CoordSpeaker: Exploiting Gesture Captioning for Coordinated Caption-Empowered Co-Speech Gesture Generation
作者: Fengyi Fang, Sicheng Yang, Wenming Yang
分类: cs.CV
发布日期: 2025-11-28
💡 一句话要点
CoordSpeaker:利用手势描述生成,实现协同的、文本驱动的口语手势生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 口语手势生成 手势描述 条件扩散模型 多模态融合 人机交互
📋 核心要点
- 现有口语手势生成方法缺乏描述性文本标注,导致语义先验不足,限制了非自发性手势的生成。
- CoordSpeaker通过手势描述框架弥补语义鸿沟,并利用条件潜在扩散模型实现协同的、文本驱动的手势生成。
- 实验表明,CoordSpeaker能生成与语音节奏同步、语义与文本描述一致的高质量手势,性能和效率均优于现有方法。
📝 摘要(中文)
本文提出CoordSpeaker框架,旨在实现协同的、文本驱动的口语手势合成,以提升人机交互体验。现有方法由于手势数据集缺乏描述性文本标注,存在语义先验差距,且难以实现对手势生成的多模态协同控制。CoordSpeaker首先通过手势描述框架弥补语义先验差距,利用运动-语言模型生成多粒度的描述性文本。在此基础上,提出了一种条件潜在扩散模型,该模型具有统一的跨数据集运动表示和分层控制的去噪器,从而实现高度可控的协同手势生成。CoordSpeaker率先探索了手势理解和描述在手势生成中的应用,并提供了一种双向手势-文本映射的新视角。实验结果表明,该方法能够生成高质量的手势,这些手势不仅与语音节奏同步,而且在语义上与任意文本描述一致,与现有方法相比,实现了更高的性能和效率。
🔬 方法详解
问题定义:现有口语手势生成方法主要面临两个问题:一是手势数据集缺乏描述性文本标注,导致模型缺乏对手势语义的理解,存在语义先验差距;二是难以实现对手势生成过程的多模态协同控制,例如无法根据文本描述精确控制手势的幅度、类型等。这些问题限制了生成手势的自然性和多样性。
核心思路:CoordSpeaker的核心思路是首先通过手势描述(Gesture Captioning)来弥补语义先验差距,然后利用条件潜在扩散模型实现高度可控的手势生成。通过手势描述,模型可以学习到手势的语义信息,从而更好地理解文本描述,并生成与之对应的手势。条件潜在扩散模型则提供了更精细的控制能力,可以根据文本描述调整手势的各个方面。
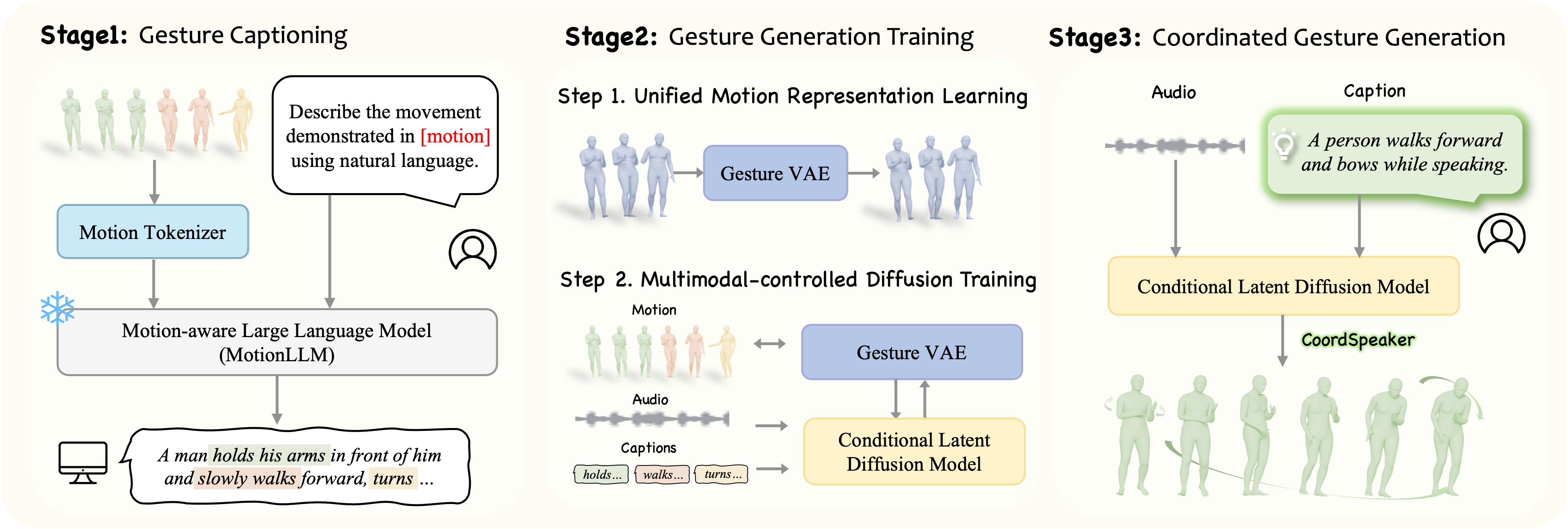
技术框架:CoordSpeaker框架主要包含两个阶段:1) 手势描述阶段:利用运动-语言模型,对手势进行多粒度的描述性文本生成,从而为手势赋予语义信息。2) 手势生成阶段:构建一个条件潜在扩散模型,该模型以语音和文本描述作为条件,生成与语音节奏同步、语义与文本描述一致的手势。该模型采用统一的跨数据集运动表示,并设计了一个分层控制的去噪器,以实现高度可控的手势生成。
关键创新:CoordSpeaker的关键创新在于:1) 首次将手势描述应用于手势生成任务,弥补了语义先验差距。2) 提出了一个条件潜在扩散模型,该模型具有统一的跨数据集运动表示和分层控制的去噪器,实现了高度可控的手势生成。3) 提出了一个双向手势-文本映射的新视角,为手势理解和生成提供了新的思路。
关键设计:在手势描述阶段,采用了多粒度的描述性文本生成,包括粗粒度的动作描述和细粒度的属性描述。在手势生成阶段,条件潜在扩散模型采用U-Net结构,以语音和文本描述作为条件输入,通过分层控制的去噪器逐步生成手势。损失函数包括重建损失、对抗损失和一致性损失,以保证生成手势的质量和一致性。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CoordSpeaker在手势生成质量和效率方面均优于现有方法。通过定量评估和定性分析,证明了CoordSpeaker能够生成与语音节奏同步、语义与文本描述一致的高质量手势。与基线方法相比,CoordSpeaker在多个指标上取得了显著提升,例如在手势自然度、语义一致性等方面。
