See, Rank, and Filter: Important Word-Aware Clip Filtering via Scene Understanding for Moment Retrieval and Highlight Detection
作者: YuEun Lee, Jung Uk Kim
分类: cs.CV
发布日期: 2025-11-28
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于重要词感知的视频片段过滤方法,用于视频时刻检索和高光检测。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频时刻检索 高光检测 多模态学习 重要词感知 视频理解
📋 核心要点
- 现有视频时刻检索和高光检测方法忽略了查询中各个词语的重要性,将文本查询和视频片段视为黑盒,阻碍了上下文理解。
- 论文提出一种基于重要词感知的视频片段过滤方法,通过多模态大语言模型进行场景理解,并使用特征增强和排序过滤模块。
- 实验结果表明,该方法在视频时刻检索和高光检测任务中显著优于现有方法,性能得到大幅提升。
📝 摘要(中文)
本文提出了一种新颖的方法,通过识别和优先考虑查询中的重要词语来实现细粒度的视频片段过滤,从而解决视频时刻检索(MR)和高光检测(HD)任务中现有方法忽略单个词语重要性的问题。该方法通过多模态大型语言模型(MLLM)整合图像-文本场景理解,并增强对视频片段的语义理解。我们引入了一个特征增强模块(FEM)来捕获查询中的重要词语,以及一个基于排序的过滤模块(RFM)来迭代地细化视频片段,使其与这些重要词语的相关性更高。大量实验表明,我们的方法显著优于现有的最先进方法,在MR和HD任务中均取得了卓越的性能。
🔬 方法详解
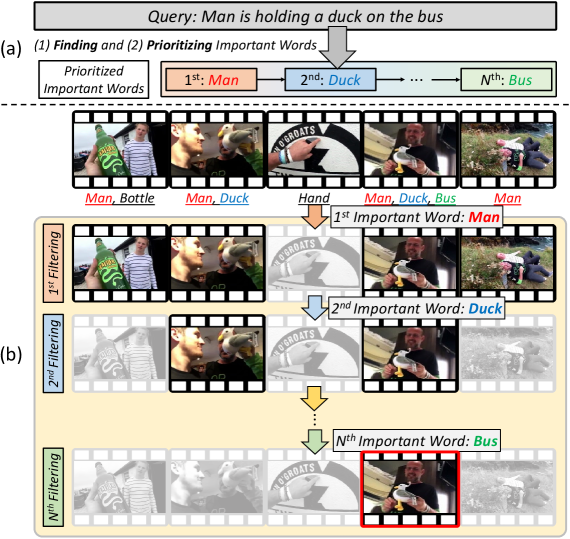
问题定义:视频时刻检索(MR)和高光检测(HD)旨在从视频中定位与自然语言查询相关的时刻和关键片段。现有方法通常将整个文本查询和视频片段视为一个整体,忽略了查询中不同词语的重要性,导致无法充分理解上下文信息,影响检索和检测的准确性。
核心思路:论文的核心思路是识别并优先考虑查询中的重要词语,通过这些重要词语来指导视频片段的过滤和排序。通过关注关键信息,可以更准确地理解查询意图,并找到与查询相关的视频片段。
技术框架:该方法包含以下主要模块:1) 特征提取模块:提取文本查询和视频片段的特征表示。2) 特征增强模块(FEM):用于捕获查询中的重要词语,并增强其特征表示。3) 基于排序的过滤模块(RFM):根据视频片段与重要词语的相关性,迭代地细化视频片段,过滤掉不相关的片段。4) 预测模块:基于过滤后的视频片段特征,预测视频时刻或高光片段。
关键创新:该方法最重要的创新点在于引入了重要词感知的视频片段过滤机制。通过特征增强模块和排序过滤模块,可以有效地识别和利用查询中的重要词语,从而提高视频时刻检索和高光检测的准确性。与现有方法相比,该方法更加关注查询中的关键信息,能够更好地理解上下文信息。
关键设计:特征增强模块(FEM)可能使用了注意力机制或其他词语重要性评估方法来识别重要词语。排序过滤模块(RFM)可能采用了迭代排序和过滤策略,逐步提高视频片段与重要词语的相关性。损失函数的设计可能包括相关性损失和排序损失,以优化模型的性能。具体的网络结构和参数设置需要在代码中进一步分析。
🖼️ 关键图片


📊 实验亮点
论文通过大量实验验证了所提出方法的有效性,在视频时刻检索和高光检测任务中均取得了显著的性能提升。与现有最先进方法相比,该方法在两个任务上均取得了优越的性能,证明了重要词感知过滤机制的有效性。具体的性能数据和提升幅度可以在论文中找到。
🎯 应用场景
该研究成果可应用于视频搜索引擎、智能视频编辑、内容推荐等领域。通过更精确地理解用户查询意图,可以提供更相关的视频内容,提升用户体验。此外,该技术还可以用于自动生成视频摘要和高光片段,提高视频内容的处理效率。
📄 摘要(原文)
Video moment retrieval (MR) and highlight detection (HD) with natural language queries aim to localize relevant moments and key highlights in a video clips. However, existing methods overlook the importance of individual words, treating the entire text query and video clips as a black-box, which hinders contextual understanding. In this paper, we propose a novel approach that enables fine-grained clip filtering by identifying and prioritizing important words in the query. Our method integrates image-text scene understanding through Multimodal Large Language Models (MLLMs) and enhances the semantic understanding of video clips. We introduce a feature enhancement module (FEM) to capture important words from the query and a ranking-based filtering module (RFM) to iteratively refine video clips based on their relevance to these important words. Extensive experiments demonstrate that our approach significantly outperforms existing state-of-the-art methods, achieving superior performance in both MR and HD tasks. Our code is available at: https://github.com/VisualAIKHU/SRF.