VisReason: A Large-Scale Dataset for Visual Chain-of-Thought Reasoning
作者: Lingxiao Li, Yifan Wang, Xinyan Gao, Chen Tang, Xiangyu Yue, Chenyu You
分类: cs.CV, cs.LG
发布日期: 2025-11-21
💡 一句话要点
VisReason:用于视觉链式思考推理的大规模数据集,提升多模态大语言模型的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉推理 链式思考 多模态学习 大型数据集 深度学习 语言模型 空间推理
📋 核心要点
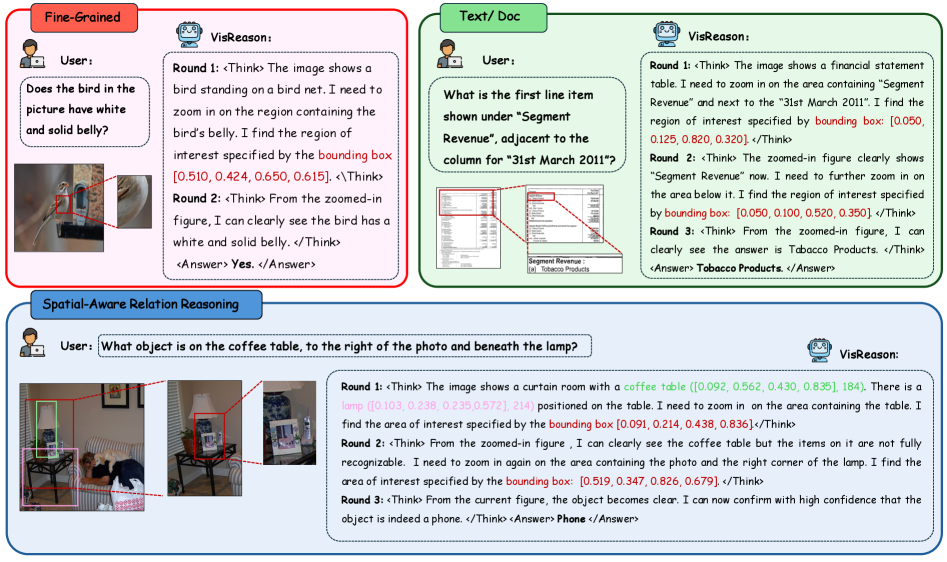
- 现有视觉链式思考数据集规模小、领域特定,缺乏人类逐步推理结构,限制了多模态大语言模型(MLLM)的视觉推理能力。
- VisReason数据集通过多轮、类人推理步骤,引导MLLM进行可解释的视觉推理,并利用深度信息进行3D空间定位。
- 在VisReason上微调Qwen2.5-VL模型,显著提升了视觉推理的准确性、可解释性和泛化能力,验证了数据集的有效性。
📝 摘要(中文)
链式思考(CoT)提示已被证明能有效激发大型语言模型(LLMs)的复杂推理能力。然而,由于缺乏能够捕捉视觉理解内在的丰富、空间定位推理的大规模数据集,其在多模态大型语言模型(MLLMs)中的潜力在很大程度上尚未开发。现有的视觉CoT资源通常规模较小、领域特定,或者缺乏类似人类的逐步结构,而这种结构对于组合式视觉推理至关重要。本文介绍了VisReason,一个旨在推进视觉链式思考推理的大规模数据集。VisReason包含489K个标注示例,涵盖四个不同的领域,每个领域都具有多轮、类似人类的理由,引导MLLM完成可解释的视觉推理步骤。在此基础上,我们策划了VisReason-Pro,一个由更强大的专家级GPT标注器生成的165K子集,通过深度信息标注丰富了详细的推理轨迹和3D空间定位。在VisReason和VisReason-Pro上微调最先进的Qwen2.5-VL模型,可以显著提高逐步视觉推理的准确性、可解释性和跨基准泛化能力。这些结果表明,VisReason使MLLM具备了更系统和更具泛化能力的推理能力。我们设想VisReason将成为培养类人视觉推理的基石,为下一代多模态智能铺平道路。
🔬 方法详解
问题定义:现有视觉链式思考数据集的规模和质量不足,无法充分训练多模态大语言模型进行复杂的视觉推理。这些数据集通常是领域特定的,缺乏足够的多样性,或者缺乏类似人类的逐步推理过程,导致模型难以泛化到新的场景。现有方法难以进行有效的空间推理,缺乏对3D信息的利用。
核心思路:论文的核心思路是构建一个大规模、高质量的视觉链式思考数据集VisReason,该数据集包含多轮、类人推理步骤,并涵盖多个不同的领域。通过在VisReason上训练多模态大语言模型,可以提高其视觉推理的准确性、可解释性和泛化能力。VisReason-Pro进一步利用专家级GPT标注器和深度信息,提升数据集的质量和空间推理能力。
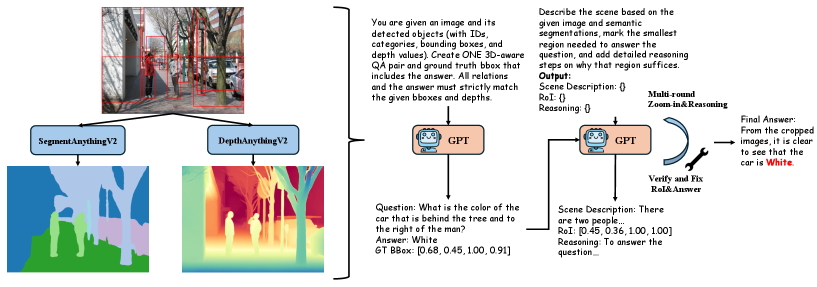
技术框架:VisReason数据集的构建流程包括以下几个主要阶段:1) 数据收集:从多个不同的领域收集视觉数据,确保数据的多样性。2) 人工标注:使用人工标注员对视觉数据进行标注,生成多轮、类人推理步骤。3) 数据验证:对标注数据进行验证,确保数据的质量。VisReason-Pro数据集的构建流程在VisReason的基础上增加了专家级GPT标注和深度信息标注。
关键创新:VisReason数据集的关键创新在于其大规模、高质量和多领域覆盖。与现有数据集相比,VisReason包含更多的标注示例,涵盖更广泛的领域,并提供更详细的推理步骤。VisReason-Pro通过专家级GPT标注和深度信息标注,进一步提升了数据集的质量和空间推理能力。
关键设计:VisReason数据集包含489K个标注示例,涵盖四个不同的领域。VisReason-Pro数据集包含165K个标注示例,由专家级GPT标注器生成,并包含深度信息标注。论文使用Qwen2.5-VL模型在VisReason和VisReason-Pro上进行微调,并使用标准的评估指标来评估模型的性能。具体参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
