Show Me: Unifying Instructional Image and Video Generation with Diffusion Models
作者: Yujiang Pu, Zhanbo Huang, Vishnu Boddeti, Yu Kong
分类: cs.CV
发布日期: 2025-11-21
备注: Accepted by WACV 2026
💡 一句话要点
ShowMe:利用扩散模型统一指令图像和视频生成任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 视频生成 图像操作 扩散模型 视觉指令 时序建模
📋 核心要点
- 现有图像操作方法忽略了动作的时间演变,而视频预测模型则忽视了目标导向性,导致视觉指令生成效果不佳。
- ShowMe通过统一视频扩散模型的空间和时间组件,同时结合结构和运动一致性奖励,实现了指令图像和视频的统一生成。
- 实验表明,ShowMe在指令图像和视频生成任务上均优于现有方法,验证了视频扩散模型作为统一状态转换器的有效性。
📝 摘要(中文)
在给定上下文中生成视觉指令对于开发交互式世界模拟器至关重要。现有工作通常孤立地处理文本引导的图像操作或视频预测任务。这种分离揭示了一个根本问题:图像操作方法忽略了动作随时间的展开,而视频预测模型通常忽略了预期的结果。为此,我们提出了ShowMe,一个统一的框架,通过选择性地激活视频扩散模型的空间和时间组件来实现这两个任务。此外,我们引入了结构和运动一致性奖励,以提高结构保真度和时间连贯性。值得注意的是,这种统一带来了双重好处:通过视频预训练获得的空间知识增强了非刚性图像编辑中的上下文一致性和真实感,而指令引导的操作阶段使模型具有更强的面向目标的视频预测推理能力。在各种基准测试上的实验表明,我们的方法在指令图像和视频生成方面优于专家模型,突出了视频扩散模型作为统一的动作-对象状态转换器的优势。
🔬 方法详解
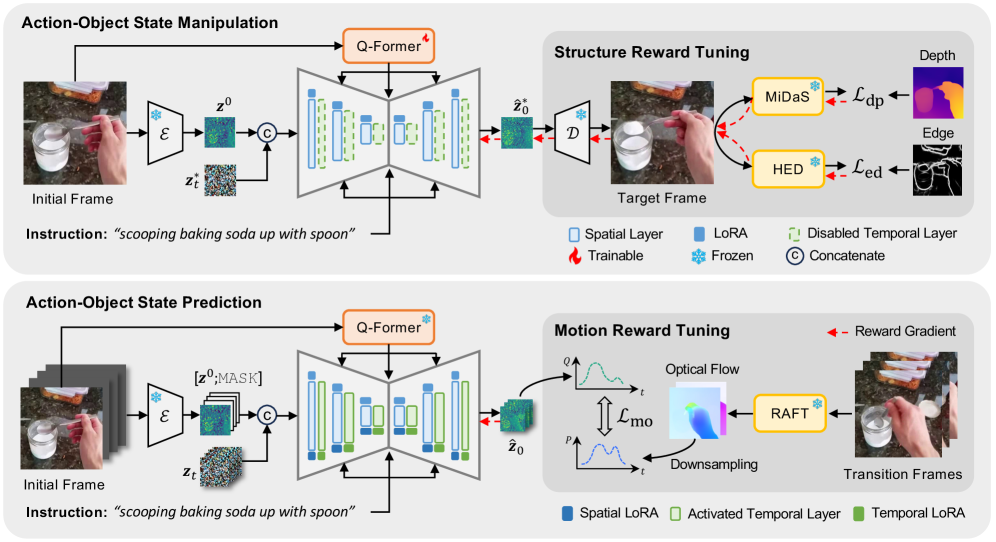
问题定义:现有方法在生成视觉指令时,通常将图像操作和视频预测视为独立任务。图像操作方法缺乏对动作时序性的建模,导致生成的图像序列不连贯;而视频预测模型则忽略了指令的目标,难以生成符合预期结果的视频。因此,如何统一处理图像操作和视频预测,生成既符合指令目标又具有时序连贯性的视觉内容,是一个亟待解决的问题。
核心思路:ShowMe的核心思路是利用视频扩散模型同时建模图像的空间信息和视频的时序信息,并通过选择性地激活模型的空间和时间组件,实现图像操作和视频预测的统一。此外,引入结构和运动一致性奖励,进一步提升生成结果的质量。
技术框架:ShowMe的整体框架基于视频扩散模型,包含以下主要模块:1) 视频扩散模型:用于建模图像和视频的联合分布;2) 空间组件激活:用于图像操作任务,侧重于对图像的空间信息进行修改;3) 时间组件激活:用于视频预测任务,侧重于对视频的时序信息进行建模;4) 结构一致性奖励:用于保证图像操作过程中结构的稳定性;5) 运动一致性奖励:用于保证视频预测过程中运动的平滑性。
关键创新:ShowMe的关键创新在于:1) 提出了一个统一的框架,能够同时处理图像操作和视频预测任务;2) 通过选择性地激活视频扩散模型的空间和时间组件,实现了对图像和视频信息的灵活控制;3) 引入了结构和运动一致性奖励,有效提升了生成结果的质量。
关键设计:ShowMe的关键设计包括:1) 视频扩散模型的选择:具体使用的视频扩散模型未知,但需要能够同时处理图像和视频数据;2) 空间和时间组件的激活方式:具体激活方式未知,可能通过mask或者注意力机制实现;3) 结构一致性奖励的定义:可能基于图像的结构特征,如边缘、角点等;4) 运动一致性奖励的定义:可能基于光流或者其他运动估计方法。
🖼️ 关键图片


📊 实验亮点
ShowMe在多个基准测试上取得了显著的性能提升。在指令图像生成任务上,ShowMe生成的图像在上下文一致性和真实感方面优于现有方法。在视频预测任务上,ShowMe生成的视频在目标导向性和时序连贯性方面表现更佳。具体性能数据未知,但论文强调ShowMe在两个任务上均超越了专家模型。
🎯 应用场景
ShowMe具有广泛的应用前景,例如:1) 交互式游戏开发:可以根据玩家的指令生成相应的游戏场景和角色动作;2) 虚拟现实/增强现实:可以根据用户的需求生成个性化的虚拟体验;3) 教育领域:可以生成教学视频,帮助学生更好地理解抽象概念;4) 机器人控制:可以生成机器人的操作指令,引导机器人完成特定任务。该研究有望推动交互式视觉内容生成技术的发展。
📄 摘要(原文)
Generating visual instructions in a given context is essential for developing interactive world simulators. While prior works address this problem through either text-guided image manipulation or video prediction, these tasks are typically treated in isolation. This separation reveals a fundamental issue: image manipulation methods overlook how actions unfold over time, while video prediction models often ignore the intended outcomes. To this end, we propose ShowMe, a unified framework that enables both tasks by selectively activating the spatial and temporal components of video diffusion models. In addition, we introduce structure and motion consistency rewards to improve structural fidelity and temporal coherence. Notably, this unification brings dual benefits: the spatial knowledge gained through video pretraining enhances contextual consistency and realism in non-rigid image edits, while the instruction-guided manipulation stage equips the model with stronger goal-oriented reasoning for video prediction. Experiments on diverse benchmarks demonstrate that our method outperforms expert models in both instructional image and video generation, highlighting the strength of video diffusion models as a unified action-object state transformer.