DReX: Pure Vision Fusion of Self-Supervised and Convolutional Representations for Image Complexity Prediction
作者: Jonathan Skaza, Parsa Madinei, Ziqi Wen, Miguel Eckstein
分类: cs.CV
发布日期: 2025-11-21
备注: 8 pages
💡 一句话要点
DReX:融合自监督和卷积表征的纯视觉图像复杂度预测模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像复杂度预测 自监督学习 视觉Transformer 卷积神经网络 特征融合 注意力机制 纯视觉模型
📋 核心要点
- 现有图像复杂度预测方法依赖多模态模型,需要图像文本数据,但语言信息是否必要仍不明确。
- DReX模型融合自监督DINOv3和卷积ResNet-50的视觉表征,通过注意力机制学习图像复杂度。
- DReX在IC9600上达到SOTA,Pearson r=0.9581,参数量更少,且在多个数据集上泛化性良好。
📝 摘要(中文)
图像复杂度预测是计算机视觉中的一个基本问题,在图像压缩、检索和分类等领域有应用。理解人类如何感知图像的复杂性也是认知科学中一个长期存在的问题。最近的方法利用了结合视觉和语言表征的多模态模型,但语言信息对于此任务是否必要尚不清楚。我们提出了DReX(DINO-ResNet Fusion),一个纯视觉模型,它通过可学习的注意力机制融合自监督和卷积表征来预测图像复杂度。我们的架构将ResNet-50的多尺度分层特征与DINOv3 ViT-S/16的语义丰富的表征相结合,使模型能够捕获低级纹理模式和高级语义结构。DReX在IC9600基准测试中取得了最先进的性能(Pearson r = 0.9581),超过了以前的方法,包括那些在多模态图像-文本数据上训练的方法,同时使用的可学习参数减少了约21.5倍。此外,DReX在多个数据集和指标上具有强大的泛化能力,在Pearson和Spearman相关性、均方根误差(RMSE)和平均绝对误差(MAE)方面取得了优异的结果。消融和注意力分析证实,DReX利用了来自两个骨干网络的互补线索,其中DINOv3的[CLS] token增强了对视觉复杂性的敏感性。我们的研究结果表明,仅视觉特征就足以进行与人类对齐的复杂度预测,并且当正确融合时,自监督Transformer和监督深度卷积神经网络为此任务提供了互补和协同的优势。
🔬 方法详解
问题定义:论文旨在解决图像复杂度预测问题,即预测人类对图像复杂度的感知程度。现有方法,特别是基于多模态(图像-文本)的模型,计算成本高昂,且依赖于语言信息,而语言信息对于纯视觉复杂度预测是否必要尚不明确。
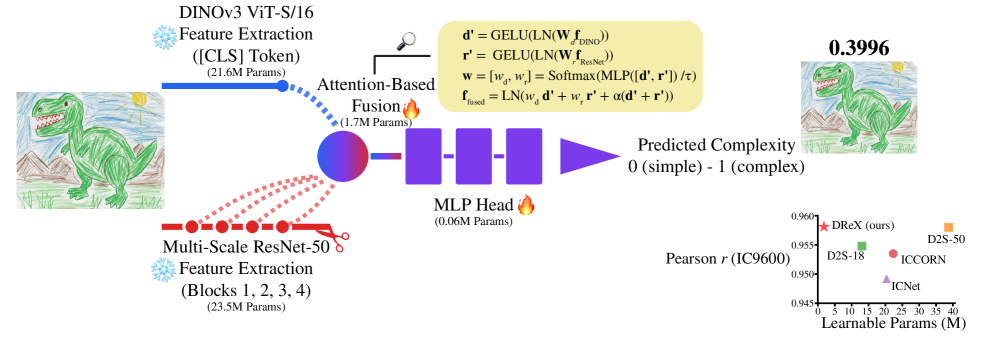
核心思路:论文的核心思路是仅使用视觉信息,通过融合自监督学习得到的视觉Transformer (DINOv3) 和卷积神经网络 (ResNet-50) 的特征,来更准确地预测图像复杂度。这种融合旨在结合两种模型的优势:DINOv3擅长捕捉图像的全局语义信息,而ResNet-50擅长捕捉局部纹理细节。
技术框架:DReX模型的整体架构包括以下几个主要模块:1) ResNet-50:提取图像的多尺度卷积特征。2) DINOv3 ViT-S/16:提取图像的全局语义表征,特别是[CLS] token。3) 注意力融合模块:使用可学习的注意力机制,将ResNet-50提取的多尺度特征和DINOv3的[CLS] token进行融合。4) 预测头:使用融合后的特征预测图像的复杂度得分。
关键创新:最重要的技术创新点在于纯视觉的特征融合方式,即通过可学习的注意力机制,有效地融合了自监督学习得到的视觉Transformer (DINOv3) 和卷积神经网络 (ResNet-50) 的特征。这种融合方式使得模型能够同时利用全局语义信息和局部纹理细节,从而更准确地预测图像复杂度。与现有方法相比,DReX不需要语言信息,并且参数量更少。
关键设计:DReX的关键设计包括:1) 使用DINOv3 ViT-S/16作为自监督学习的骨干网络,提取图像的全局语义表征。2) 使用ResNet-50作为卷积神经网络的骨干网络,提取图像的多尺度卷积特征。3) 使用可学习的注意力机制,将ResNet-50提取的多尺度特征和DINOv3的[CLS] token进行融合。4) 使用均方误差(MSE)作为损失函数,优化模型参数。
🖼️ 关键图片

📊 实验亮点
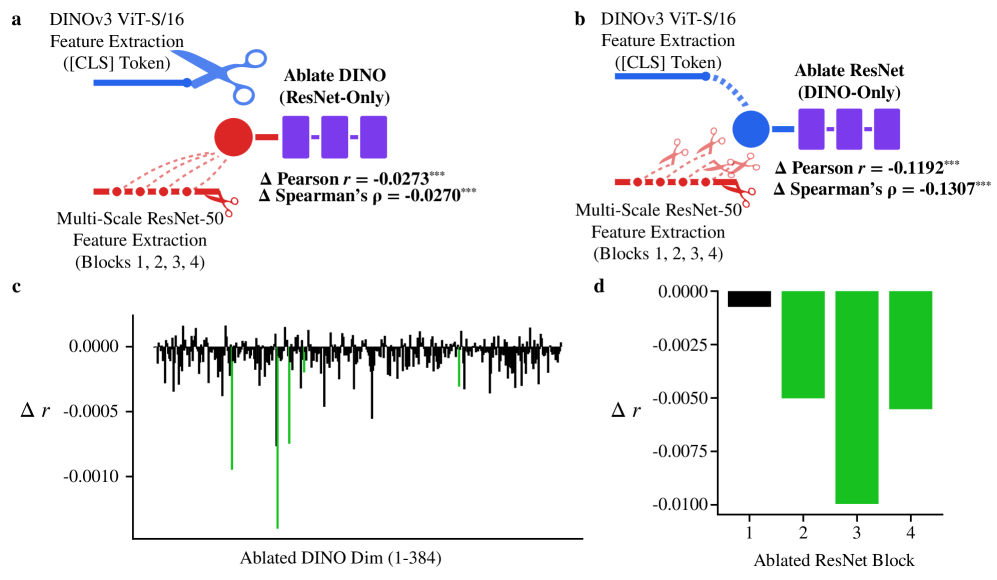