在VisReason和VisReason-Pro上微调Qwen2.5-VL模型,可以显著提高逐步视觉推理的准确性、可解释性和跨基准泛化能力。具体提升幅度在论文中有详细数据(未知)。实验结果表明,VisReason数据集能够有效提升多模态大语言模型的视觉推理能力。
🎯 应用场景
VisReason数据集可以应用于各种需要视觉推理的场景,例如机器人导航、智能助手、图像理解和视频分析。该数据集可以帮助开发更智能、更可靠的多模态系统,从而提高工作效率、改善用户体验,并推动人工智能技术的发展。
📄 摘要(原文)
Chain-of-Thought (CoT) prompting has proven remarkably effective for eliciting complex reasoning in large language models (LLMs). Yet, its potential in multimodal large language models (MLLMs) remains largely untapped, hindered by the absence of large-scale datasets that capture the rich, spatially grounded reasoning intrinsic to visual understanding. Existing visual-CoT resources are typically small, domain-specific, or lack the human-like stepwise structure necessary for compositional visual reasoning. In this paper, we introduce VisReason, a large-scale dataset designed to advance visual Chain-of-Thought reasoning. VisReason comprises 489K annotated examples spanning four diverse domains, each featuring multi-round, human-like rationales that guide MLLMs through interpretable visual reasoning steps. Building upon this, we curate VisReason-Pro, a 165K subset produced with a stronger expert-level GPT annotator, enriched with detailed reasoning traces and 3D spatial grounding via depth-informed annotations. Fine-tuning the state-of-the-art Qwen2.5-VL model on VisReason and VisReason-Pro yields substantial improvements in step-by-step visual reasoning accuracy, interpretability, and cross-benchmark generalization. These results demonstrate that VisReason equips MLLMs with more systematic and generalizable reasoning capabilities. We envision VisReason as a cornerstone for cultivating human-like visual reasoning, paving the way toward the next generation of multimodal intelligence.