MCMoE: Completing Missing Modalities with Mixture of Experts for Incomplete Multimodal Action Quality Assessment
作者: Huangbiao Xu, Huanqi Wu, Xiao Ke, Junyi Wu, Rui Xu, Jinglin Xu
分类: cs.CV
发布日期: 2025-11-21 (更新: 2025-12-08)
备注: AAAI 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出MCMoE模型,通过专家混合补全缺失模态,提升不完整多模态动作质量评估性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动作质量评估 多模态学习 模态补全 专家混合 不完整数据
📋 核心要点
- 现有AQA模型在推理阶段面临部分模态缺失的挑战,导致跨模态交互中断和性能大幅下降。
- MCMoE通过自适应门控模态生成器重建缺失模态,并利用专家混合提取跨模态联合表示。
- 实验表明,MCMoE在完整和不完整多模态学习上均达到SOTA,显著提升了AQA性能。
📝 摘要(中文)
多模态动作质量评估(AQA)近年来成为一种有前景的范例。它利用跨共享上下文线索的互补信息,增强了对高度相似动作序列中细微类内变化的区分性评估。然而,在现实中,部分模态在推理阶段经常不可用。任何模态的缺失通常会使现有的多模态模型无法运行,并由于跨模态交互的中断而引发灾难性的性能下降。为了解决这个问题,我们提出了一种新的基于专家混合的缺失补全框架(MCMoE),它在单阶段训练中统一了单模态和联合表示学习。具体来说,我们提出了一个自适应门控模态生成器,它动态地融合可用信息来重建缺失的模态。然后,我们设计模态专家来学习单模态知识,并动态地混合所有专家的知识来提取跨模态联合表示。通过专家混合,缺失的模态得到进一步的细化和补充。最后,在训练阶段,我们挖掘完整的多模态特征和单模态专家知识,以指导模态生成和基于生成的联合表示提取。大量的实验表明,我们的MCMoE在三个公共AQA基准测试中,在完整和不完整的多模态学习方面都取得了最先进的结果。
🔬 方法详解
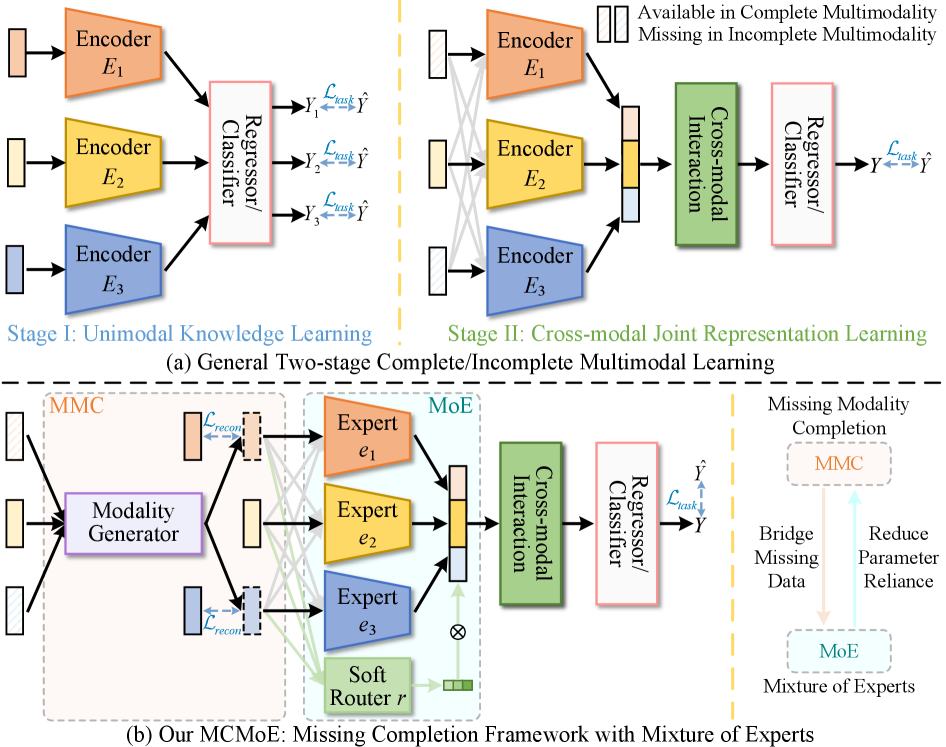
问题定义:论文旨在解决多模态动作质量评估中,由于部分模态数据缺失导致现有模型性能急剧下降的问题。现有方法依赖于所有模态的完整性,无法有效处理实际应用中常见的模态缺失情况,导致模型失效或性能显著降低。
核心思路:论文的核心思路是通过学习模态之间的关系,利用已有的模态信息来重建缺失的模态,从而保证模型在不完整数据下的有效性。同时,利用专家混合机制,融合不同模态的知识,提升模型的鲁棒性和泛化能力。
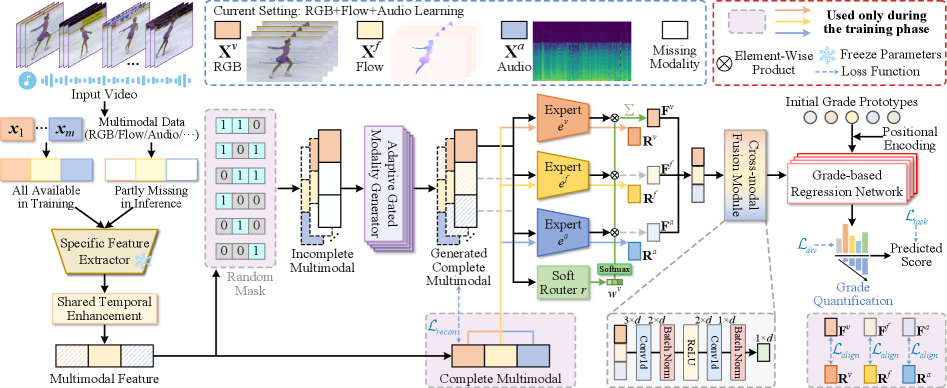
技术框架:MCMoE框架主要包含三个核心模块:自适应门控模态生成器、模态专家和专家混合模块。首先,自适应门控模态生成器利用可用的模态信息,通过门控机制动态地融合这些信息,生成缺失的模态。然后,每个模态对应一个模态专家,负责学习该模态的特定知识。最后,专家混合模块将所有模态专家的知识进行融合,提取跨模态的联合表示,用于最终的动作质量评估。
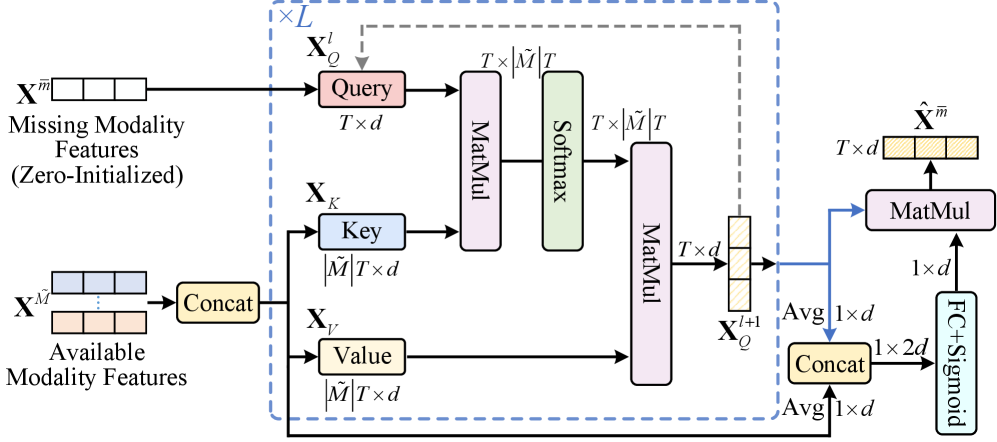
关键创新:论文的关键创新在于提出了一个统一的框架,能够在单阶段训练中同时学习单模态和联合表示,并有效地处理模态缺失问题。自适应门控模态生成器能够根据可用的模态信息动态地调整生成策略,提高了模态重建的准确性。专家混合机制能够充分利用不同模态的知识,提升模型的鲁棒性和泛化能力。
关键设计:自适应门控模态生成器使用注意力机制来动态地融合可用的模态信息,门控机制控制每个模态对生成结果的贡献程度。模态专家可以使用各种神经网络结构,如Transformer或CNN,来学习模态的特定知识。专家混合模块使用可学习的权重来融合不同专家的输出,这些权重可以根据输入数据的特征进行调整。损失函数包括模态重建损失、动作质量评估损失和专家混合损失,用于指导模型的训练。
