Closing the Gap: Data-Centric Fine-Tuning of Vision Language Models for the Standardized Exam Questions
作者: Egemen Sert, Şeyda Ertekin
分类: cs.CV, cs.AI, cs.CL, cs.CY
发布日期: 2025-11-14
💡 一句话要点
提出数据驱动的视觉语言模型微调方法,提升标准化考试问题解答能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态推理 数据驱动 监督微调 标准化考试 教育应用 课程对齐
📋 核心要点
- 现有视觉语言模型在标准化考试问题解答中,数据层面的研究较少,高质量数据集的构建和利用存在挑战。
- 论文提出一种数据驱动的微调方法,通过构建高质量多模态数据集和优化推理语法,提升模型性能。
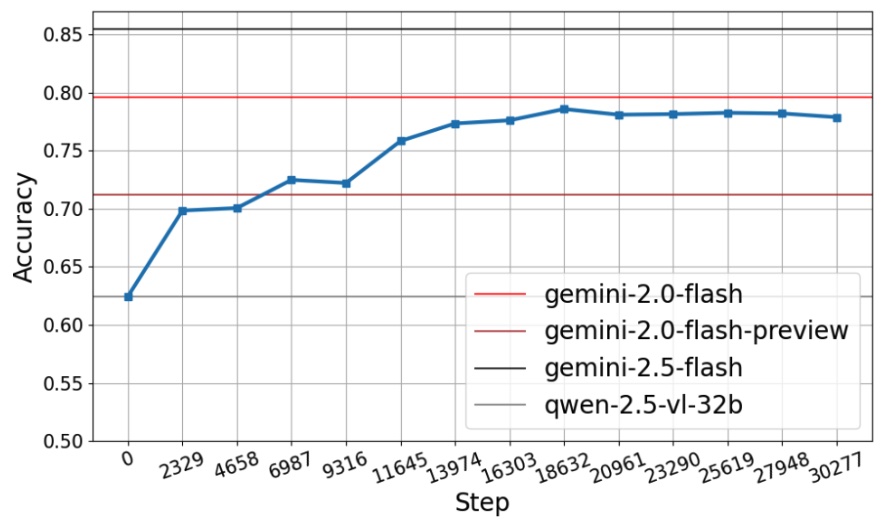
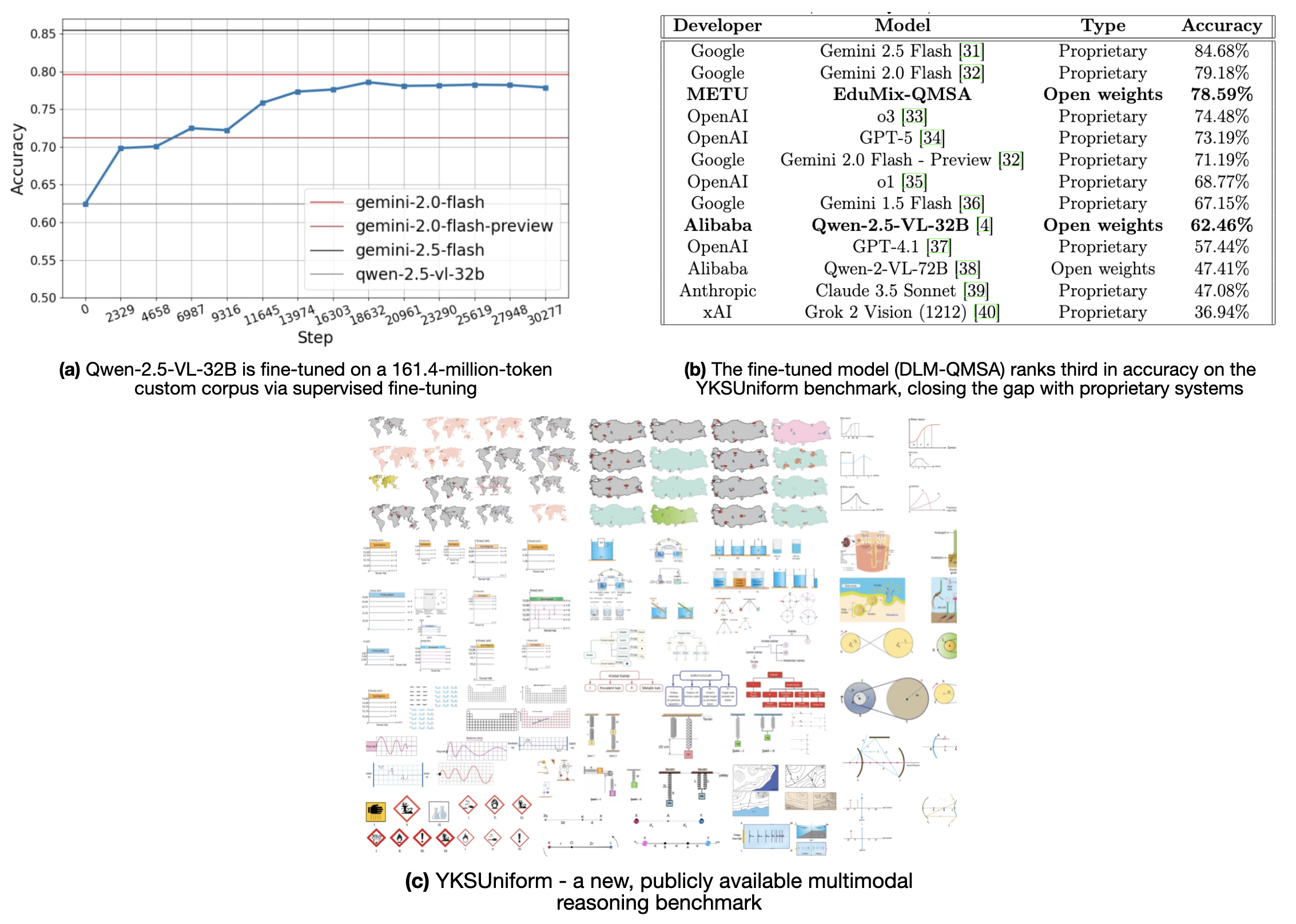
- 实验表明,使用该方法微调的Qwen-2.5VL-32B模型在YKSUniform基准上取得了接近Gemini 2.0 Flash的性能。
📝 摘要(中文)
多模态推理已成为现代人工智能研究的基石。标准化考试问题为这种推理提供了一个独特的、严格的测试平台,它提供了结构化的视觉上下文和可验证的答案。虽然最近的进展主要集中在强化学习等算法进步上,但视觉语言推理的数据中心基础仍然较少被探索。我们表明,使用高质量数据进行监督微调可以与专有方法相媲美。为此,我们编译了一个包含1.614亿token的多模态数据集,结合了教科书问题-解答对、课程对齐的图表和上下文材料,并使用优化的推理语法(QMSA)对Qwen-2.5VL-32B进行微调。由此产生的模型在我们的新发布的基准YKSUniform上达到了78.6%的准确率,仅比Gemini 2.0 Flash低1.0%,该基准统一了309个课程主题的1854个多模态考试问题。我们的结果表明,数据组成和表征语法在多模态推理中起着决定性的作用。这项工作建立了一个以数据为中心的框架,用于推进开放权重视觉语言模型,表明精心策划和基于课程的多模态数据可以将监督微调提升到接近最先进的性能。
🔬 方法详解
问题定义:论文旨在提升视觉语言模型在标准化考试问题上的解答能力。现有方法主要集中在算法层面,忽略了数据质量的重要性。缺乏高质量、大规模、与课程对齐的多模态数据集,限制了监督微调的潜力。
核心思路:论文的核心思路是通过构建高质量的多模态数据集,并结合优化的推理语法,来提升视觉语言模型的性能。作者认为,数据质量和表征方式对于多模态推理至关重要,精心策划的数据可以使监督微调达到接近SOTA的水平。
技术框架:整体框架包括数据收集与构建、模型微调和性能评估三个主要阶段。首先,收集教科书问题-解答对、课程对齐的图表和上下文材料,构建大规模多模态数据集。然后,使用优化的推理语法(QMSA)对Qwen-2.5VL-32B进行监督微调。最后,在YKSUniform基准上评估模型的性能。
关键创新:论文的关键创新在于强调了数据在视觉语言模型训练中的重要性,并提出了一种数据驱动的微调方法。与以往侧重算法改进的研究不同,该论文专注于构建高质量的多模态数据集,并结合优化的推理语法,从而显著提升了模型性能。
