VP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
作者: Mingjie Xu, Jinpeng Chen, Yuzhi Zhao, Jason Chun Lok Li, Yue Qiu, Zekang Du, Mengyang Wu, Pingping Zhang, Kun Li, Hongzheng Yang, Wenao Ma, Jiaheng Wei, Qinbin Li, Kangcheng Liu, Wenqiang Lei
分类: cs.CV
发布日期: 2025-11-14
备注: This is the extended version of the paper accepted at AAAI 2026, which includes all technical appendices and additional experimental details
💡 一句话要点
VP-Bench:多模态大语言模型中视觉提示理解能力的综合评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉提示 基准测试 视觉-语言理解 模型评估
📋 核心要点
- 现有MLLM缺乏对视觉提示(VP)的系统评估,无法确定其是否能有效理解和利用VP解决问题。
- 提出VP-Bench基准,通过两阶段评估框架,全面评估MLLM对VP的感知和利用能力。
- 评估了28个MLLM,分析了VP属性、问题安排和模型规模等因素对VP理解的影响,为后续研究提供参考。
📝 摘要(中文)
多模态大语言模型(MLLMs)已经实现了广泛的视觉-语言应用,包括细粒度的物体识别和上下文理解。在查询图像中的特定区域或物体时,人类用户自然地使用“视觉提示”(VP),例如边界框,来提供参考。然而,目前还没有基准系统地评估MLLMs解释此类VP的能力。这种差距使得我们不清楚当前的MLLMs是否能够有效地识别VP(一种对人类来说很直观的提示方法),并利用它们来解决问题。为了解决这个限制,我们引入了VP-Bench,这是一个用于评估MLLMs在VP感知和利用方面的能力的基准。VP-Bench采用两阶段评估框架:第一阶段检查模型在自然场景中感知VP的能力,使用30k个可视化提示,涵盖八种形状和355种属性组合。第二阶段研究VP对下游任务的影响,衡量它们在真实问题解决场景中的有效性。使用VP-Bench,我们评估了28个MLLMs,包括专有系统(例如,GPT-4o)和开源模型(例如,InternVL3和Qwen2.5-VL),并对影响VP理解的因素进行了全面分析,例如VP属性的变化、问题安排和模型规模。VP-Bench为研究MLLMs如何理解和解决基于视觉提示的指代问题建立了一个新的参考框架。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在理解和利用视觉提示(VP)方面的能力评估问题。现有方法缺乏系统性的基准测试,无法有效衡量MLLMs对VP的感知和利用能力,阻碍了相关研究的进展。现有方法的痛点在于缺乏一个标准化的评估框架,难以对不同MLLMs的VP理解能力进行公平、全面的比较。
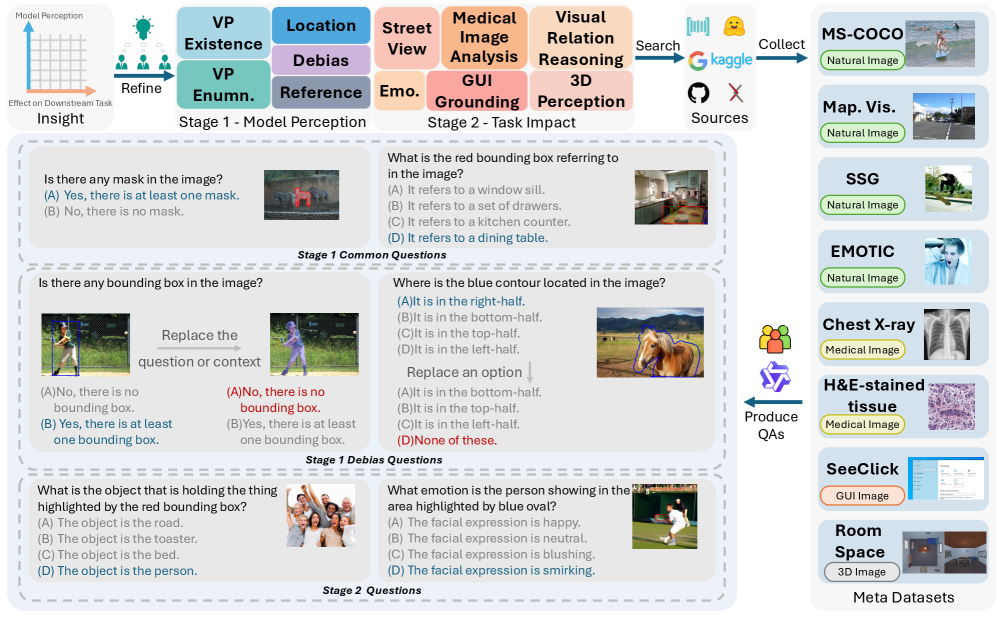
核心思路:论文的核心思路是构建一个全面的基准测试VP-Bench,通过两阶段的评估框架,系统地评估MLLMs对VP的感知和利用能力。第一阶段侧重于VP的感知,第二阶段侧重于VP在下游任务中的应用。通过这种分阶段的评估方式,可以更清晰地了解MLLMs在VP理解方面的优势和不足。
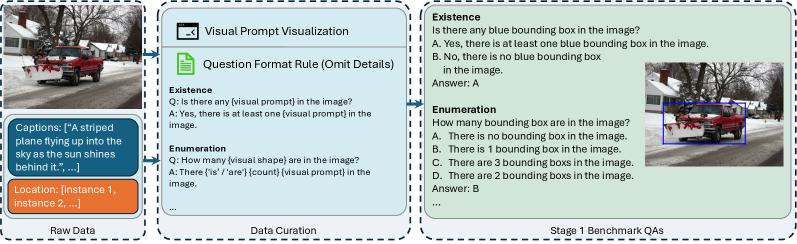
技术框架:VP-Bench包含两个主要阶段:VP感知评估和下游任务评估。VP感知评估阶段使用包含30k个可视化提示的数据集,涵盖八种形状和355种属性组合,用于评估模型在自然场景中感知VP的能力。下游任务评估阶段则衡量VP在真实问题解决场景中的有效性。整个框架旨在全面评估MLLMs对VP的理解和应用能力。
关键创新:VP-Bench的关键创新在于其系统性和全面性。它首次提出了一个专门针对MLLMs视觉提示理解能力的基准测试,并设计了一个两阶段的评估框架,可以更细致地评估模型的VP感知和利用能力。与现有方法相比,VP-Bench提供了更全面的评估指标和更丰富的数据集,可以更准确地反映MLLMs在VP理解方面的真实水平。
关键设计:VP-Bench的数据集包含多种形状和属性组合的视觉提示,以覆盖不同的VP场景。评估指标包括VP感知准确率和下游任务的性能指标。在下游任务评估中,论文考虑了不同的问题安排方式,以评估模型对上下文信息的利用能力。此外,论文还分析了模型规模对VP理解能力的影响。
🖼️ 关键图片

📊 实验亮点
VP-Bench评估了28个MLLMs,包括GPT-4o、InternVL3和Qwen2.5-VL等。实验结果表明,不同模型在VP感知和利用方面存在显著差异。通过分析VP属性、问题安排和模型规模等因素对VP理解的影响,为后续研究提供了重要的参考依据。该基准测试为提升MLLMs的视觉提示理解能力奠定了基础。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型在图像理解、目标定位、视觉问答等领域的性能。通过VP-Bench,可以更好地评估和改进MLLMs对视觉提示的理解能力,从而实现更智能、更人性化的视觉-语言交互应用,例如智能客服、图像编辑、机器人导航等。
📄 摘要(原文)
Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.