OmniPT: Unleashing the Potential of Large Vision Language Models for Pedestrian Tracking and Understanding
作者: Teng Fu, Mengyang Zhao, Ke Niu, Kaixin Peng, Bin Li
分类: cs.CV, cs.AI
发布日期: 2025-11-21
备注: AAAI 2026
💡 一句话要点
OmniPT:利用大型视觉语言模型进行行人跟踪与语义理解的统一框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 行人跟踪 大型视觉语言模型 多目标跟踪 语义理解 强化学习
📋 核心要点
- 现有LVLMs在实例级任务中表现不足,且缺乏对行人跟踪中高级语义理解的有效利用。
- OmniPT将行人跟踪任务转化为LVLMs可处理的形式,并使模型输出格式化的答案。
- 通过RL-Mid Training-SFT-RL训练流程,OmniPT在跟踪基准测试中表现优于现有方法。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在图像级别的任务(如VQA和图像描述)中表现出色。然而,在实例级别的任务(如视觉定位和目标检测)中,LVLMs的性能与之前的专家模型相比仍存在差距。同时,虽然行人跟踪是一个经典任务,但结合目标跟踪和自然语言的新主题不断涌现,例如Referring MOT、Cross-view Referring MOT和Semantic MOT。这些任务强调模型应在高级语义层面理解被跟踪对象,这正是LVLMs的优势所在。本文提出了一个新的统一行人跟踪框架OmniPT,它可以交互式地进行跟踪、基于参考的跟踪以及生成被跟踪对象的语义理解。我们解决了两个问题:如何将跟踪任务建模成基础模型可以执行的任务,以及如何使模型输出格式化的答案。为此,我们实现了一个包含RL-Mid Training-SFT-RL的训练阶段。基于LVLM的预训练权重,我们首先执行一个简单的RL阶段,使模型能够输出固定的、可监督的边界框格式。随后,我们使用大量的行人相关数据集进行中间训练阶段。最后,我们在几个行人跟踪数据集上进行监督微调,然后进行另一个RL阶段,以提高模型的跟踪性能并增强其遵循指令的能力。我们在跟踪基准上进行了实验,实验结果表明,所提出的方法可以比以前的方法表现更好。
🔬 方法详解
问题定义:论文旨在解决行人跟踪任务中,大型视觉语言模型(LVLMs)在实例级别任务上的性能瓶颈,以及如何有效利用LVLMs进行高级语义理解的问题。现有方法难以充分利用LVLMs的语义理解能力,并且在处理Referring MOT等需要语义信息的任务时表现不佳。
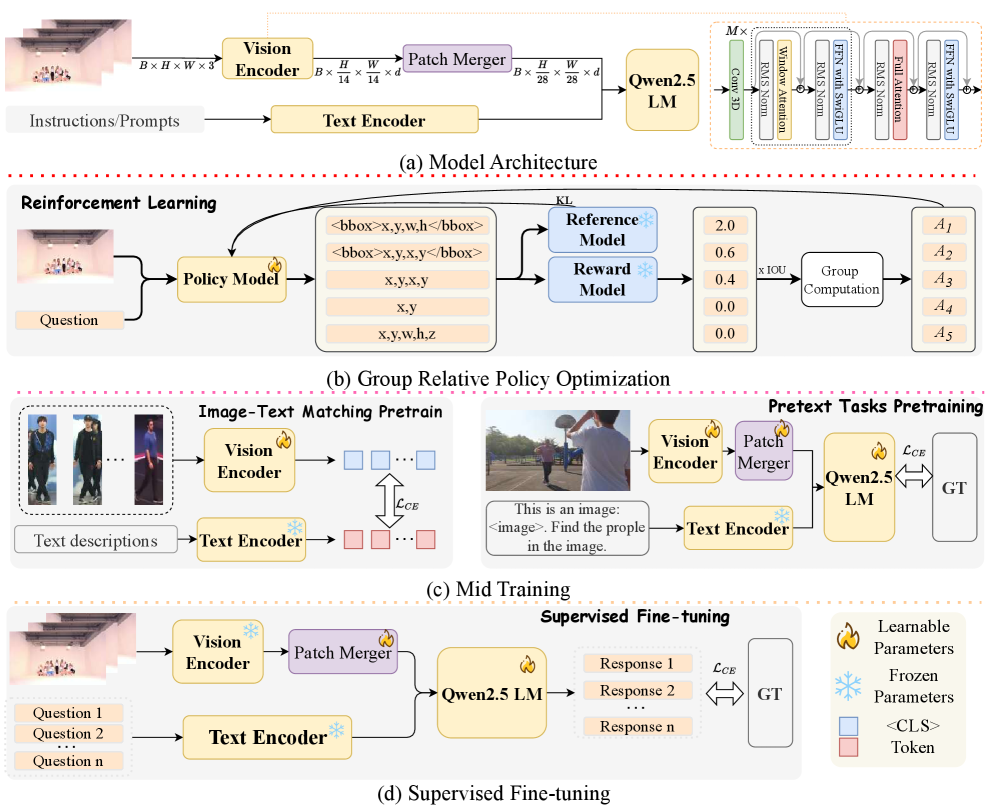
核心思路:论文的核心思路是将行人跟踪任务转化为LVLMs能够理解和执行的形式,并设计一个训练流程,使模型能够输出格式化的边界框和语义信息。通过强化学习(RL)引导模型输出边界框,并通过中间训练(Mid Training)和监督微调(SFT)提升模型在行人跟踪任务上的性能。
技术框架:OmniPT的整体框架包含以下几个阶段:1) 基于预训练LVLM的初始化;2) 使用强化学习(RL)使模型输出边界框格式;3) 使用大量行人相关数据集进行中间训练(Mid Training);4) 在行人跟踪数据集上进行监督微调(SFT);5) 再次进行强化学习(RL)以提升跟踪性能和指令遵循能力。整个流程旨在逐步提升模型在行人跟踪任务上的性能和语义理解能力。
关键创新:论文的关键创新在于提出了一个统一的行人跟踪框架OmniPT,该框架能够利用LVLMs进行跟踪、基于参考的跟踪以及生成被跟踪对象的语义理解。此外,RL-Mid Training-SFT-RL的训练流程也是一个创新点,它能够有效地提升模型在行人跟踪任务上的性能和指令遵循能力。与现有方法相比,OmniPT能够更好地利用LVLMs的语义理解能力,并在Referring MOT等任务上表现更佳。
关键设计:论文中关键的设计包括:1) 使用强化学习来引导模型输出边界框格式,这使得模型能够输出可监督的答案;2) 中间训练阶段使用大量的行人相关数据集,这有助于模型学习到更多的行人相关知识;3) 监督微调阶段使用行人跟踪数据集,这使得模型能够更好地适应行人跟踪任务;4) 再次进行强化学习,以进一步提升模型的跟踪性能和指令遵循能力。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,OmniPT在行人跟踪基准测试中表现优于现有方法。具体的性能数据和提升幅度在摘要中有所提及,但未给出具体数值。论文强调OmniPT在跟踪性能和语义理解能力上均有提升,但具体提升幅度未知。
