MathSight: A Benchmark Exploring Have Vision-Language Models Really Seen in University-Level Mathematical Reasoning?
作者: Yuandong Wang, Yao Cui, Yuxin Zhao, Zhen Yang, Yangfu Zhu, Zhenzhou Shao
分类: cs.CV, cs.LG
发布日期: 2025-11-28
备注: Comments: 32 pages, 15 figures, 9 tables, includes appendix. Project page: https://cnu-bot-group.github.io/MathSight/
💡 一句话要点
MathSight:评估视觉语言模型在大学数学推理中视觉信息利用程度的基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态推理 数学推理 基准测试 视觉理解 模型评估 视觉信息贡献
📋 核心要点
- 现有视觉语言模型在数学推理中表现出色,但视觉信息贡献度不明,可能过度依赖语言先验。
- MathSight基准通过多种视觉变体(原始、手绘、照片)和纯文本条件,分离并量化视觉输入的影响。
- 实验表明,视觉信息贡献随问题难度增加而降低,纯文本模型甚至超越多模态模型,揭示视觉理解的不足。
📝 摘要(中文)
视觉语言模型(VLM)在多模态数学推理方面取得了显著进展。然而,视觉信息对推理的实际贡献尚不明确。现有基准测试报告了强大的整体性能,但很少分离图像模态的作用,因此VLM是否真正利用视觉理解或仅仅依赖于语言先验仍然未知。为了解决这个问题,我们提出了MathSight,一个大学级别的多模态数学推理基准,旨在分离和量化视觉输入的影响。每个问题包括多个视觉变体——原始图像、手绘图像、照片捕捉图像——以及一个仅文本条件,用于受控比较。对最先进的VLM的实验揭示了一个一致的趋势:视觉信息的贡献随着问题难度的增加而减少。值得注意的是,没有任何图像输入的Qwen3-VL超越了其多模态变体和GPT-5,突显了像MathSight这样的基准对于推进未来模型中真正的视觉基础推理的需求。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLM)在多模态数学推理中,视觉信息贡献度难以评估的问题。现有基准测试虽然报告了VLM的强大性能,但未能有效分离图像模态的作用,无法确定VLM是否真正利用视觉理解,还是仅仅依赖于语言先验。这使得我们难以评估VLM的视觉推理能力,并阻碍了相关研究的进展。
核心思路:论文的核心思路是通过构建一个包含多种视觉变体(原始图像、手绘图像、照片捕捉图像)和纯文本条件的大学级别数学推理基准测试集MathSight,来分离和量化视觉输入对VLM推理的影响。通过比较不同视觉输入条件下VLM的性能,可以更准确地评估VLM的视觉理解能力,并揭示其对视觉信息的依赖程度。
技术框架:MathSight基准测试集包含大学级别的数学推理问题,每个问题都配有多种视觉变体和一个纯文本版本。研究人员可以使用该基准测试集来评估不同的VLM,并分析它们在不同视觉输入条件下的性能。评估流程通常包括:1) 将问题输入VLM;2) VLM生成答案;3) 将生成的答案与正确答案进行比较,计算准确率等指标。通过比较不同视觉变体和纯文本条件下的性能,可以量化视觉信息对VLM推理的贡献。
关键创新:MathSight的关键创新在于其能够有效分离和量化视觉输入对VLM推理的影响。通过提供多种视觉变体和纯文本条件,MathSight允许研究人员更精确地评估VLM的视觉理解能力,并揭示其对视觉信息的依赖程度。这与现有基准测试只关注整体性能,而忽略视觉信息贡献的做法形成了鲜明对比。
关键设计:MathSight的关键设计包括:1) 问题难度:选择大学级别的数学推理问题,以确保问题的复杂性和挑战性;2) 视觉变体:为每个问题提供多种视觉变体(原始图像、手绘图像、照片捕捉图像),以模拟不同的视觉输入条件;3) 纯文本条件:为每个问题提供纯文本版本,作为基线,用于评估视觉信息的贡献;4) 评估指标:使用准确率等指标来评估VLM在不同视觉输入条件下的性能。
🖼️ 关键图片

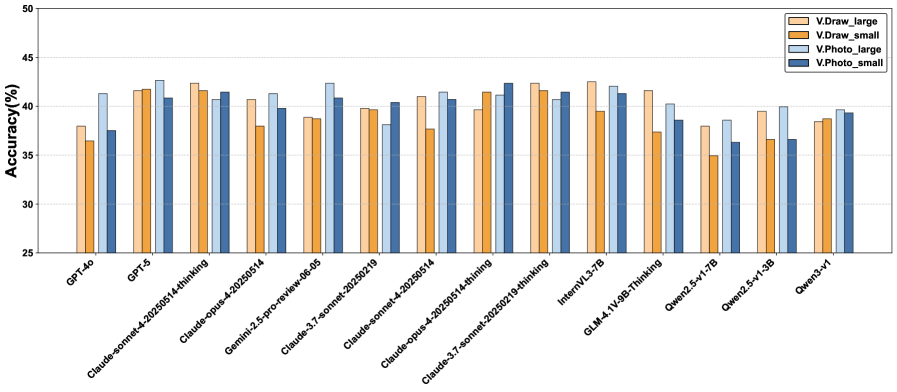
📊 实验亮点
实验结果表明,随着问题难度的增加,视觉信息的贡献逐渐减小。令人惊讶的是,没有任何图像输入的Qwen3-VL模型,其性能甚至超越了其多模态变体以及GPT-5模型。这突显了当前VLM在视觉推理方面的不足,并强调了MathSight这类基准测试对于推动未来模型中真正的视觉基础推理的重要性。
🎯 应用场景
MathSight基准测试集可用于评估和改进视觉语言模型在数学、物理等需要视觉理解的科学领域的推理能力。通过分析模型在不同视觉输入下的表现,可以指导模型设计,提升其视觉信息利用效率,最终促进更智能、更可靠的AI系统在教育、科研等领域的应用。
📄 摘要(原文)
Recent advances in Vision-Language Models (VLMs) have achieved impressive progress in multimodal mathematical reasoning. Yet, how much visual information truly contributes to reasoning remains unclear. Existing benchmarks report strong overall performance but seldom isolate the role of the image modality, leaving open whether VLMs genuinely leverage visual understanding or merely depend on linguistic priors. To address this, we present MathSight, a university-level multimodal mathematical reasoning benchmark designed to disentangle and quantify the effect of visual input. Each problem includes multiple visual variants -- original, hand-drawn, photo-captured -- and a text-only condition for controlled comparison. Experiments on state-of-the-art VLMs reveal a consistent trend: the contribution of visual information diminishes with increasing problem difficulty. Remarkably, Qwen3-VL without any image input surpasses both its multimodal variants and GPT-5, underscoring the need for benchmarks like MathSight to advance genuine vision-grounded reasoning in future models.