🎯 应用场景
CoordSpeaker的研究成果可广泛应用于人机交互、虚拟助手、游戏、教育等领域。通过生成更自然、更具表现力的口语手势,可以提升用户体验,增强人机交互的真实感和趣味性。未来,该技术有望应用于智能客服、虚拟主播等场景,实现更高效、更自然的沟通。
📄 摘要(原文)
Co-speech gesture generation has significantly advanced human-computer interaction, yet speaker movements remain constrained due to the omission of text-driven non-spontaneous gestures (e.g., bowing while talking). Existing methods face two key challenges: 1) the semantic prior gap due to the lack of descriptive text annotations in gesture datasets, and 2) the difficulty in achieving coordinated multimodal control over gesture generation. To address these challenges, this paper introduces CoordSpeaker, a comprehensive framework that enables coordinated caption-empowered co-speech gesture synthesis. Our approach first bridges the semantic prior gap through a novel gesture captioning framework, leveraging a motion-language model to generate descriptive captions at multiple granularities. Building upon this, we propose a conditional latent diffusion model with unified cross-dataset motion representation and a hierarchically controlled denoiser to achieve highly controlled, coordinated gesture generation. CoordSpeaker pioneers the first exploration of gesture understanding and captioning to tackle the semantic gap in gesture generation while offering a novel perspective of bidirectional gesture-text mapping. Extensive experiments demonstrate that our method produces high-quality gestures that are both rhythmically synchronized with speeches and semantically coherent with arbitrary captions, achieving superior performance with higher efficiency compared to existing approaches.