Video-R4: Reinforcing Text-Rich Video Reasoning with Visual Rumination
作者: Yolo Y. Tang, Daiki Shimada, Hang Hua, Chao Huang, Jing Bi, Rogerio Feris, Chenliang Xu
分类: cs.CV
发布日期: 2025-11-21 (更新: 2025-11-26)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Video-R4,通过视觉沉思增强文本丰富视频推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频问答 视觉沉思 文本丰富视频 多模态推理 强化学习
📋 核心要点
- 现有视频问答模型在处理富含文本的视频时,由于单次感知和固定帧的限制,难以捕捉细粒度的文本信息,容易产生幻觉。
- Video-R4通过模仿人类的阅读习惯,迭代地选择帧、放大关键区域并重新编码像素,从而实现更精确的视觉沉思和推理。
- 该方法在M4-ViteVQA数据集上取得了SOTA结果,并成功泛化到多页文档QA、幻灯片QA和通用视频QA等任务,验证了其有效性。
📝 摘要(中文)
理解富含文本的视频需要阅读细小且短暂的文本线索,这通常需要重复检查。然而,大多数视频问答模型依赖于对固定帧的单次感知,导致幻觉和在细粒度证据上失败。受到人类暂停、放大和重读关键区域的启发,我们引入了Video-R4(通过视觉沉思增强文本丰富视频推理),这是一个视频推理LLM,它执行视觉沉思:迭代地选择帧,放大信息区域,重新编码检索到的像素,并更新其推理状态。我们构建了两个具有可执行沉思轨迹的数据集:用于监督学习的Video-R4-CoT-17k和用于强化学习的Video-R4-RL-30k。我们提出了一个多阶段沉思学习框架,逐步微调一个7B LLM,以通过SFT和基于GRPO的RL学习原子和混合视觉操作。Video-R4-7B在M4-ViteVQA上实现了最先进的结果,并进一步推广到多页文档QA、幻灯片QA和通用视频QA,表明迭代沉思是像素级多模态推理的有效范例。
🔬 方法详解
问题定义:论文旨在解决文本丰富的视频理解问题,特别是现有视频问答模型难以有效处理视频中细小、短暂的文本线索,导致推理错误的问题。现有方法通常采用单次感知和固定帧处理,无法像人类一样进行反复检查和聚焦关键区域。
核心思路:论文的核心思路是引入“视觉沉思”的概念,模仿人类阅读习惯,通过迭代地选择帧、放大信息区域、重新编码像素,并更新推理状态,从而更有效地提取和利用视频中的文本信息。这种迭代式的处理方式允许模型对关键信息进行反复检查,减少幻觉,提高推理准确性。