🎯 应用场景
OmniPT具有广泛的应用前景,例如智能监控、自动驾驶、机器人导航等领域。该框架能够提升行人跟踪的准确性和鲁棒性,并能够提供被跟踪对象的语义信息,从而为下游任务提供更丰富的信息。未来,OmniPT有望应用于更复杂的场景,例如人群行为分析、异常事件检测等。
📄 摘要(原文)
LVLMs have been shown to perform excellently in image-level tasks such as VQA and caption. However, in many instance-level tasks, such as visual grounding and object detection, LVLMs still show performance gaps compared to previous expert models. Meanwhile, although pedestrian tracking is a classical task, there have been a number of new topics in combining object tracking and natural language, such as Referring MOT, Cross-view Referring MOT, and Semantic MOT. These tasks emphasize that models should understand the tracked object at an advanced semantic level, which is exactly where LVLMs excel. In this paper, we propose a new unified Pedestrian Tracking framework, namely OmniPT, which can track, track based on reference and generate semantic understanding of tracked objects interactively. We address two issues: how to model the tracking task into a task that foundation models can perform, and how to make the model output formatted answers. To this end, we implement a training phase consisting of RL-Mid Training-SFT-RL. Based on the pre-trained weights of the LVLM, we first perform a simple RL phase to enable the model to output fixed and supervisable bounding box format. Subsequently, we conduct a mid-training phase using a large number of pedestrian-related datasets. Finally, we perform supervised fine-tuning on several pedestrian tracking datasets, and then carry out another RL phase to improve the model's tracking performance and enhance its ability to follow instructions. We conduct experiments on tracking benchmarks and the experimental results demonstrate that the proposed method can perform better than the previous methods.