Enhancing XR Auditory Realism via Multimodal Scene-Aware Acoustic Rendering
作者: Tianyu Xu, Jihan Li, Penghe Zu, Pranav Sahay, Maruchi Kim, Jack Obeng-Marnu, Farley Miller, Xun Qian, Katrina Passarella, Mahitha Rachumalla, Rajeev Nongpiur, D. Shin
分类: cs.HC, cs.CV, cs.LG, cs.SD
发布日期: 2025-11-14
期刊: Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST '25), Article 17, 1-16, 2025
💡 一句话要点
提出SAMOSA,通过多模态场景感知声学渲染增强XR听觉真实感
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: XR 空间音频 声学渲染 多模态融合 场景感知 房间脉冲响应 设备端系统
📋 核心要点
- 现有XR空间音频渲染方法难以实时适应物理场景,导致视听感知不匹配,影响用户沉浸感。
- SAMOSA系统融合房间几何、材料和语义信息,构建多模态场景表示,实现高效声学校准。
- 实验结果表明,SAMOSA能有效合成逼真的房间脉冲响应,显著提升XR听觉体验的真实感。
📝 摘要(中文)
在扩展现实(XR)中,准确模拟真实世界声学的声音渲染对于创造逼真且可信的虚拟体验至关重要。然而,现有的XR空间音频渲染方法通常难以实时适应不同的物理场景,导致视觉和听觉线索之间的感官不匹配,从而破坏用户的沉浸感。为了解决这个问题,我们介绍了一种新颖的设备端系统SAMOSA,它通过动态适应物理环境来渲染空间上精确的声音。SAMOSA通过融合房间几何形状、表面材料和语义驱动的声学上下文的实时估计,利用协同多模态场景表示。这种丰富的表示通过场景先验实现高效的声学校准,从而使系统能够合成高度逼真的房间脉冲响应(RIR)。我们通过使用声学指标对各种房间配置和声音类型的RIR合成进行技术评估,以及专家评估(N=12)来验证我们的系统。评估结果表明SAMOSA在增强XR听觉真实感方面的可行性和有效性。
🔬 方法详解
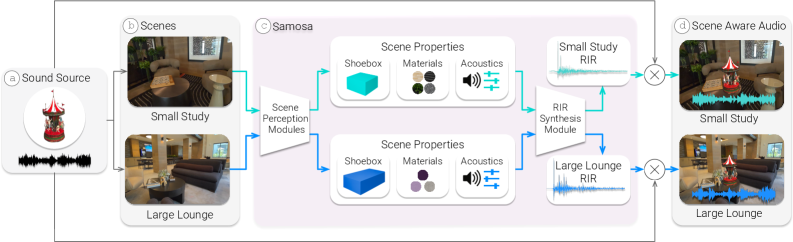
问题定义:现有XR空间音频渲染方法无法根据物理环境的改变进行实时调整,导致渲染的声音与用户看到的场景不匹配,从而降低了XR体验的沉浸感。这些方法通常依赖于预先计算好的声学模型或简化的几何表示,无法捕捉真实世界中复杂声学环境的动态变化。
核心思路:SAMOSA的核心思路是利用多模态信息融合,构建对物理环境的全面理解,并基于此进行动态声学渲染。通过实时感知房间的几何形状、表面材料和语义信息,SAMOSA能够更准确地估计房间的声学特性,并生成更逼真的房间脉冲响应。这种方法的核心在于将视觉信息与声学信息相结合,从而实现更自然的XR体验。
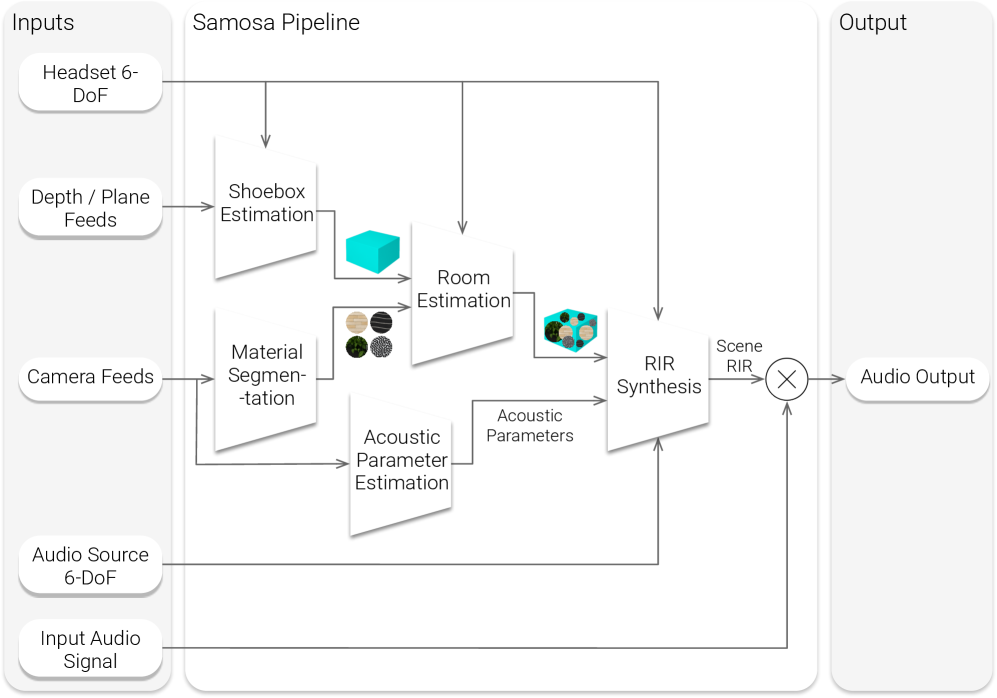
技术框架:SAMOSA系统包含以下主要模块:1) 多模态场景感知模块:该模块负责实时估计房间的几何形状、表面材料和语义信息。这可以通过使用深度摄像头、图像识别算法和语义分割技术来实现。2) 声学校准模块:该模块利用场景感知模块提供的先验信息,对声学模型进行校准。这可以通过使用机器学习算法或基于物理的声学建模方法来实现。3) 房间脉冲响应合成模块:该模块基于校准后的声学模型,合成房间脉冲响应。这可以通过使用卷积混响或其他声学渲染技术来实现。
