SOTFormer: A Minimal Transformer for Unified Object Tracking and Trajectory Prediction
作者: Zhongping Dong, Pengyang Yu, Shuangjian Li, Liming Chen, Mohand Tahar Kechadi
分类: cs.CV
发布日期: 2025-11-14
💡 一句话要点
SOTFormer:一种极简Transformer,用于统一目标跟踪和轨迹预测
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 单目标跟踪 轨迹预测 Transformer 时间注意力 目标检测
📋 核心要点
- 现有单目标跟踪和轨迹预测方法在遮挡、尺度变化等复杂场景下,难以维持时间连贯性,影响实时感知。
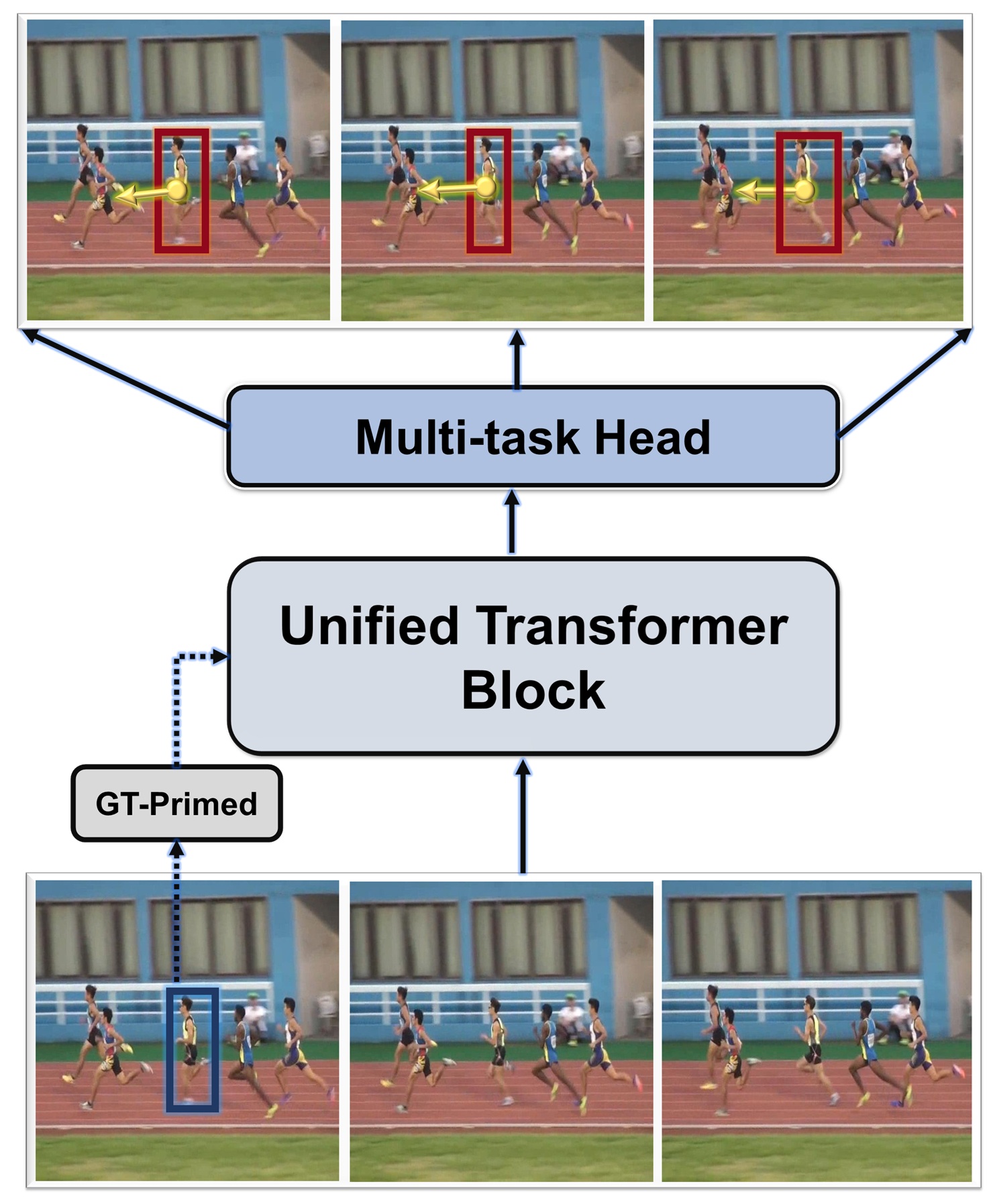
- SOTFormer通过ground-truth引导的内存和burn-in anchor损失,稳定初始化并实现身份传播,提升跟踪性能。
- SOTFormer在Mini-LaSOT数据集上取得了76.3 AUC和53.7 FPS的优异成绩,超越了现有Transformer基线方法。
📝 摘要(中文)
在遮挡、尺度变化和时间漂移等情况下,精确的单目标跟踪和短期运动预测仍然具有挑战性,这些因素会破坏实时感知所需的时间连贯性。我们提出了SOTFormer,一种极简的恒定内存时间Transformer,它在一个端到端框架内统一了目标检测、跟踪和短时程轨迹预测。与具有循环或堆叠时间编码器的先前模型不同,SOTFormer通过ground-truth引导的内存和显式稳定初始化的burn-in anchor损失来实现稳定的身份传播。单个轻量级时间注意力层细化了跨帧的嵌入,从而能够以固定的GPU内存进行实时推理。在Mini-LaSOT(20%)基准测试中,SOTFormer达到了76.3 AUC和53.7 FPS(AMP,4.3 GB VRAM),在快速运动、尺度变化和遮挡下优于TrackFormer和MOTRv2等Transformer基线。
🔬 方法详解
问题定义:论文旨在解决单目标跟踪和短期轨迹预测在复杂场景下(如遮挡、尺度变化)的鲁棒性问题。现有方法,特别是基于循环神经网络或堆叠Transformer编码器的方法,在处理长时间序列时容易出现梯度消失或爆炸,难以维持时间一致性,并且计算复杂度较高,难以满足实时性需求。