🖼️ 关键图片
📊 实验亮点
MCMoE在三个公开的AQA基准数据集上取得了SOTA结果。在不完整模态设置下,MCMoE相比于现有方法有显著的性能提升,证明了其在处理模态缺失问题上的有效性。具体性能数据需要在论文中查找,但摘要明确说明了其优越性。
🎯 应用场景
该研究成果可应用于视频监控、体育分析、康复训练等领域。在这些场景中,由于传感器故障、遮挡或其他原因,经常会出现模态数据缺失的情况。MCMoE模型能够有效处理这些不完整数据,提高动作质量评估的准确性和可靠性,具有重要的实际应用价值。
📄 摘要(原文)
Multimodal Action Quality Assessment (AQA) has recently emerged as a promising paradigm. By leveraging complementary information across shared contextual cues, it enhances the discriminative evaluation of subtle intra-class variations in highly similar action sequences. However, partial modalities are frequently unavailable at the inference stage in reality. The absence of any modality often renders existing multimodal models inoperable. Furthermore, it triggers catastrophic performance degradation due to interruptions in cross-modal interactions. To address this issue, we propose a novel Missing Completion Framework with Mixture of Experts (MCMoE) that unifies unimodal and joint representation learning in single-stage training. Specifically, we propose an adaptive gated modality generator that dynamically fuses available information to reconstruct missing modalities. We then design modality experts to learn unimodal knowledge and dynamically mix the knowledge of all experts to extract cross-modal joint representations. With a mixture of experts, missing modalities are further refined and complemented. Finally, in the training phase, we mine the complete multimodal features and unimodal expert knowledge to guide modality generation and generation-based joint representation extraction. Extensive experiments demonstrate that our MCMoE achieves state-of-the-art results in both complete and incomplete multimodal learning on three public AQA benchmarks. Code is available at https://github.com/XuHuangbiao/MCMoE.