关键创新:SAMOSA的关键创新在于其多模态场景感知和动态声学校准能力。与传统的XR音频渲染方法相比,SAMOSA能够更准确地捕捉真实世界中复杂声学环境的动态变化,并生成更逼真的声音。此外,SAMOSA的设备端实现使其能够实时适应用户的移动和环境的变化,从而提供更具沉浸感的XR体验。
关键设计:SAMOSA的关键设计包括:1) 使用深度学习模型进行表面材料识别和语义分割,以提高场景感知的准确性。2) 设计了一种基于场景先验的声学校准算法,以提高声学模型的准确性。3) 优化了房间脉冲响应合成算法,以实现实时渲染。
🖼️ 关键图片

📊 实验亮点
论文通过技术评估和专家评估验证了SAMOSA的有效性。技术评估表明,SAMOSA在各种房间配置和声音类型下,能够合成高质量的房间脉冲响应。专家评估(N=12)表明,与现有方法相比,SAMOSA能够显著提升XR听觉体验的真实感。具体性能数据未知,但评估结果表明SAMOSA具有显著优势。
🎯 应用场景
SAMOSA可广泛应用于各种XR应用场景,例如虚拟现实游戏、远程协作、教育培训和建筑设计。通过提供更逼真的听觉体验,SAMOSA可以显著提升XR应用的沉浸感和实用性。未来,SAMOSA有望与其他XR技术(如视觉渲染和触觉反馈)相结合,创造更具沉浸感和互动性的虚拟体验。
📄 摘要(原文)
In Extended Reality (XR), rendering sound that accurately simulates real-world acoustics is pivotal in creating lifelike and believable virtual experiences. However, existing XR spatial audio rendering methods often struggle with real-time adaptation to diverse physical scenes, causing a sensory mismatch between visual and auditory cues that disrupts user immersion. To address this, we introduce SAMOSA, a novel on-device system that renders spatially accurate sound by dynamically adapting to its physical environment. SAMOSA leverages a synergistic multimodal scene representation by fusing real-time estimations of room geometry, surface materials, and semantic-driven acoustic context. This rich representation then enables efficient acoustic calibration via scene priors, allowing the system to synthesize a highly realistic Room Impulse Response (RIR). We validate our system through technical evaluation using acoustic metrics for RIR synthesis across various room configurations and sound types, alongside an expert evaluation (N=12). Evaluation results demonstrate SAMOSA's feasibility and efficacy in enhancing XR auditory realism.