关键设计:数据集包含1.614亿token,涵盖教科书问题-解答对、课程对齐的图表和上下文材料。推理语法(QMSA)的具体形式未知,但强调了其对模型推理能力的重要性。模型选择Qwen-2.5VL-32B,并使用监督微调方法进行训练。损失函数和网络结构等细节未明确说明,属于Qwen-2.5VL-32B模型本身的参数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用该方法微调的Qwen-2.5VL-32B模型在YKSUniform基准上达到了78.6%的准确率,仅比Gemini 2.0 Flash低1.0%。这表明,通过精心策划和基于课程的多模态数据,监督微调可以达到接近最先进的性能,验证了数据驱动方法在视觉语言模型训练中的有效性。
🎯 应用场景
该研究成果可应用于教育领域,例如智能辅导系统、在线教育平台等,帮助学生更好地理解和解答标准化考试问题。此外,该方法也可推广到其他需要多模态推理的场景,例如智能客服、图像检索等,具有广泛的应用前景。
📄 摘要(原文)
Multimodal reasoning has become a cornerstone of modern AI research. Standardized exam questions offer a uniquely rigorous testbed for such reasoning, providing structured visual contexts and verifiable answers. While recent progress has largely focused on algorithmic advances such as reinforcement learning (e.g., GRPO, DPO), the data centric foundations of vision language reasoning remain less explored. We show that supervised fine-tuning (SFT) with high-quality data can rival proprietary approaches. To this end, we compile a 161.4 million token multimodal dataset combining textbook question-solution pairs, curriculum aligned diagrams, and contextual materials, and fine-tune Qwen-2.5VL-32B using an optimized reasoning syntax (QMSA). The resulting model achieves 78.6% accuracy, only 1.0% below Gemini 2.0 Flash, on our newly released benchmark YKSUniform, which standardizes 1,854 multimodal exam questions across 309 curriculum topics. Our results reveal that data composition and representational syntax play a decisive role in multimodal reasoning. This work establishes a data centric framework for advancing open weight vision language models, demonstrating that carefully curated and curriculum-grounded multimodal data can elevate supervised fine-tuning to near state-of-the-art performance.