Toward explainable AI approaches for breast imaging: adapting foundation models to diverse populations
作者: Guilherme J. Cavalcante, José Gabriel A. Moreira, Gabriel A. B. do Nascimento, Vincent Dong, Alex Nguyen, Thaís G. do Rêgo, Yuri Malheiros, Telmo M. Silva Filho, Carla R. Zeballos Torrez, James C. Gee, Anne Marie McCarthy, Andrew D. A. Maidment, Bruno Barufaldi
分类: cs.CV, cs.AI
发布日期: 2025-11-21
备注: 5 pages, 3 figures
💡 一句话要点
利用BiomedCLIP,针对不同人群的乳腺影像可解释AI方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 乳腺影像 Foundation Model BiomedCLIP 多模态学习 类别不平衡 可解释AI 乳腺密度分类
📋 核心要点
- 乳腺影像分析面临模型泛化性挑战,现有方法难以适应不同成像模态和人群。
- 本研究利用BiomedCLIP,通过多模态训练和加权对比学习,提升模型在不同乳腺影像数据上的泛化能力。
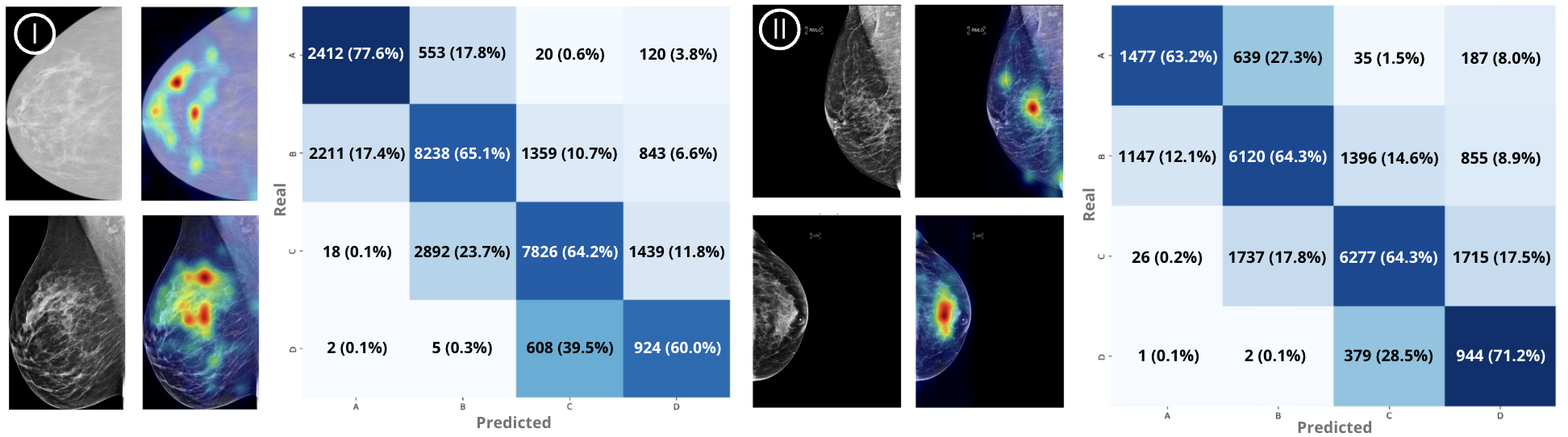
- 实验结果表明,该方法在乳腺密度分类任务上取得了良好性能,并在外部数据集上展现出强大的泛化能力。
📝 摘要(中文)
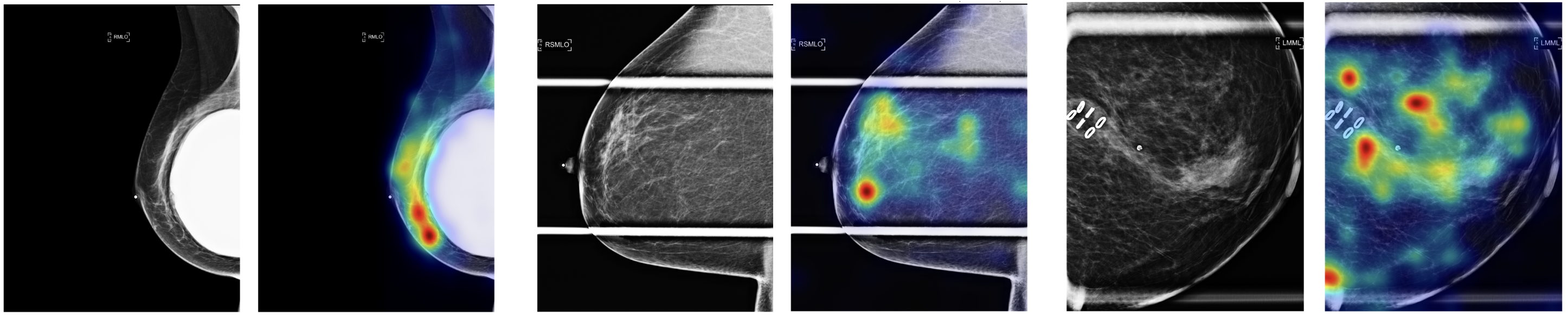
本研究探索了Foundation Model在乳腺影像领域的应用潜力,特别是针对模型泛化性的挑战。研究采用BiomedCLIP作为基础模型,并将其应用于多模态乳腺钼靶数据的BI-RADS乳腺密度自动分类(包括合成2D图像、数字乳腺钼靶摄影和数字乳腺断层合成)。使用96,995张图像,比较了单模态(仅s2D)和多模态训练方法,并通过加权对比学习解决类别不平衡问题。两种方法都取得了相似的准确率(多模态:0.74,单模态:0.73),但多模态模型在不同成像模式中具有更广泛的适用性,并且在BI-RADS类别中始终保持高于0.84的AUC值。在RSNA和EMBED数据集上的外部验证显示出强大的泛化能力(AUC范围:0.80-0.93)。GradCAM可视化证实了一致且临床相关的注意力模式,突出了模型的可解释性和鲁棒性。这项研究强调了基础模型在乳腺影像应用中的潜力,为未来诊断任务的扩展铺平了道路。
🔬 方法详解
问题定义:乳腺影像分析,特别是乳腺密度分类,面临着数据异质性和模态多样性的挑战。现有的深度学习方法往往在特定数据集上表现良好,但在面对新的成像模态或不同人群的数据时,泛化能力不足。类别不平衡问题也进一步加剧了模型训练的难度。
核心思路:本研究的核心思路是利用预训练的Foundation Model(BiomedCLIP)的强大表征学习能力,并结合多模态训练和加权对比学习,从而提升模型在不同乳腺影像数据上的泛化性和鲁棒性。通过利用预训练模型的先验知识,可以减少对大规模标注数据的依赖,并提高模型在新数据上的适应能力。
技术框架:整体框架包括以下几个主要阶段:1) 数据预处理:对不同模态的乳腺影像数据进行预处理,包括图像大小调整、归一化等。2) 特征提取:使用BiomedCLIP提取图像的特征表示。3) 模型训练:使用提取的特征进行BI-RADS乳腺密度分类模型的训练,分别采用单模态和多模态训练策略。4) 模型评估:在内部测试集和外部验证集上评估模型的性能。5) 可视化:使用GradCAM可视化模型关注的区域,以验证模型的可解释性。
关键创新:本研究的关键创新在于:1) 将BiomedCLIP应用于乳腺影像分析,探索了Foundation Model在医学影像领域的应用潜力。2) 提出了多模态训练策略,有效融合了不同成像模态的信息,提升了模型的泛化能力。3) 采用了加权对比学习,解决了类别不平衡问题,提高了模型对少数类别的识别能力。
