QAL: A Loss for Recall Precision Balance in 3D Reconstruction
作者: Pranay Meshram, Yash Turkar, Kartikeya Singh, Praveen Raj Masilamani, Charuvahan Adhivarahan, Karthik Dantu
分类: cs.CV, cs.RO
发布日期: 2025-11-21
备注: Accepted to WACV 2026. Camera-ready version to appear
💡 一句话要点
提出QAL以解决3D重建中的召回与精度平衡问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 3D重建 质量感知损失 召回与精度 机器人操作 深度学习
📋 核心要点
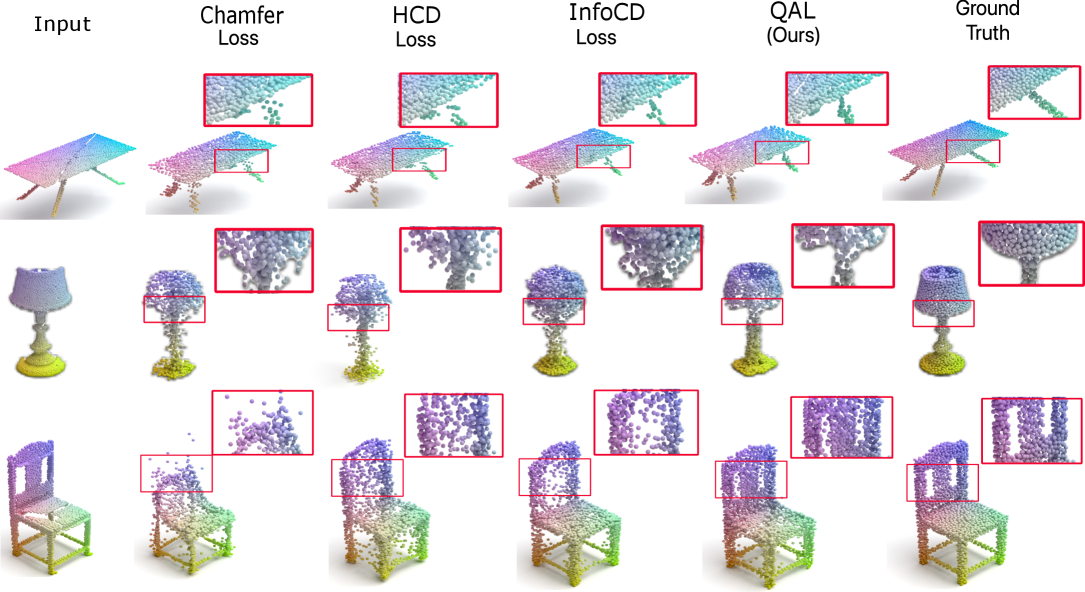
- 现有的3D重建方法主要依赖Chamfer距离和地球移动者距离,但无法有效平衡召回率和精度,导致对细结构的恢复不足。
- 本文提出了质量感知损失(QAL),通过结合覆盖加权最近邻项和未覆盖真实值吸引项,明确解耦召回和精度,提供可调节的损失函数。
- 实验结果表明,QAL在多个管道中实现了平均4.3分的覆盖率提升,相比于CD和最佳替代方案,显著改善了细结构和欠表示区域的恢复能力。
📝 摘要(中文)
体积学习是许多3D视觉任务(如完成、重建和网格生成)的基础,但现有的训练目标依赖于Chamfer距离(CD)或地球移动者距离(EMD),未能平衡召回率和精度。本文提出了质量感知损失(QAL),作为CD/EMD的替代方案,结合了覆盖加权最近邻项和未覆盖真实值吸引项,明确将召回和精度解耦为可调组件。在多种管道中,QAL实现了一致的覆盖率提升,平均比CD提高4.3分,比最佳替代方案提高2.8分。尽管提升幅度适中,但这些改进可靠地恢复了CD/EMD忽视的细结构和欠表示区域。大量消融实验确认了在超参数和输出分辨率上的稳定性能,而在PCN和ShapeNet上的全面重训练则展示了跨数据集和骨干网络的泛化能力。此外,QAL训练的完成在GraspNet评估中获得了更高的抓取分数,表明改进的覆盖率直接转化为更可靠的机器人操作。因此,QAL为稳健的3D视觉和安全关键的机器人管道提供了一个有原则、可解释且实用的目标。
🔬 方法详解
问题定义:本文旨在解决3D重建任务中召回率与精度之间的平衡问题。现有方法如Chamfer距离和地球移动者距离未能有效处理这一问题,导致对细小结构和欠表示区域的恢复不足。
核心思路:论文提出的质量感知损失(QAL)通过将召回和精度解耦为可调组件,结合覆盖加权最近邻项和未覆盖真实值吸引项,提供了一种新的损失函数设计思路。
技术框架:QAL的整体架构包括两个主要模块:覆盖加权最近邻项用于提升召回率,未覆盖真实值吸引项则用于增强精度。通过调节这两个组件的权重,可以灵活地优化模型性能。
关键创新:QAL的最大创新在于其明确的召回与精度解耦设计,使得模型在训练过程中能够针对不同的任务需求进行优化,克服了CD和EMD的局限性。
关键设计:在损失函数的设计上,QAL引入了覆盖加权和未覆盖真实值的吸引机制,允许研究者根据具体任务需求调整参数设置。此外,实验中对超参数和输出分辨率进行了广泛的消融实验,以确保模型的稳定性和泛化能力。
🖼️ 关键图片


📊 实验亮点
实验结果显示,QAL在多个管道中实现了平均4.3分的覆盖率提升,相比于Chamfer距离(CD)和最佳替代方案,分别提高了2.8分。这些提升显著改善了对细结构和欠表示区域的恢复能力,并在GraspNet评估中获得了更高的抓取分数,验证了其在机器人操作中的有效性。
🎯 应用场景
该研究的潜在应用领域包括机器人抓取、自动驾驶、虚拟现实等3D视觉相关任务。通过提高3D重建的精度和召回率,QAL能够在安全关键的机器人操作中提供更可靠的支持,推动相关技术的实际应用和发展。
📄 摘要(原文)
Volumetric learning underpins many 3D vision tasks such as completion, reconstruction, and mesh generation, yet training objectives still rely on Chamfer Distance (CD) or Earth Mover's Distance (EMD), which fail to balance recall and precision. We propose Quality-Aware Loss (QAL), a drop-in replacement for CD/EMD that combines a coverage-weighted nearest-neighbor term with an uncovered-ground-truth attraction term, explicitly decoupling recall and precision into tunable components. Across diverse pipelines, QAL achieves consistent coverage gains, improving by an average of +4.3 pts over CD and +2.8 pts over the best alternatives. Though modest in percentage, these improvements reliably recover thin structures and under-represented regions that CD/EMD overlook. Extensive ablations confirm stable performance across hyperparameters and across output resolutions, while full retraining on PCN and ShapeNet demonstrates generalization across datasets and backbones. Moreover, QAL-trained completions yield higher grasp scores under GraspNet evaluation, showing that improved coverage translates directly into more reliable robotic manipulation. QAL thus offers a principled, interpretable, and practical objective for robust 3D vision and safety-critical robotics pipelines