核心思路:论文的核心思路是设计一个极简的、恒定内存的时间Transformer(SOTFormer),通过ground-truth引导的内存和burn-in anchor损失来稳定初始化,从而实现更鲁棒的身份传播和更高效的计算。这种设计旨在减少对复杂时间编码器的依赖,并提高模型在复杂场景下的跟踪和预测性能。
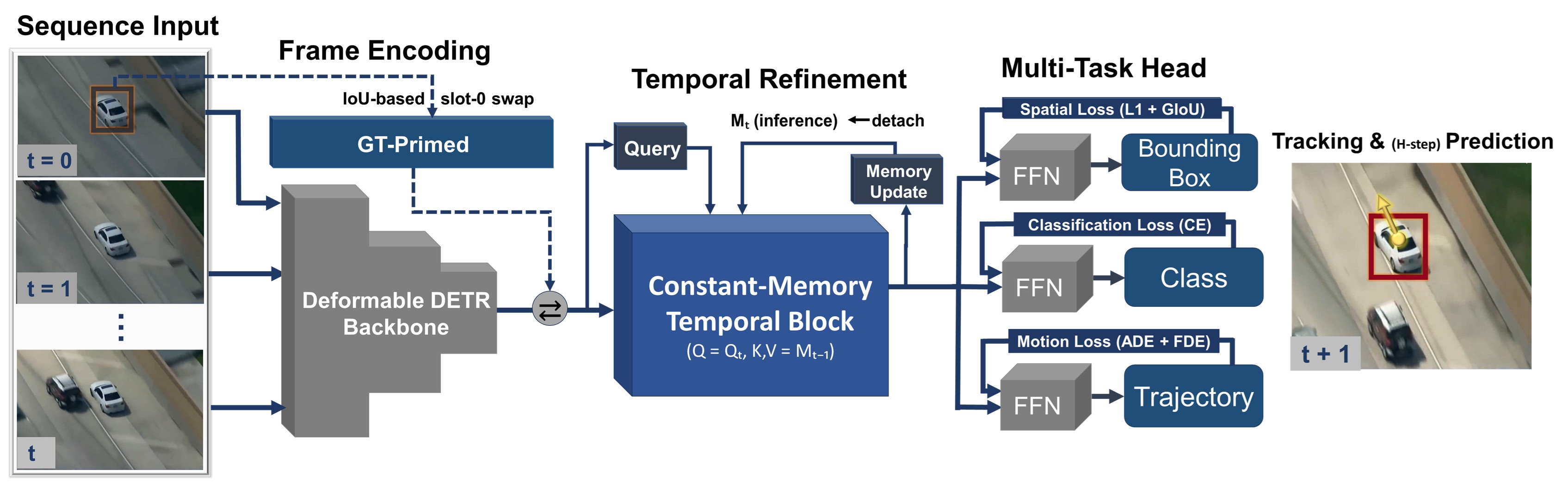
技术框架:SOTFormer是一个端到端的框架,它统一了目标检测、跟踪和短时程轨迹预测。其主要模块包括:1) 特征提取网络(用于提取图像特征);2) ground-truth引导的内存模块(用于存储和更新目标的状态信息);3) 轻量级时间注意力层(用于跨帧细化嵌入);4) 预测头(用于输出目标的位置和轨迹)。整个流程是:输入视频帧,提取特征,利用ground-truth信息初始化内存,通过时间注意力层进行信息融合,最后预测目标的位置和轨迹。
关键创新:SOTFormer的关键创新在于其极简的设计和ground-truth引导的内存机制。与传统的循环或堆叠Transformer编码器不同,SOTFormer只使用一个轻量级的时间注意力层,大大降低了计算复杂度。同时,ground-truth引导的内存模块可以有效地稳定初始化,并促进身份传播,从而提高跟踪的鲁棒性。此外,burn-in anchor损失显式地稳定了初始化过程,进一步提升了性能。
关键设计:SOTFormer的关键设计包括:1) 使用单个轻量级时间注意力层,减少计算量;2) ground-truth引导的内存模块,利用真实标签信息初始化内存,提高跟踪精度;3) burn-in anchor损失,在训练初期稳定初始化,避免模型陷入局部最优;4) 恒定内存设计,保证实时推理的效率。具体的参数设置和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
SOTFormer在Mini-LaSOT(20%)基准测试中取得了显著的成果,AUC达到了76.3,并且实现了53.7 FPS的实时推理速度(AMP,4.3 GB VRAM)。与TrackFormer和MOTRv2等Transformer基线方法相比,SOTFormer在快速运动、尺度变化和遮挡等复杂场景下表现出更强的鲁棒性,性能显著提升。这些实验结果表明,SOTFormer的极简设计和ground-truth引导的内存机制是有效的。
🎯 应用场景
