Importance-Weighted Non-IID Sampling for Flow Matching Models
作者: Xinshuang Liu, Runfa Blark Li, Shaoxiu Wei, Truong Nguyen
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-11-21
💡 一句话要点
提出重要性加权非独立同分布采样方法,提升Flow Matching模型输出期望的估计精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Flow Matching模型 非独立同分布采样 重要性加权 期望估计 多样性采样
📋 核心要点
- Flow Matching模型在有限采样预算下,对输出函数期望的估计面临高方差挑战,尤其是在重要但罕见事件中。
- 提出重要性加权非独立同分布采样框架,联合采样覆盖多样区域,并通过重要性权重保证无偏估计。
- 引入基于分数的正则化增强多样性,并学习残差速度场进行重要性加权,实验验证了样本质量和估计精度。
📝 摘要(中文)
Flow Matching模型能够有效表示复杂分布,但当采样预算有限时,估计其输出函数的期望仍然具有挑战性。独立采样通常会产生高方差的估计,尤其是在罕见但具有高影响结果的情况下。本文提出了一种重要性加权非独立同分布(non-IID)采样框架,该框架联合抽取多个样本以覆盖Flow分布中不同的、显著的区域,同时通过估计的重要性权重保持无偏估计。为了平衡多样性和质量,我们引入了基于分数的正则化方法来增强多样性机制,该方法使用分数函数(即对数概率的梯度)来确保样本在数据流形的高密度区域内被推开,从而减轻流形外的漂移。此外,我们还开发了第一种用于非独立同分布Flow样本的重要性加权方法,通过学习残差速度场来重现非独立同分布样本的边缘分布。实验表明,我们的方法能够生成多样、高质量的样本,并准确估计重要性权重和期望,从而提升Flow Matching模型输出的可靠表征。
🔬 方法详解
问题定义:Flow Matching模型在实际应用中,需要对模型输出的函数进行期望估计。然而,当采样预算有限时,传统的独立同分布(IID)采样方法往往难以覆盖到分布中的所有重要区域,尤其是一些概率较低但影响较大的区域,导致估计结果方差较高,精度不足。现有方法难以在有限的采样资源下,保证估计的准确性和可靠性。
核心思路:本文的核心思路是采用非独立同分布(non-IID)采样,即联合生成多个样本,使得这些样本能够尽可能覆盖Flow分布中的不同区域,从而提高采样的多样性。同时,为了保证估计的无偏性,需要对每个样本赋予一个重要性权重,该权重反映了该样本在整体分布中的代表性。通过这种方式,可以在有限的采样预算下,更准确地估计Flow Matching模型输出的期望。
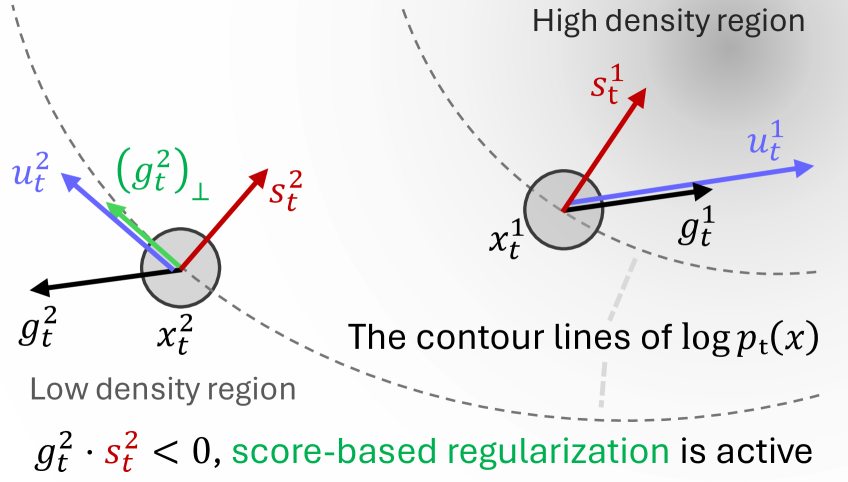
技术框架:该方法主要包含以下几个模块:1) 非独立同分布采样器:负责生成具有多样性的样本集合。2) 基于分数的正则化:用于约束采样过程,避免样本偏离数据流形。3) 重要性权重估计器:学习一个残差速度场,用于重构非独立同分布样本的边缘分布,从而估计每个样本的重要性权重。整体流程是,首先使用非独立同分布采样器生成样本,然后利用基于分数的正则化进行约束,最后使用重要性权重估计器计算每个样本的权重,用于后续的期望估计。
关键创新:该方法最重要的创新点在于提出了针对Flow Matching模型的非独立同分布采样框架,并设计了相应的采样器和重要性权重估计器。与传统的独立同分布采样相比,该方法能够更有效地利用有限的采样资源,提高估计的准确性和可靠性。此外,该方法还首次提出了针对非独立同分布Flow样本的重要性加权方法,解决了非独立同分布采样带来的权重估计问题。
关键设计:在非独立同分布采样器中,使用了基于分数的正则化方法,该方法利用Flow模型的score function(即对数概率的梯度)来推动样本在数据流形的高密度区域内分散,从而提高采样的多样性。重要性权重估计器通过学习一个残差速度场来实现,该速度场的目标是重构非独立同分布样本的边缘分布。损失函数的设计需要同时考虑重构误差和权重的稳定性。具体的网络结构和参数设置需要根据具体的Flow Matching模型和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够生成多样且高质量的样本,并且能够准确估计重要性权重和期望。与传统的独立同分布采样方法相比,该方法在估计精度上有显著提升,尤其是在采样预算有限的情况下。具体的性能数据和对比基线将在论文中详细展示。
🎯 应用场景
该研究成果可广泛应用于需要精确估计Flow Matching模型输出期望的领域,例如生成对抗网络(GAN)的评估、变分自编码器(VAE)的推断、以及强化学习中的策略评估等。通过提高估计的准确性和可靠性,可以更好地理解和利用Flow Matching模型,从而推动相关领域的发展。
📄 摘要(原文)
Flow-matching models effectively represent complex distributions, yet estimating expectations of functions of their outputs remains challenging under limited sampling budgets. Independent sampling often yields high-variance estimates, especially when rare but with high-impact outcomes dominate the expectation. We propose an importance-weighted non-IID sampling framework that jointly draws multiple samples to cover diverse, salient regions of a flow's distribution while maintaining unbiased estimation via estimated importance weights. To balance diversity and quality, we introduce a score-based regularization for the diversity mechanism, which uses the score function, i.e., the gradient of the log probability, to ensure samples are pushed apart within high-density regions of the data manifold, mitigating off-manifold drift. We further develop the first approach for importance weighting of non-IID flow samples by learning a residual velocity field that reproduces the marginal distribution of the non-IID samples. Empirically, our method produces diverse, high-quality samples and accurate estimates of both importance weights and expectations, advancing the reliable characterization of flow-matching model outputs. Our code will be publicly available on GitHub.