MolSight: Optical Chemical Structure Recognition with SMILES Pretraining, Multi-Granularity Learning and Reinforcement Learning
作者: Wenrui Zhang, Xinggang Wang, Bin Feng, Wenyu Liu
分类: cs.CV
发布日期: 2025-11-21
💡 一句话要点
MolSight:结合SMILES预训练、多粒度学习和强化学习的光学化学结构识别方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 光学化学结构识别 OCSR SMILES预训练 多粒度学习 强化学习 立体化学 化学信息学
📋 核心要点
- 现有OCSR系统难以准确识别立体化学信息,因为立体异构体的视觉差异细微,如键的类型和空间排列。
- MolSight采用三阶段训练:预训练提升感知,多粒度微调利用辅助任务,强化学习优化立体结构识别。
- 实验表明,即使参数量较小,MolSight也能在多个数据集上达到最先进的(立体)化学光学结构识别性能。
📝 摘要(中文)
光学化学结构识别(OCSR)在现代化学信息学中起着关键作用,它能够自动将科学文献、专利和教育材料中的化学结构图像转换为机器可读的分子表示。这种能力对于大规模化学数据挖掘、药物发现流程以及相关领域的大型语言模型(LLM)应用至关重要。然而,现有的OCSR系统在准确识别立体化学信息方面面临着重大挑战,这是因为立体异构体之间的视觉线索非常微妙,例如楔形和虚线键、环状构象和空间排列。为了应对这些挑战,我们提出了MolSight,这是一个用于OCSR的综合学习框架,它采用三阶段训练范式。在第一阶段,我们在大规模但噪声的数据集上进行预训练,使模型具备化学结构图像的基本感知能力。在第二阶段,我们使用具有更丰富监督信号的数据集执行多粒度微调,系统地探索辅助任务(特别是化学键分类和原子定位)如何促进分子式识别。最后,我们采用强化学习进行后训练优化,并引入了一种新的立体化学结构数据集。值得注意的是,我们发现即使MolSight的参数规模相对较小,Group Relative Policy Optimization (GRPO)算法也可以进一步提高模型在立体分子上的性能。通过在各种数据集上进行的大量实验,我们的结果表明MolSight在(立体)化学光学结构识别方面实现了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决光学化学结构识别(OCSR)中立体化学信息识别不准确的问题。现有方法难以区分细微的立体异构体差异,例如楔形键、虚线键、环状构象和空间排列,导致识别精度不高。
核心思路:论文的核心思路是采用一个三阶段的训练框架,结合预训练、多粒度学习和强化学习,逐步提升模型对化学结构图像的感知和理解能力,尤其是在立体化学信息方面。通过预训练获得基础感知能力,多粒度学习引入辅助任务提升识别精度,强化学习优化立体结构识别。
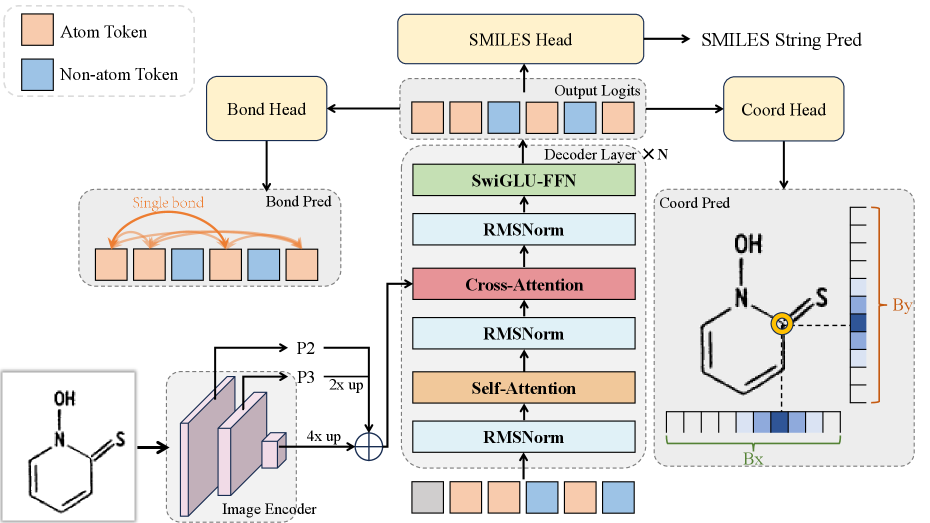
技术框架:MolSight的整体框架包含三个阶段:1) 预训练阶段:在大规模噪声数据集上进行预训练,使模型学习化学结构图像的基本特征。2) 多粒度微调阶段:使用具有更丰富监督信号的数据集,通过化学键分类和原子定位等辅助任务,提升分子式识别的准确性。3) 强化学习优化阶段:使用强化学习算法(GRPO)对模型进行后训练优化,特别是在立体化学结构数据集上进行训练,以提高对立体异构体的识别能力。
关键创新:论文的关键创新在于结合了SMILES预训练、多粒度学习和强化学习,构建了一个端到端的OCSR框架。多粒度学习通过引入辅助任务,有效地利用了数据集中的信息,提升了模型的识别精度。强化学习的应用则进一步优化了模型在立体化学结构识别方面的性能。
关键设计:在预训练阶段,使用了大规模的SMILES数据集进行训练,使模型学习化学结构的表示。在多粒度微调阶段,使用了化学键分类和原子定位作为辅助任务,并设计了相应的损失函数。在强化学习阶段,使用了Group Relative Policy Optimization (GRPO)算法,并构建了专门的立体化学结构数据集。
🖼️ 关键图片


📊 实验亮点
MolSight在多个OCSR数据集上取得了state-of-the-art的性能。特别是在立体化学结构识别方面,通过引入强化学习算法GRPO,显著提升了模型对立体异构体的识别精度。即使模型参数量相对较小,也能达到优异的性能,表明了该方法的有效性。
🎯 应用场景
MolSight在化学信息学、药物发现和材料科学等领域具有广泛的应用前景。它可以自动将科学文献、专利和教育材料中的化学结构图像转换为机器可读的分子表示,从而加速化学数据的挖掘和分析。此外,MolSight还可以应用于药物设计和筛选,以及新材料的开发。
📄 摘要(原文)
Optical Chemical Structure Recognition (OCSR) plays a pivotal role in modern chemical informatics, enabling the automated conversion of chemical structure images from scientific literature, patents, and educational materials into machine-readable molecular representations. This capability is essential for large-scale chemical data mining, drug discovery pipelines, and Large Language Model (LLM) applications in related domains. However, existing OCSR systems face significant challenges in accurately recognizing stereochemical information due to the subtle visual cues that distinguish stereoisomers, such as wedge and dash bonds, ring conformations, and spatial arrangements. To address these challenges, we propose MolSight, a comprehensive learning framework for OCSR that employs a three-stage training paradigm. In the first stage, we conduct pre-training on large-scale but noisy datasets to endow the model with fundamental perception capabilities for chemical structure images. In the second stage, we perform multi-granularity fine-tuning using datasets with richer supervisory signals, systematically exploring how auxiliary tasks-specifically chemical bond classification and atom localization-contribute to molecular formula recognition. Finally, we employ reinforcement learning for post-training optimization and introduce a novel stereochemical structure dataset. Remarkably, we find that even with MolSight's relatively compact parameter size, the Group Relative Policy Optimization (GRPO) algorithm can further enhance the model's performance on stereomolecular. Through extensive experiments across diverse datasets, our results demonstrate that MolSight achieves state-of-the-art performance in (stereo)chemical optical structure recognition.