SOTFormer具有广泛的应用前景,例如智能监控、自动驾驶、机器人导航、视频分析等领域。在智能监控中,它可以用于跟踪特定目标,例如嫌疑人或车辆。在自动驾驶中,它可以用于跟踪车辆、行人和其他障碍物,从而提高驾驶安全性。在机器人导航中,它可以用于跟踪目标物体,例如操作对象或跟随人员。该研究的实际价值在于提高了目标跟踪和轨迹预测的准确性和效率,为相关应用提供了更可靠的技术支持。未来,SOTFormer可以进一步扩展到多目标跟踪、长期轨迹预测等更复杂的场景。
📄 摘要(原文)
Accurate single-object tracking and short-term motion forecasting remain challenging under occlusion, scale variation, and temporal drift, which disrupt the temporal coherence required for real-time perception. We introduce \textbf{SOTFormer}, a minimal constant-memory temporal transformer that unifies object detection, tracking, and short-horizon trajectory prediction within a single end-to-end framework. Unlike prior models with recurrent or stacked temporal encoders, SOTFormer achieves stable identity propagation through a ground-truth-primed memory and a burn-in anchor loss that explicitly stabilizes initialization. A single lightweight temporal-attention layer refines embeddings across frames, enabling real-time inference with fixed GPU memory. On the Mini-LaSOT (20%) benchmark, SOTFormer attains 76.3 AUC and 53.7 FPS (AMP, 4.3 GB VRAM), outperforming transformer baselines such as TrackFormer and MOTRv2 under fast motion, scale change, and occlusion.