Seeing the Forest and the Trees: Query-Aware Tokenizer for Long-Video Multimodal Language Models
作者: Siyou Li, Huanan Wu, Juexi Shao, Yinghao Ma, Yujian Gan, Yihao Luo, Yuwei Wang, Dong Nie, Lu Wang, Wengqing Wu, Le Zhang, Massimo Poesio, Juntao Yu
分类: cs.CV
发布日期: 2025-11-14 (更新: 2025-11-21)
💡 一句话要点
提出QTSplus以解决长视频理解中的视觉信息选择问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 查询感知 视觉标记选择 多模态大语言模型 计算效率 信息选择
📋 核心要点
- 长视频理解面临视觉标记数量随视频长度增加而导致的计算资源消耗问题。
- 提出的QTSplus模块通过动态选择重要视觉信息,优化了视觉标记的处理效率。
- 实验结果表明,QTSplus在长视频理解任务中显著提升了性能,减少了延迟和计算成本。
📝 摘要(中文)
尽管多模态大语言模型(MLLMs)在视频理解方面取得了进展,但长视频理解仍然面临挑战。主要问题在于视觉标记数量随视频长度线性增长,导致注意力成本、内存和延迟的爆炸性增加。为了解决这一挑战,本文提出了查询感知标记选择器(QTSplus),它作为视觉编码器与LLMs之间的信息门。QTSplus通过跨注意力评分视觉标记、基于查询复杂性预测实例特定的保留预算,并在训练期间使用可微分的直通估计器选择Top-n标记,在推理时使用硬门。此外,QTSplus通过小型重编码器保留时间顺序,利用绝对时间信息实现二级定位,同时保持全局覆盖。集成到Qwen2.5-VL中,QTSplus在长视频上压缩视觉流达89%,并减少端到端延迟28%。在八个长视频理解基准上的评估显示,与原始Qwen模型相比,整体准确性几乎持平,并在TempCompass方向和顺序准确性上分别提升了20.5和5.6个百分点。
🔬 方法详解
问题定义:本文旨在解决长视频理解中视觉信息选择的效率问题。现有方法在处理长视频时,视觉标记数量的线性增长导致计算资源消耗过大,影响模型的实时性和准确性。
核心思路:QTSplus通过查询感知的方式,动态选择与输入文本查询最相关的视觉标记,从而减少不必要的信息处理。该设计旨在提高长视频理解的效率和准确性。
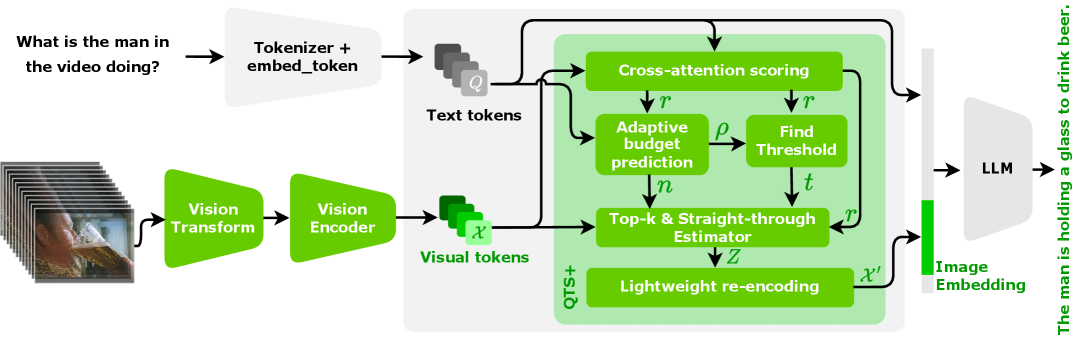
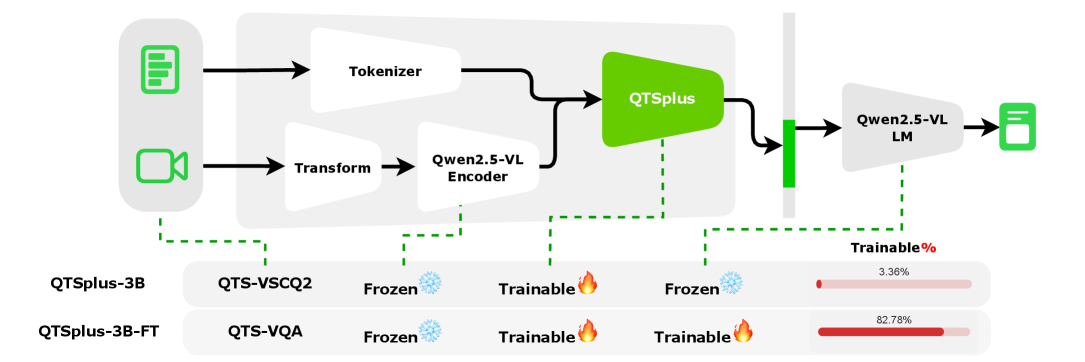
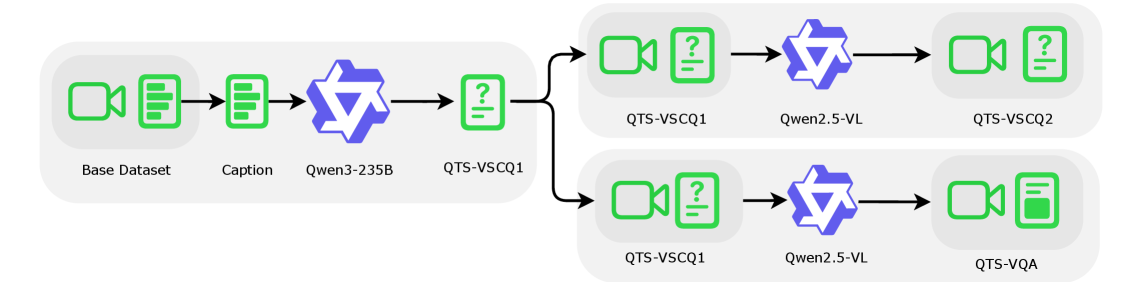
技术框架:QTSplus的整体架构包括三个主要模块:视觉标记评分模块、保留预算预测模块和Top-n标记选择模块。评分模块通过跨注意力机制对视觉标记进行打分,预测模块根据查询复杂性动态调整保留预算,选择模块则在训练和推理阶段采用不同的策略进行标记选择。
关键创新:QTSplus的核心创新在于其动态选择机制和实例特定的保留预算预测。这一机制使得模型能够在处理长视频时,保持任务相关的信息,同时显著降低计算负担。
关键设计:在设计中,QTSplus采用了可微分的直通估计器以实现训练期间的高效标记选择,并在推理时使用硬门以确保选择的稳定性。此外,小型重编码器的引入使得模型能够保留时间顺序信息,增强了对视频内容的理解能力。
🖼️ 关键图片
📊 实验亮点
实验结果显示,QTSplus在长视频理解任务中将视觉流压缩达89%,并减少了28%的端到端延迟。同时,在TempCompass方向和顺序准确性上,QTSplus分别提升了20.5和5.6个百分点,展示了其在长视频处理中的显著优势。
🎯 应用场景
该研究的潜在应用领域包括视频监控、在线教育、娱乐内容分析等长视频理解场景。通过提升长视频的理解能力,QTSplus能够为多模态交互系统提供更准确的视觉信息支持,推动智能助手、自动摘要生成等技术的发展。未来,该技术可能在实时视频分析和人机交互中发挥重要作用。