关键设计:在多模态训练中,将不同模态的图像数据输入到BiomedCLIP中,提取各自的特征表示,然后将这些特征进行融合,用于BI-RADS分类。加权对比学习通过调整不同类别的样本在损失函数中的权重,来平衡类别之间的影响。损失函数采用对比损失,鼓励相同类别的样本在特征空间中更接近,不同类别的样本更远离。具体权重设置未知。
🖼️ 关键图片

📊 实验亮点
多模态模型在乳腺密度分类任务中取得了0.74的准确率,单模态模型准确率为0.73。多模态模型在不同BI-RADS类别中始终保持高于0.84的AUC值。在RSNA和EMBED数据集上的外部验证显示出强大的泛化能力,AUC范围为0.80-0.93。GradCAM可视化结果表明模型关注的区域与临床诊断相关。
🎯 应用场景
该研究成果可应用于乳腺癌早期筛查和诊断,辅助医生进行乳腺密度评估,提高诊断准确性和效率。通过推广到不同人群和成像模态,有望实现更广泛的临床应用,降低乳腺癌的漏诊率和误诊率。未来可扩展到其他乳腺疾病的诊断和风险预测。
📄 摘要(原文)
Foundation models hold promise for specialized medical imaging tasks, though their effectiveness in breast imaging remains underexplored. This study leverages BiomedCLIP as a foundation model to address challenges in model generalization. BiomedCLIP was adapted for automated BI-RADS breast density classification using multi-modality mammographic data (synthesized 2D images, digital mammography, and digital breast tomosynthesis). Using 96,995 images, we compared single-modality (s2D only) and multi-modality training approaches, addressing class imbalance through weighted contrastive learning. Both approaches achieved similar accuracy (multi-modality: 0.74, single-modality: 0.73), with the multi-modality model offering broader applicability across different imaging modalities and higher AUC values consistently above 0.84 across BI-RADS categories. External validation on the RSNA and EMBED datasets showed strong generalization capabilities (AUC range: 0.80-0.93). GradCAM visualizations confirmed consistent and clinically relevant attention patterns, highlighting the models interpretability and robustness. This research underscores the potential of foundation models for breast imaging applications, paving the way for future extensions for diagnostic tasks.