技术框架:Video-R4的技术框架包含以下几个主要模块:1) 帧选择模块:根据当前推理状态选择最有信息量的帧。2) 区域放大模块:对选定帧中的关键区域进行放大,提取更精细的像素信息。3) 像素重编码模块:将放大的像素信息重新编码为向量表示,用于更新推理状态。4) 推理状态更新模块:利用LLM,结合视觉信息和历史推理状态,生成最终答案。整个流程是一个迭代的过程,模型会根据需要重复执行上述步骤,直到获得满意的答案。
关键创新:该论文的关键创新在于提出了“视觉沉思”这一概念,并将其应用于视频问答任务中。与传统的单次感知方法不同,Video-R4通过迭代式的处理方式,允许模型对关键信息进行反复检查和聚焦,从而更有效地提取和利用视频中的文本信息。此外,论文还构建了两个包含可执行沉思轨迹的数据集,并提出了一个多阶段沉思学习框架。
关键设计:论文采用了一个多阶段的训练框架,包括:1) SFT (Supervised Fine-Tuning):使用Video-R4-CoT-17k数据集进行监督学习,使模型初步具备视觉沉思的能力。2) GRPO (Generative Reinforcement Preference Optimization) based RL:使用Video-R4-RL-30k数据集进行强化学习,进一步优化模型的沉思策略。模型使用7B LMM作为基础模型,并针对视觉沉思任务进行了微调。具体的损失函数和网络结构细节在论文中进行了详细描述,但未在摘要中明确提及。
🖼️ 关键图片

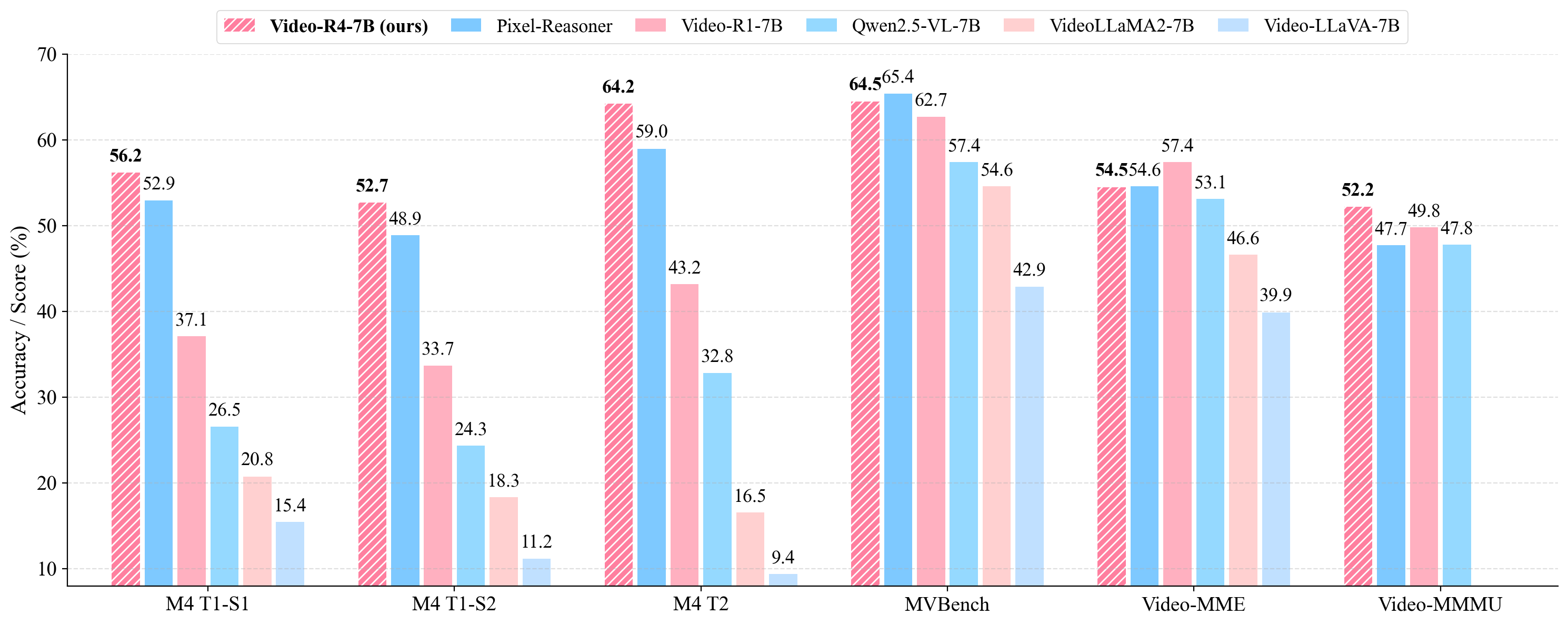
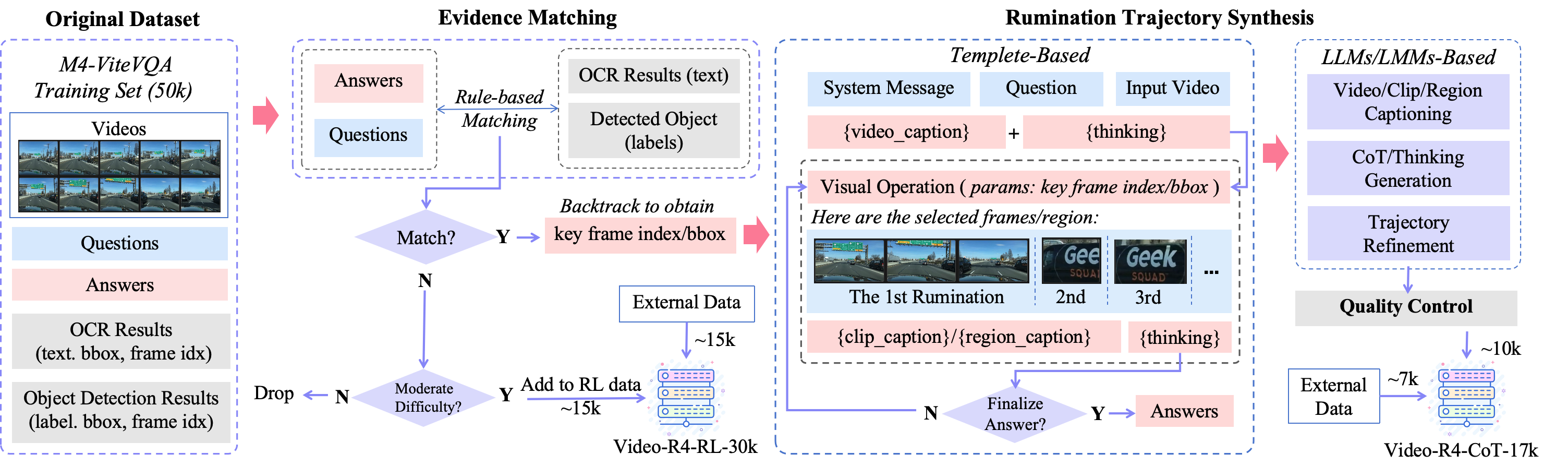
📊 实验亮点
Video-R4-7B在M4-ViteVQA数据集上取得了state-of-the-art的结果,证明了其在文本丰富视频理解方面的优越性。此外,该模型还成功泛化到多页文档QA、幻灯片QA和通用视频QA等任务,表明其具有良好的泛化能力和鲁棒性。具体的性能提升数据未在摘要中明确给出,需要在论文中查找。
🎯 应用场景
Video-R4具有广泛的应用前景,可应用于视频问答、文档理解、幻灯片内容提取等领域。该技术能够提升机器对复杂视觉信息的理解能力,尤其是在需要细致观察和反复检查的场景下,具有重要的实际价值。未来,该技术有望应用于智能教育、智能办公、智能客服等领域,提升人机交互的效率和质量。
📄 摘要(原文)
Understanding text-rich videos requires reading small, transient textual cues that often demand repeated inspection. Yet most video QA models rely on single-pass perception over fixed frames, leading to hallucinations and failures on fine-grained evidence. Inspired by how humans pause, zoom, and re-read critical regions, we introduce Video-R4 (Reinforcing Text-Rich Video Reasoning with Visual Rumination), a video reasoning LMM that performs visual rumination: iteratively selecting frames, zooming into informative regions, re-encoding retrieved pixels, and updating its reasoning state. We construct two datasets with executable rumination trajectories: Video-R4-CoT-17k for supervised practice and Video-R4-RL-30k for reinforcement learning. We propose a multi-stage rumination learning framework that progressively finetunes a 7B LMM to learn atomic and mixing visual operations via SFT and GRPO-based RL. Video-R4-7B achieves state-of-the-art results on M4-ViteVQA and further generalizes to multi-page document QA, slides QA, and generic video QA, demonstrating that iterative rumination is an effective paradigm for pixel-grounded multimodal reasoning. Project Page: https://yunlong10.github.io/Video-R4/