Counterfactual World Models via Digital Twin-conditioned Video Diffusion
作者: Yiqing Shen, Aiza Maksutova, Chenjia Li, Mathias Unberath
分类: cs.CV
发布日期: 2025-11-21
💡 一句话要点
提出CWMDT,通过数字孪生和视频扩散模型实现反事实世界建模
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 反事实世界模型 数字孪生 视频扩散模型 大型语言模型 物理AI 场景理解 前向模拟
📋 核心要点
- 现有世界模型主要基于实际观测进行预测,缺乏对反事实场景的推理能力,限制了其在复杂环境中的应用。
- CWMDT框架通过构建场景的数字孪生,利用大型语言模型进行推理,并结合视频扩散模型生成反事实视觉序列。
- 实验结果表明,CWMDT在反事实世界建模任务上取得了state-of-the-art的性能,验证了数字孪生表示的有效性。
📝 摘要(中文)
世界模型旨在预测给定控制信号下视觉观测的时间演变,从而使智能体能够通过前向模拟来推理环境。现有世界模型侧重于基于事实观测生成预测。然而,对于新兴应用,例如在不同条件下全面评估物理AI行为,世界模型回答反事实查询(例如“如果移除该对象会发生什么?”)的能力日益重要。本文形式化了反事实世界模型,它将干预作为显式输入,预测在对观察到的场景属性进行假设性修改下的时间序列。传统世界模型直接在纠缠的像素空间表示上操作,无法选择性地修改对象属性和关系。本文提出了CWMDT框架来克服这些限制,将标准视频扩散模型转变为有效的反事实世界模型。CWMDT首先构建观察到的场景的数字孪生,以显式编码对象及其关系,表示为结构化文本。其次,CWMDT应用大型语言模型来推理这些表示,并预测反事实干预如何随时间传播以改变观察到的场景。第三,CWMDT使用修改后的表示来调节视频扩散模型,以生成反事实视觉序列。在两个基准上的评估表明,CWMDT方法实现了最先进的性能,表明视频的替代表示(例如本文考虑的数字孪生)为基于视频前向模拟的世界模型提供了强大的控制信号。
🔬 方法详解
问题定义:现有世界模型主要关注基于实际观测的前向模拟,无法回答“如果...会怎样?”这类反事实问题。它们直接在像素空间进行操作,难以对特定对象或属性进行干预,限制了其在需要评估不同场景或策略的物理AI应用中的潜力。
核心思路:本文的核心思路是将视频场景解耦为结构化的数字孪生表示,利用大型语言模型进行推理,并使用视频扩散模型生成视觉序列。通过显式地表示对象及其关系,可以对特定属性进行干预,并预测干预后的场景演变。这种解耦表示和推理过程使得模型能够更好地理解和模拟反事实场景。
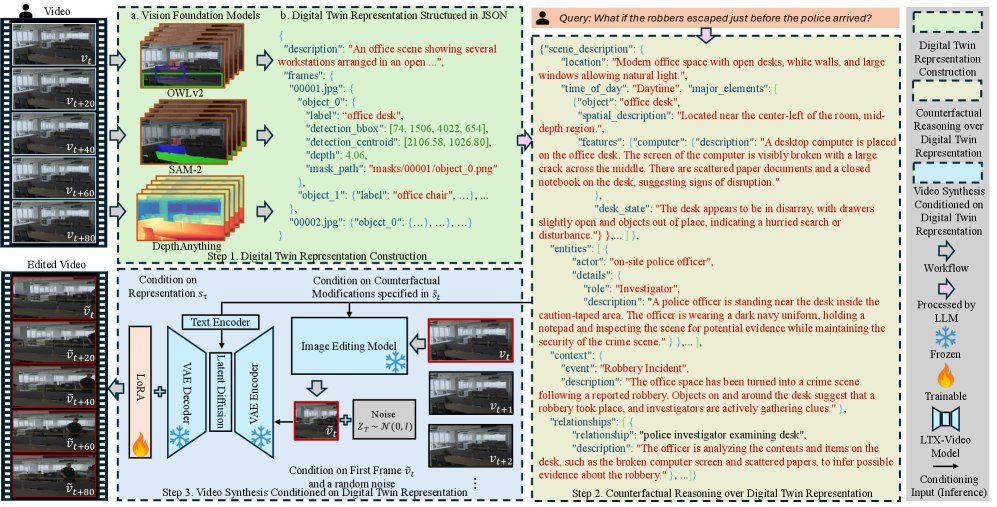
技术框架:CWMDT框架包含三个主要模块:1) 数字孪生构建:将观察到的场景转换为结构化的文本表示,显式编码对象及其关系。2) 反事实推理:使用大型语言模型对数字孪生表示进行推理,预测干预如何影响场景演变,生成修改后的数字孪生表示。3) 视频扩散生成:使用修改后的数字孪生表示作为条件,驱动视频扩散模型生成反事实视觉序列。
关键创新:CWMDT的关键创新在于将数字孪生表示、大型语言模型和视频扩散模型结合起来,构建了一个能够进行反事实推理的世界模型。与直接在像素空间进行操作的传统世界模型不同,CWMDT通过解耦表示和推理过程,实现了对特定场景属性的干预和控制。
关键设计:数字孪生表示的具体形式(例如,使用哪些属性来描述对象及其关系)以及大型语言模型的选择和训练方式是关键的设计因素。此外,视频扩散模型的条件输入方式(如何将修改后的数字孪生表示融入扩散过程)也需要仔细设计,以确保生成高质量的反事实视觉序列。
🖼️ 关键图片


📊 实验亮点
CWMDT在两个基准测试上取得了state-of-the-art的性能,证明了其在反事实世界建模方面的有效性。具体而言,该方法能够生成高质量的反事实视觉序列,并准确预测干预对场景演变的影响。实验结果表明,数字孪生表示为视频前向模拟提供了强大的控制信号,优于传统的像素空间表示。
🎯 应用场景
该研究成果可应用于物理AI系统的安全性和鲁棒性评估,例如自动驾驶汽车在不同交通状况下的行为预测,机器人操作在不同环境下的性能评估。通过模拟反事实场景,可以更好地理解系统的潜在风险,并优化其设计和控制策略。此外,该方法还可用于游戏AI和虚拟现实等领域,创造更具交互性和真实感的虚拟环境。
📄 摘要(原文)
World models learn to predict the temporal evolution of visual observations given a control signal, potentially enabling agents to reason about environments through forward simulation. Because of the focus on forward simulation, current world models generate predictions based on factual observations. For many emerging applications, such as comprehensive evaluations of physical AI behavior under varying conditions, the ability of world models to answer counterfactual queries, such as "what would happen if this object was removed?", is of increasing importance. We formalize counterfactual world models that additionally take interventions as explicit inputs, predicting temporal sequences under hypothetical modifications to observed scene properties. Traditional world models operate directly on entangled pixel-space representations where object properties and relationships cannot be selectively modified. This modeling choice prevents targeted interventions on specific scene properties. We introduce CWMDT, a framework to overcome those limitations, turning standard video diffusion models into effective counterfactual world models. First, CWMDT constructs digital twins of observed scenes to explicitly encode objects and their relationships, represented as structured text. Second, CWMDT applies large language models to reason over these representations and predict how a counterfactual intervention propagates through time to alter the observed scene. Third, CWMDT conditions a video diffusion model with the modified representation to generate counterfactual visual sequences. Evaluations on two benchmarks show that the CWMDT approach achieves state-of-the-art performance, suggesting that alternative representations of videos, such as the digital twins considered here, offer powerful control signals for video forward simulation-based world models.