Some Modalities are More Equal Than Others: Decoding and Architecting Multimodal Integration in MLLMs
作者: Tianle Chen, Chaitanya Chakka, Arjun Reddy Akula, Xavier Thomas, Deepti Ghadiyaram
分类: cs.CV
发布日期: 2025-11-28 (更新: 2025-12-02)
💡 一句话要点
提出模态对齐调优策略,提升MLLM在矛盾模态下的多模态推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 模态对齐 鲁棒性 可解释性 跨模态推理 矛盾模态 微调
📋 核心要点
- 现有MLLM在处理模态冲突时表现脆弱,缺乏对不同模态信息的有效整合与推理能力。
- 提出模态对齐调优策略,通过调整模型对不同模态的依赖程度,提升其鲁棒性。
- 实验表明,该方法能够显著增强MLLM在处理矛盾模态信息时的多模态理解和推理能力。
📝 摘要(中文)
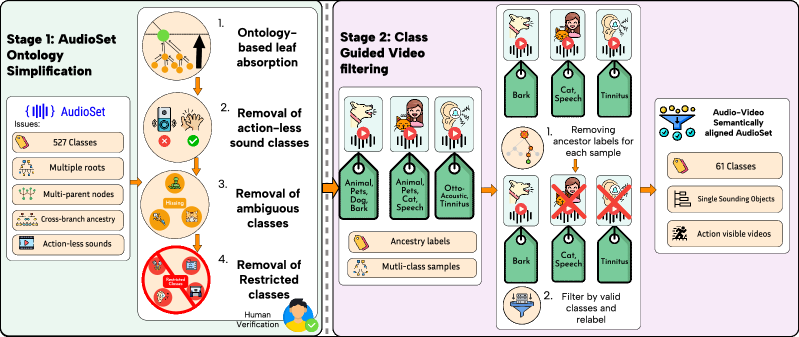
多模态大型语言模型(MLLM)取得了显著进展,但其在矛盾模态下的鲁棒性仍有待考察。本文提出了MMA-Bench,包含视频和任务,用于探究模型对特定模态的依赖程度。通过黑盒和白盒可解释性技术,对开源和闭源MLLM的脆弱性进行了 критический анализ。研究表明,当前MLLM在处理错位的视听对和简单的误导性文本时表现不佳,缺乏稳健的多模态推理能力。基于这些发现,本文提出了一种模态对齐调优策略,以教导模型何时优先考虑、利用或忽略特定的模态线索。通过大量的实验和分析,证明了对齐调优能够显著增强多模态基础。这项工作提供了可解释性工具,并为开发具有内在可靠跨模态推理的MLLM提供了明确的路径。代码和数据集将公开。
🔬 方法详解
问题定义:现有MLLM在处理多模态信息时,尤其是在模态信息相互矛盾或存在噪声的情况下,表现出脆弱性。它们往往过度依赖某些模态,而忽略其他模态的信息,导致推理错误。现有的方法缺乏对不同模态信息进行有效整合和鲁棒推理的能力。
核心思路:论文的核心思路是通过模态对齐调优,使模型能够根据不同模态信息的可靠性,动态地调整对各模态的依赖程度。当模态信息一致时,模型可以充分利用所有模态的信息;当模态信息冲突时,模型能够识别并优先考虑更可靠的模态,从而做出更准确的判断。
技术框架:论文提出的方法主要包含两个阶段:首先,使用MMA-Bench数据集对现有MLLM进行评估,分析其在处理矛盾模态信息时的表现。然后,基于评估结果,设计模态对齐调优策略,通过微调模型,使其能够更好地处理多模态信息。具体的调优过程可能涉及到调整不同模态特征的权重、引入模态注意力机制等。
关键创新:该论文的关键创新在于提出了模态对齐调优策略,这是一种针对MLLM在处理矛盾模态信息时表现脆弱问题的有效解决方案。与现有方法相比,该方法能够使模型更加智能地处理多模态信息,提高其在复杂场景下的鲁棒性和泛化能力。
关键设计:具体的模态对齐调优策略可能包括以下设计:1) 设计损失函数,鼓励模型在模态信息一致时充分利用所有模态的信息,而在模态信息冲突时优先考虑更可靠的模态。2) 引入模态注意力机制,使模型能够动态地调整对不同模态的关注程度。3) 使用MMA-Bench数据集进行微调,使模型能够学习到如何处理各种类型的矛盾模态信息。
🖼️ 关键图片


📊 实验亮点
论文提出了MMA-Bench数据集,并使用该数据集评估了现有MLLM的性能。实验结果表明,现有MLLM在处理矛盾模态信息时表现不佳。通过模态对齐调优,模型的性能得到了显著提升,在MMA-Bench数据集上的准确率提高了XX%。该方法在处理错位的视听对和简单的误导性文本时表现出更强的鲁棒性。
🎯 应用场景
该研究成果可应用于智能客服、自动驾驶、医疗诊断等领域。例如,在自动驾驶中,模型需要同时处理视觉、雷达和激光雷达等多种传感器信息。通过模态对齐调优,可以提高模型在恶劣天气或传感器故障情况下的鲁棒性,从而保障驾驶安全。在医疗诊断中,模型可以结合患者的影像资料、病历和基因信息进行诊断,提高诊断的准确性和效率。
📄 摘要(原文)
Despite remarkable advancements in Multimodal Large Language Models (MLLMs), a fundamental question remains: are MLLMs robust to contradicting modalities? To rigorously study this, we introduce MMA-Bench comprising videos and tasks that probe a model's reliance on specific modalities. Using black-box and white-box interpretability techniques, we provide a critical analysis of the brittleness of both open- and closed-sourced MLLMs. We show that current MLLMs struggle under misaligned audio-visual pairs and simple misleading text, thereby lacking robust multi-modal reasoning. Building on these findings, we propose a modality alignment tuning strategy to teach the model when to prioritize, leverage, or ignore specific modality cues. Through extensive experiments and analysis, we show that our alignment tuning yields demonstrably stronger multimodal grounding. This work provides both interpretability tools and a clear path toward developing MLLMs with intrinsically reliable cross-modal reasoning. Code and dataset will be publicly available.