Zhang, Shuai Yang, Kun Zhou, Yingcong Chen
分类: cs.CV
发布日期: 2025-11-28 (更新: 2025-12-01)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
DualCamCtrl:用于几何感知相机控制视频生成的双分支扩散模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 相机控制视频生成 扩散模型 双分支网络 深度信息 语义引导 互相对齐 几何感知
📋 核心要点
- 现有相机控制视频生成方法缺乏足够的场景理解和几何感知能力,难以生成高质量视频。
- DualCamCtrl采用双分支框架,分别生成相机一致的RGB和深度序列,从而解耦外观和几何建模。
- 实验表明,DualCamCtrl在相机控制视频生成方面表现出色,相机运动误差比现有方法降低了40%以上。
📝 摘要(中文)
本文提出了一种新颖的端到端扩散模型DualCamCtrl,用于相机控制的视频生成。最近的研究通过将相机姿态表示为基于射线的条件来推进该领域,但它们通常缺乏足够的场景理解和几何感知。DualCamCtrl专门针对这一局限性,引入了一个双分支框架,该框架相互生成相机一致的RGB和深度序列。为了协调这两种模态,我们进一步提出了语义引导互相对齐(SIGMA)机制,该机制以语义引导和相互增强的方式执行RGB-深度融合。这些设计共同使DualCamCtrl能够更好地解耦外观和几何建模,从而生成更忠实于指定相机轨迹的视频。此外,我们分析并揭示了深度和相机姿态在去噪阶段的不同影响,并进一步证明了早期和晚期阶段在形成全局结构和细化局部细节方面起着互补作用。大量实验表明,与现有方法相比,DualCamCtrl实现了更一致的相机控制视频生成,相机运动误差降低了40%以上。
🔬 方法详解
问题定义:现有相机控制视频生成方法,虽然利用射线作为相机姿态的条件,但通常缺乏对场景几何信息的充分理解,导致生成的视频在相机运动一致性方面表现不佳,难以准确反映预设的相机轨迹。
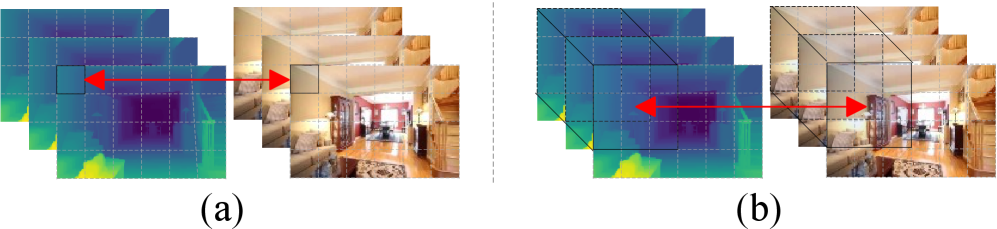
核心思路:DualCamCtrl的核心在于通过显式地建模场景的几何信息(深度),并将其与RGB信息相结合,从而增强模型对场景的理解和几何感知能力。通过双分支结构分别生成RGB和深度序列,并利用语义引导的互相对齐机制(SIGMA)来融合两种模态的信息,从而实现更好的相机控制视频生成。
技术框架:DualCamCtrl采用双分支扩散模型框架。一个分支负责生成RGB序列,另一个分支负责生成深度序列。这两个分支并行工作,并在SIGMA模块中进行信息交互。SIGMA模块利用语义信息来引导RGB和深度特征的对齐,从而实现更有效的模态融合。整个框架以端到端的方式进行训练。
关键创新:DualCamCtrl的关键创新在于以下几点:1) 引入双分支结构,显式地建模深度信息;2) 提出语义引导的互相对齐机制(SIGMA),用于RGB和深度信息的融合;3) 分析了深度和相机姿态在去噪过程中的不同影响,并利用这些信息来优化模型。与现有方法相比,DualCamCtrl能够更好地解耦外观和几何建模,从而生成更符合相机轨迹的视频。
关键设计:SIGMA模块是DualCamCtrl的关键设计之一。它利用预训练的语义分割模型提取RGB图像的语义特征,并利用这些特征来引导RGB和深度特征的对齐。具体来说,SIGMA模块包含一个语义注意力机制,该机制根据语义特征来调整RGB和深度特征的权重。此外,论文还分析了深度和相机姿态在扩散模型的不同去噪阶段的影响,并据此调整了模型的训练策略。例如,在早期阶段,深度信息对全局结构的形成起着重要作用,而在晚期阶段,相机姿态对局部细节的优化更为重要。
🖼️ 关键图片


📊 实验亮点
DualCamCtrl在相机控制视频生成任务上取得了显著的性能提升。实验结果表明,与现有方法相比,DualCamCtrl生成的视频在相机运动一致性方面表现更好,相机运动误差降低了40%以上。这表明DualCamCtrl能够更好地理解场景的几何信息,并生成更符合相机轨迹的视频。
🎯 应用场景
DualCamCtrl在虚拟现实、游戏开发、电影制作等领域具有广泛的应用前景。它可以用于生成逼真的相机控制视频,例如虚拟场景漫游、游戏过场动画、电影特效等。该研究的成果可以帮助开发者更轻松地创建高质量的虚拟内容,并为用户提供更沉浸式的体验。
📄 摘要(原文)
This paper presents DualCamCtrl, a novel end-to-end diffusion model for camera-controlled video generation. Recent works have advanced this field by representing camera poses as ray-based conditions, yet they often lack sufficient scene understanding and geometric awareness. DualCamCtrl specifically targets this limitation by introducing a dual-branch framework that mutually generates camera-consistent RGB and depth sequences. To harmonize these two modalities, we further propose the Semantic Guided Mutual Alignment (SIGMA) mechanism, which performs RGB-depth fusion in a semantics-guided and mutually reinforced manner. These designs collectively enable DualCamCtrl to better disentangle appearance and geometry modeling, generating videos that more faithfully adhere to the specified camera trajectories. Additionally, we analyze and reveal the distinct influence of depth and camera poses across denoising stages and further demonstrate that early and late stages play complementary roles in forming global structure and refining local details. Extensive experiments demonstrate that DualCamCtrl achieves more consistent camera-controlled video generation, with over 40\% reduction in camera motion errors compared with prior methods. Our project page: https://soyouthinkyoucantell.github.io/dualcamctrl-page/