HMR3D: Hierarchical Multimodal Representation for 3D Scene Understanding with Large Vision-Language Model
作者: Chen Li, Eric Peh, Basura Fernando
分类: cs.CV
发布日期: 2025-11-28
💡 一句话要点
HMR3D:利用大型视觉语言模型进行3D场景理解的分层多模态表示
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 视觉语言模型 多模态融合 分层表示 3D问答
📋 核心要点
- 现有基于VLM的3D场景理解方法依赖隐式对齐,受限于3D数据稀缺和空间关系复杂性,性能欠佳。
- HMR3D利用多视角图像和文本描述,在输入空间显式对齐VLM,并引入分层特征表示,提升场景理解能力。
- 实验表明,HMR3D在3D情境问答和通用3D问答基准测试上表现出色,验证了其有效性。
📝 摘要(中文)
本文提出了一种用于3D场景理解的分层多模态表示方法HMR3D,旨在解决现有基于视觉语言模型(VLM)的方法在3D场景理解中因3D数据稀缺和空间关系复杂而导致的性能瓶颈。HMR3D通过利用多视角图像和文本描述,在输入空间显式地与VLM对齐。文本描述通过引用检测到的对象的3D坐标来捕获空间关系,而多视角图像包括俯视图和四个方向视图(前、左、右、后),确保全面的场景覆盖。此外,引入分层特征表示,将patch级别的图像特征聚合为视图级别和场景级别的表示,使模型能够推理局部和全局场景上下文。在3D情境问答和通用3D问答基准测试上的实验结果表明了该方法的有效性。
🔬 方法详解
问题定义:现有基于视觉语言模型(VLM)的3D场景理解方法,通常将3D场景特征与VLM的嵌入空间进行隐式对齐。这种隐式对齐方式由于3D数据的稀缺以及3D环境中空间关系的复杂性,导致性能不佳。现有方法难以充分利用VLM的强大能力进行3D场景的推理和理解。
核心思路:HMR3D的核心思路是通过显式地将3D场景信息与VLM的输入空间对齐,来提升3D场景理解的性能。具体来说,它利用多视角图像和文本描述作为输入,文本描述包含对象的3D坐标信息,从而让VLM能够更好地理解场景中的空间关系。同时,通过分层特征表示,模型可以同时关注局部和全局的场景上下文。
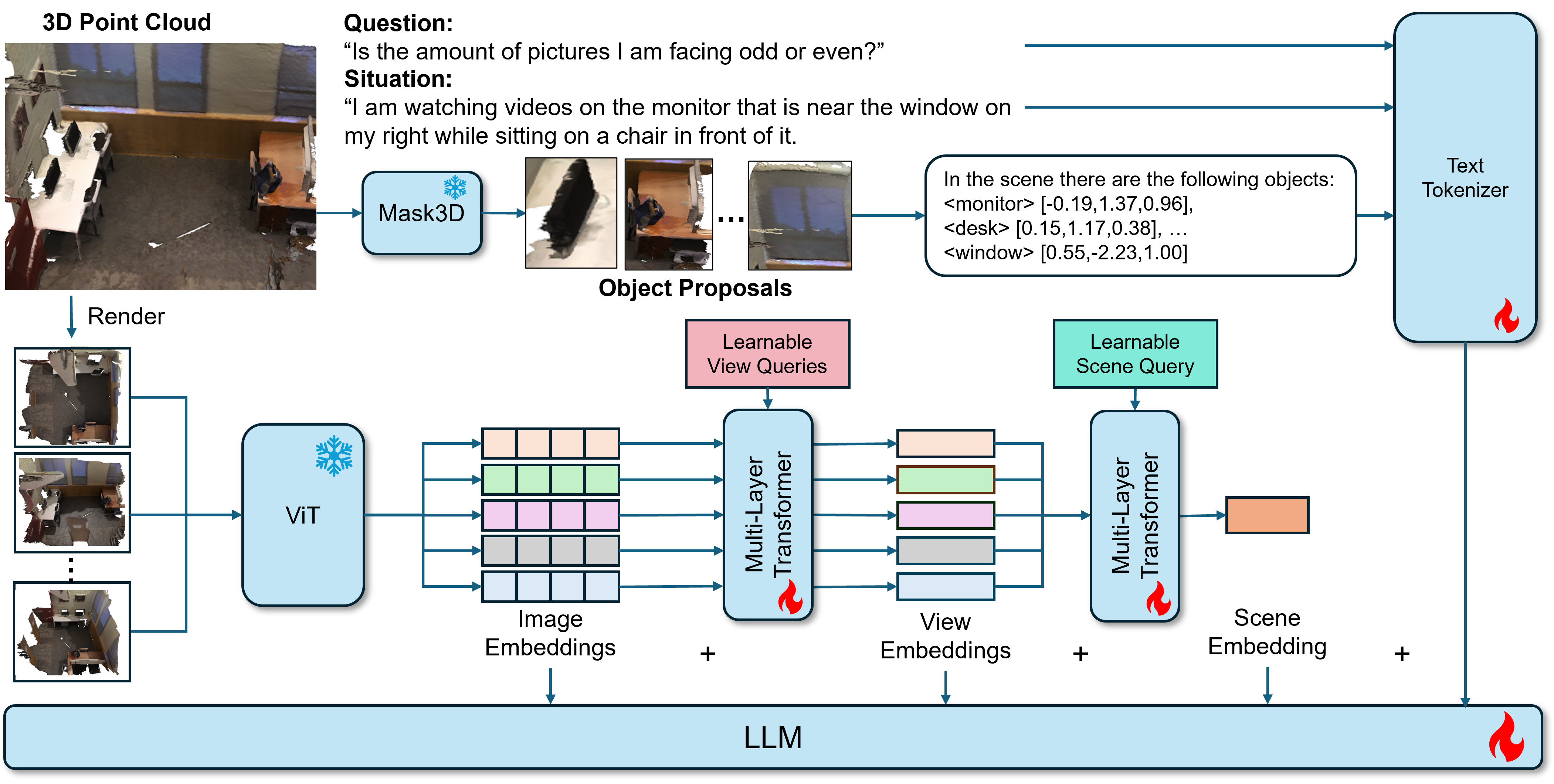
技术框架:HMR3D的整体框架包括以下几个主要模块:1) 多视角图像编码器:用于提取多视角图像的特征表示。2) 文本描述编码器:用于提取文本描述的特征表示,文本描述包含3D坐标信息。3) 分层特征聚合模块:将patch级别的图像特征聚合为视图级别和场景级别的表示。4) VLM:利用VLM进行3D场景的推理和问答。整个流程是将多视角图像和文本描述输入到各自的编码器中,然后通过分层特征聚合模块得到场景级别的表示,最后将该表示输入到VLM中进行推理。
关键创新:HMR3D的关键创新在于其显式的多模态对齐方式和分层特征表示。与现有方法隐式地将3D特征与VLM对齐不同,HMR3D在输入空间就将多视角图像和文本描述与VLM对齐,从而更好地利用VLM的能力。此外,分层特征表示使得模型能够同时关注局部和全局的场景上下文,提升了场景理解的精度。