📄 摘要(原文)
Despite the recent advances in the video understanding ability of multimodal large language models (MLLMs), long video understanding remains a challenge. One of the main issues is that the number of vision tokens grows linearly with video length, which causes an explosion in attention cost, memory, and latency. To solve this challenge, we present Query-aware Token Selector (\textbf{QTSplus}), a lightweight yet powerful visual token selection module that serves as an information gate between the vision encoder and LLMs. Given a text query and video tokens, QTSplus dynamically selects the most important visual evidence for the input text query by (i) scoring visual tokens via cross-attention, (ii) \emph{predicting} an instance-specific retention budget based on the complexity of the query, and (iii) \emph{selecting} Top-$n$ tokens with a differentiable straight-through estimator during training and a hard gate at inference. Furthermore, a small re-encoder preserves temporal order using absolute time information, enabling second-level localization while maintaining global coverage. Integrated into Qwen2.5-VL, QTSplus compresses the vision stream by up to \textbf{89\%} and reduces end-to-end latency by \textbf{28\%} on long videos. The evaluation on eight long video understanding benchmarks shows near-parity accuracy overall when compared with the original Qwen models and outperforms the original model by \textbf{+20.5} and \textbf{+5.6} points respectively on TempCompass direction and order accuracies. These results show that QTSplus is an effective, general mechanism for scaling MLLMs to real-world long-video scenarios while preserving task-relevant evidence.