DReX在IC9600数据集上取得了最先进的性能,Pearson相关系数达到0.9581,超过了以往的多模态模型。同时,DReX的参数量仅为以往模型的约1/21.5。此外,DReX在多个数据集和指标(Pearson/Spearman相关性,RMSE,MAE)上均表现出强大的泛化能力。
🎯 应用场景
该研究成果可应用于图像压缩,根据图像复杂度自适应调整压缩率;图像检索,根据用户指定的复杂度进行图像搜索;图像分类,作为图像特征的一部分提升分类性能;以及认知科学研究,帮助理解人类视觉感知机制。未来可扩展到视频复杂度预测,应用于视频编码和传输等领域。
📄 摘要(原文)
Visual complexity prediction is a fundamental problem in computer vision with applications in image compression, retrieval, and classification. Understanding what makes humans perceive an image as complex is also a long-standing question in cognitive science. Recent approaches have leveraged multimodal models that combine visual and linguistic representations, but it remains unclear whether language information is necessary for this task. We propose DReX (DINO-ResNet Fusion), a vision-only model that fuses self-supervised and convolutional representations through a learnable attention mechanism to predict image complexity. Our architecture integrates multi-scale hierarchical features from ResNet-50 with semantically rich representations from DINOv3 ViT-S/16, enabling the model to capture both low-level texture patterns and high-level semantic structure. DReX achieves state-of-the-art performance on the IC9600 benchmark (Pearson r = 0.9581), surpassing previous methods--including those trained on multimodal image-text data--while using approximately 21.5x fewer learnable parameters. Furthermore, DReX generalizes robustly across multiple datasets and metrics, achieving superior results on Pearson and Spearman correlation, Root Mean Square Error (RMSE), and Mean Absolute Error (MAE). Ablation and attention analyses confirm that DReX leverages complementary cues from both backbones, with the DINOv3 [CLS] token enhancing sensitivity to visual complexity. Our findings suggest that visual features alone can be sufficient for human-aligned complexity prediction and that, when properly fused, self-supervised transformers and supervised deep convolutional neural networks offer complementary and synergistic benefits for this task.