关键设计:多视角图像包括俯视图和四个方向视图(前、左、右、后),确保全面的场景覆盖。文本描述通过引用检测到的对象的3D坐标来捕获空间关系。分层特征聚合模块将patch级别的图像特征聚合为视图级别和场景级别的表示,具体实现方式未知。损失函数和网络结构的具体细节在摘要中未提及,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文在3D情境问答和通用3D问答基准测试上进行了实验,结果表明HMR3D方法显著优于现有方法。具体的性能数据和提升幅度在摘要中未给出,属于未知信息。实验结果验证了HMR3D在3D场景理解方面的有效性。
🎯 应用场景
HMR3D技术可应用于机器人导航、智能家居、自动驾驶等领域。通过提升3D场景理解能力,可以使机器人更好地感知周围环境,从而实现更智能的交互和决策。在智能家居中,可以实现更精准的场景识别和物体定位,提升用户体验。在自动驾驶领域,可以提高车辆对复杂交通环境的理解能力,增强安全性。
📄 摘要(原文)
Recent advances in large vision-language models (VLMs) have shown significant promise for 3D scene understanding. Existing VLM-based approaches typically align 3D scene features with the VLM's embedding space. However, this implicit alignment often yields suboptimal performance due to the scarcity of 3D data and the inherent complexity of spatial relationships in 3D environments. To address these limitations, we propose a novel hierarchical multimodal representation for 3D scene reasoning that explicitly aligns with VLMs at the input space by leveraging both multi-view images and text descriptions. The text descriptions capture spatial relationships by referencing the 3D coordinates of detected objects, while the multi-view images include a top-down perspective and four directional views (forward, left, right, and backward), ensuring comprehensive scene coverage. Additionally, we introduce a hierarchical feature representation that aggregates patch-level image features into view-level and scene-level representations, enabling the model to reason over both local and global scene context. Experimental results on both situated 3D Q&A and general 3D Q&A benchmarks demonstrate the effectiveness of our approach.