OpenUS: A Fully Open-Source Foundation Model for Ultrasound Image Analysis via Self-Adaptive Masked Contrastive Learning
作者: Xiaoyu Zheng, Xu Chen, Awais Rauf, Qifan Fu, Benedetta Monosi, Felice Rivellese, Myles J. Lewis, Shaogang Gong, Gregory Slabaugh
分类: cs.CV
发布日期: 2025-11-14
🔗 代码/项目: GITHUB
💡 一句话要点
OpenUS:首个全开源超声图像分析基础模型,采用自适应掩码对比学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超声图像分析 基础模型 自监督学习 对比学习 掩码图像建模 Vision Mamba 自适应掩码
📋 核心要点
- 超声图像判读依赖操作者,且受解剖区域、采集协议和设备类型影响大,通用性差,标注数据有限。
- 提出OpenUS,一个基于Vision Mamba骨干网络和自适应掩码对比学习的开源超声基础模型。
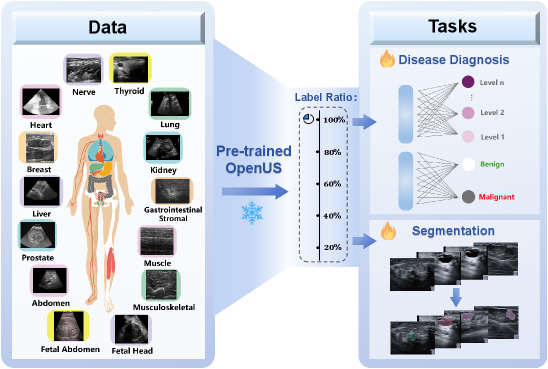
- 构建包含超过30.8万张图像的超声数据集,预训练模型可作为骨干网络高效微调至下游任务。
📝 摘要(中文)
超声(US)成像因其低成本、便携性、实时反馈和无电离辐射等优点而被广泛应用于医学成像。然而,超声图像的判读高度依赖操作者,并且在不同的解剖区域、采集协议和设备类型之间存在显著差异。这些差异,以及诸如散斑、低对比度和有限的标准化标注等独特挑战,阻碍了通用、标签高效的超声AI模型的发展。本文提出了OpenUS,这是第一个可复现的、基于大型公共数据集构建的开源超声基础模型。OpenUS采用Vision Mamba作为骨干网络,捕捉图像中的局部和全局长程依赖关系。为了在预训练期间提取丰富的特征,我们引入了一种新颖的自适应掩码框架,该框架将对比学习与掩码图像建模相结合。该策略将教师网络的注意力图与学生网络的重建损失相结合,自适应地细化临床相关的掩码,从而提高预训练的有效性。OpenUS还应用动态学习策略来逐步调整预训练过程的难度。为了开发该基础模型,我们整理了迄今为止最大的公共超声数据集,包含来自42个公开数据集的超过30.8万张图像,涵盖了不同的解剖区域、机构、成像设备和疾病类型。我们预训练的OpenUS模型可以通过作为标签高效微调的骨干网络轻松地适应特定的下游任务。
🔬 方法详解
问题定义:超声图像分析面临着操作者依赖性强、图像质量差异大、标注数据稀缺等问题,导致现有AI模型泛化能力不足。现有方法难以有效利用未标注数据进行预训练,从而限制了模型在下游任务中的表现。
核心思路:论文的核心思路是利用大规模公开超声数据集,通过自监督学习的方式预训练一个通用的超声基础模型。该模型能够学习到超声图像的通用特征表示,从而可以高效地迁移到各种下游任务中。自适应掩码对比学习旨在更好地利用图像信息,提升预训练效果。
技术框架:OpenUS的整体框架包括数据收集与整理、预训练和下游任务微调三个阶段。首先,收集并整理大规模的公开超声数据集。然后,使用Vision Mamba作为骨干网络,并结合自适应掩码对比学习策略进行预训练。最后,将预训练好的模型作为骨干网络,在特定的下游任务上进行微调。
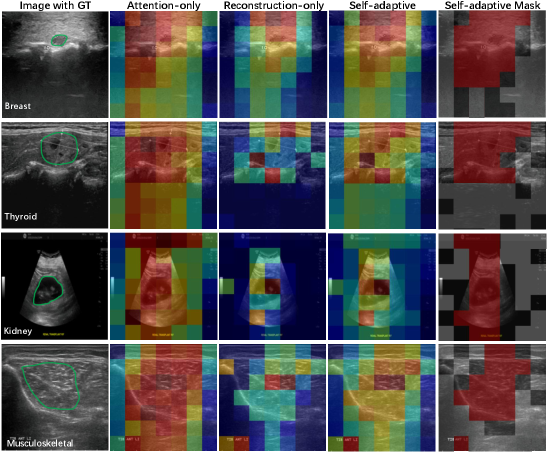
关键创新:论文的关键创新在于提出了自适应掩码对比学习框架。该框架结合了对比学习和掩码图像建模的优点,利用教师网络的注意力图指导学生网络的掩码策略,从而使模型能够更加关注临床相关的区域,并学习到更具判别性的特征表示。
关键设计:自适应掩码策略的关键在于利用教师网络的注意力图来指导学生网络的掩码。具体来说,首先利用教师网络提取图像的注意力图,然后根据注意力图的权重,对图像进行掩码。注意力权重高的区域被掩码的概率较低,而注意力权重低的区域被掩码的概率较高。此外,论文还采用了动态学习率调整策略,以逐步提高预训练的难度。
🖼️ 关键图片

📊 实验亮点
论文构建了迄今为止最大的公共超声数据集,包含超过30.8万张图像。提出的OpenUS模型在多个下游任务上取得了有竞争力的结果,证明了其有效性和泛化能力。自适应掩码对比学习策略显著提升了预训练效果。
🎯 应用场景
OpenUS可应用于多种超声图像分析任务,如器官分割、病灶检测、疾病诊断等。该研究有助于降低超声AI模型的开发成本,提高模型的泛化能力和临床应用价值,促进超声医学影像分析的自动化和智能化。
📄 摘要(原文)
Ultrasound (US) is one of the most widely used medical imaging modalities, thanks to its low cost, portability, real-time feedback, and absence of ionizing radiation. However, US image interpretation remains highly operator-dependent and varies significantly across anatomical regions, acquisition protocols, and device types. These variations, along with unique challenges such as speckle, low contrast, and limited standardized annotations, hinder the development of generalizable, label-efficient ultrasound AI models. In this paper, we propose OpenUS, the first reproducible, open-source ultrasound foundation model built on a large collection of public data. OpenUS employs a vision Mamba backbone, capturing both local and global long-range dependencies across the image. To extract rich features during pre-training, we introduce a novel self-adaptive masking framework that combines contrastive learning with masked image modeling. This strategy integrates the teacher's attention map with student reconstruction loss, adaptively refining clinically-relevant masking to enhance pre-training effectiveness. OpenUS also applies a dynamic learning schedule to progressively adjust the difficulty of the pre-training process. To develop the foundation model, we compile the largest to-date public ultrasound dataset comprising over 308K images from 42 publicly available datasets, covering diverse anatomical regions, institutions, imaging devices, and disease types. Our pre-trained OpenUS model can be easily adapted to specific downstream tasks by serving as a backbone for label-efficient fine-tuning. Code is available at https://github.com/XZheng0427/OpenUS.